
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
J'utilise jupyter d'anaconda pour exécuter le code.
J'utilise le module requests pour lire la page Web 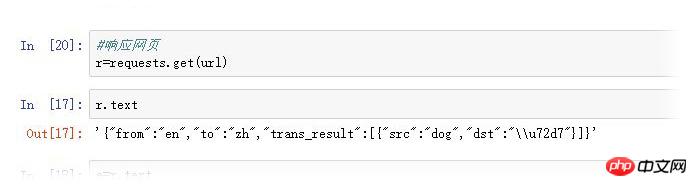
Je vois que le contenu de sortie est entre accolades. , donc j'utilise la fonction de dict pour lire la valeur, mais cela a échoué.  type()
type()
a découvert que son attribut était str Après avoir utilisé json
Après avoir utilisé json
, j'ai découvert que l'attribut était devenu dict.
Lorsque le programme lit ce type de
sous forme de chaînes, comment devrions-nous les reconvertir en attributs de dictionnaire
?
習慣沉默2017-06-12 09:23:24
Veuillez utiliser le bouton d'édition <> pour ajouter du code lorsque vous poserez des questions à l'avenir, afin que d'autres puissent essayer le code.
Essayez le code suivant :
x = eval(r.text)
y = r.json()
print (type(x), type(y))
print (x==y)Le résultat devrait être que les deux dictionnaires ont le même contenu. En d'autres termes :
x = eval(r.text)
y = r.json() x consiste à exécuter la chaîne de r.text directement sous forme d'expressions pour générer un dictionnaire
y est l'objet json renvoyé par la méthode r.json(), qui génère un dictionnaire
Votre question est donc :
"Lorsque le programme lit ce type de contenu de dictionnaire sous forme de chaîne, comment en faire à nouveau un attribut de dictionnaire ?" d'un dictionnaire. Comment transformer une chaîne en dictionnaire ? "
Alors la réponse est la fonction intégrée eval()
Bien sûr, le module de requêtes possède déjà la méthode .json(), vous pouvez l'utiliser


