- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
Une fonction a la forme de
(opérateur arg1 arg2 ... argn)
c'est-à-dire le symbole d'opération, paramètre 1, paramètre 2, jusqu'au paramètre n. Le paramètre lui-même peut également être une fonction dans ce format.
Par exemple, une chaîne comme celle-ci
String="(add (add 1 2) (mul 2 1) 2 )"
doit être divisée en ses opérandes et paramètres, c'est-à-dire divisée en
["ajouter","(ajouter 1 2)","(mul 2 1)","2"]
Comment un tel tableau de caractères doit-il être divisé ?
Mon approche actuelle consiste à supprimer les crochets les plus à l'extérieur à chaque fois, puis à utiliser des espaces pour diviser la chaîne, mais les espaces au milieu deviendront également l'endroit à diviser. Si vous utilisez des expressions régulières, puisque chaque paramètre peut toujours contenir des parenthèses imbriquées, comment cette situation doit-elle être adaptée ?
仅有的幸福2017-06-23 09:15:59
前缀表示法, S-表达式,Lisp表达式
lispS-表达式是多层嵌套的树形结构,比较接近抽象语法树(AST).
Regular est difficile à analyser sans grammaire récursiveS-表达式.
Ce qui suit est un exemple simple en python. Je l'ai commenté et il devrait être facile à comprendre.
def parse_sexp(string):
sexp = [[]]
word = ''
in_str = False #是否在读取字符串
for char in string: # 遍历每个字符
if char == '(' and not in_str: # 左括号
sexp.append([])
elif char == ')' and not in_str: # 右括号
if word:
sexp[-1].append(word)
word = ''
temp = sexp.pop()
sexp[-1].append(tuple(temp)) # 形成嵌套
elif char in ' \n\t' and not in_str: # 空白符
if word:
sexp[-1].append(word)
word = ''
elif char == '"': # 双引号,字符串起止的标记
in_str = not in_str
else:
word += char # 不是以上的分隔符,就是个合法的标记
return sexp[0]
>>> parse_sexp("(+ 5 (+ 3 5))")
[('+', '5', ('+', '3', '5'))]
>>> parse_sexp("(add (add 1 2) (mul 2 1) 2 )")
[('add', ('add', '1', '2'), ('mul', '2', '1'), '2')]S-expression

阿神2017-06-23 09:15:59
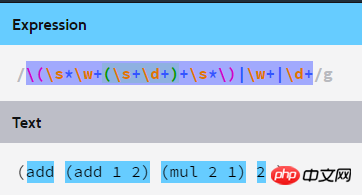
Régulier :
\(\s*\w+(\s+\d+)+\s*\)|\w+|\d+Notez que cette regex a un paramètre Global
S'ilarg1, arg2, arg3, ... argn中嵌套(op arg ...)il n'y a qu'un seul calque, vous pouvez utiliser cette méthode