- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
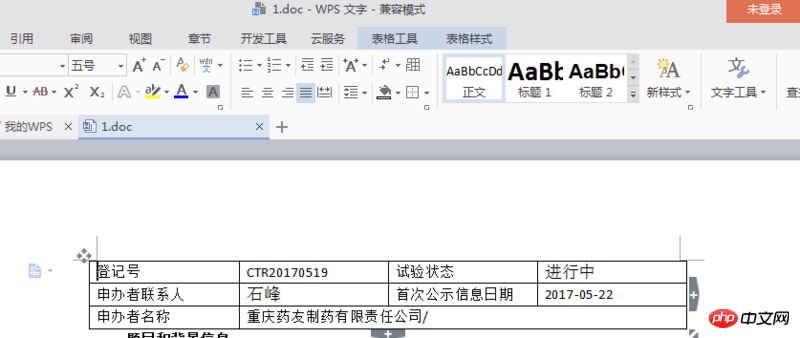
Après avoir cliqué sur le bouton de téléchargement sur la page "http://www.chinadrugtrials.or...", un fichier DOC sera téléchargé. J'espère utiliser Python pour le télécharger automatiquement. Actuellement, le fichier peut être téléchargé, mais. il ne peut pas être ouvert
Personnellement, je pensais qu'il n'était peut-être pas possible d'écrire le contenu obtenu directement dans un fichier ou qu'il s'agissait peut-être d'un problème de redirection, mais après une recherche sur Google, j'ai découvert qu'il n'y avait pas d'autre moyen et qu'il n'y avait rien à gagner à chercher à la documentation
Ce qui suit est une capture d'écran de la page Web et de la déclaration de téléchargement. Pourriez-vous s'il vous plaît m'aider à découvrir ce qui ne va pas, veuillez me donner quelques conseils ? Merci
.[La page Web est la suivante] Si rien ne s'affiche sur la page Web, cliquez simplement sur la requête dans le coin supérieur droit pour obtenir les informations. Pas besoin de vous inscrire ou de vous connecter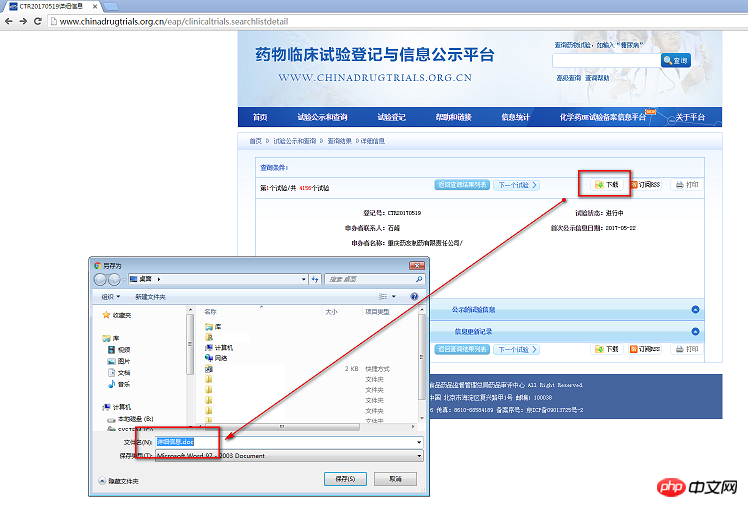
[Le code est le suivant]
import requests
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36'}
url = 'http://www.chinadrugtrials.org.cn/exportdoc/clinicaltrials.searchlistdetail'
data = {'ckm_id': 'eda4593539334baea5f58828360d5dd8',
'ckm_index': 1,
'button2': ''}
ses = requests.session()
get = ses.post(url, headers=header, data=data)
with open('./1.doc', 'wb') as file:
file.write(get.content)
print('Done!')为情所困2017-05-24 11:36:58
J'ai utilisé votre code pour l'exécuter, il peut être ouvert en python version 2.7