
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
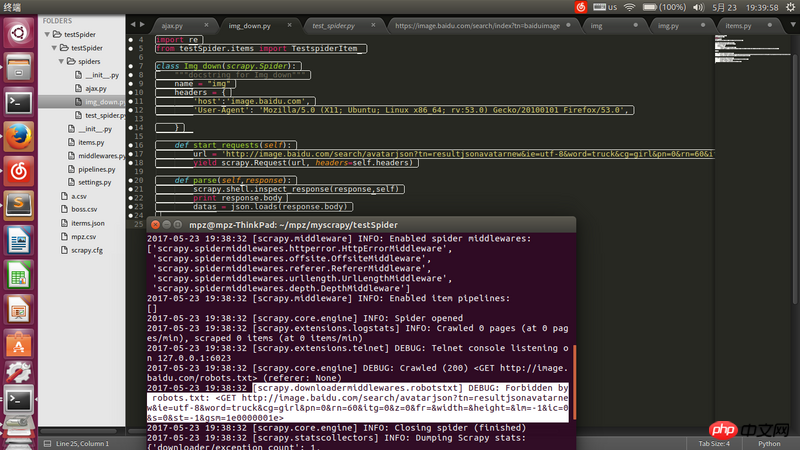
L'URL de l'adresse de requête est l'adresse json obtenue via Firefox. Elle peut être ouverte avec un navigateur, mais elle a été interdite lors de l'exploration avec Scrapy. Veuillez le résoudre.
https://image.baidu.com/searc...

为情所困2017-05-24 11:36:48
Je suis d'accord avec l'étage, s'il y aura encore un mur. La méthode scrapy+selenium+phantomjs peut être utilisée.