
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
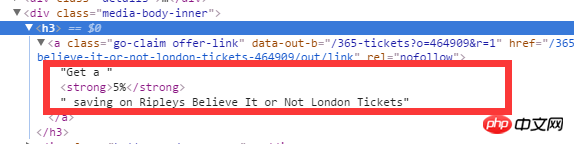
Je souhaite obtenir le contenu complet sous la balise a sous h3 (Obtenez une économie de 5 % sur les billets Ripleys Believe It or Not London). Comment puis-je l'obtenir en utilisant XPath ? Demander l'avis d'un expert

阿神2017-05-24 11:37:18
Le moyen le plus pratique est de le sélectionner et il existe une option pour le copier sur XPath

黄舟2017-05-24 11:37:18
La réponse précédente n'a pas résolu le problème de l'affiche originale, car l'affiche originale ne décrivait pas clairement le problème. Je pense que ce que l'auteur original voulait dire, c'est que vous ne pouvez pas obtenir le contenu de la sous-balise en utilisant directement le texte (. ) méthode ou attribut de texte (en supposant que vous l'ayez déjà vu) La syntaxe de base de XPath).
La recherche Google XPath récupère tout le texte, le premier est la réponse.
L'affiche peut poser cette question : Comment utiliser XPath pour extraire le contenu du texte contenu dans la balise (bien que la réponse ici ne soit pas satisfaisante)
漂亮男人2017-05-24 11:37:18
Vous l'essayez
response.xpath('//h3/a/descendant-or-self::text()[normalize-space()]')
descendant-or-self indique le nœud actuel et les nœuds descendants
normal-space() supprime les nœuds descendants des nœuds contenant uniquement des espaces (c'est facultatif)
Lien de référence :
http://stackoverflow.com/ques...
