
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
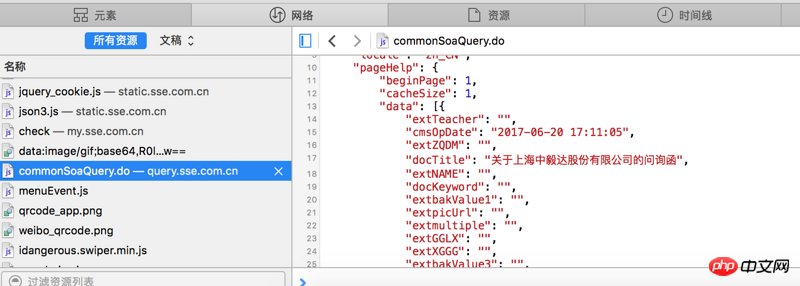
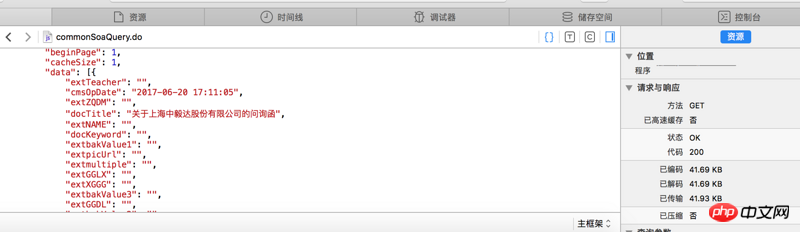
Si vous ne voyez pas clairement, l'adresse du site Web est http://www.sse.com.cn/disclos...
Le texte rouge est le contenu dont j'ai besoin, mais je ne peux pas l'extraire
S'il vous plaît dites-moi comment le faire fonctionner

三叔2017-06-22 11:53:33
import requests
url = 'http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5'
headers = {
'Referer':'http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
r = requests.get(url, headers=headers)
print r.json()['result']
欧阳克2017-06-22 11:53:33
import requests
url = 'http://query.sse.com.cn/commonSoaQuery.do?siteId=28&sqlId=BS_GGLL&extGGLX=&stockcode=&channelId=10743%2C10744%2C10012&extGGDL=&order=createTime%7Cdesc%2Cstockcode%7Casc&isPagination=true&pageHelp.pageSize=15&pageHelp.pageNo=1&pageHelp.beginPage=1&pageHelp.cacheSize=1&pageHelp.endPage=5&_=1498029409382'
session = requests.session()
session.headers.update({
'Referer': 'http://www.sse.com.cn/disclosure/credibility/supervision/inquiries/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
})
result = session.get(url).json()
print result
