
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
Je souhaite capturer les profils de maison séparément et les stocker dans le dictionnaire sous forme de colonnes indépendantes, mais il n'existe aucun moyen d'extraire directement les éléments en ligne à l'aide d'une boucle for.
Voici mon code :
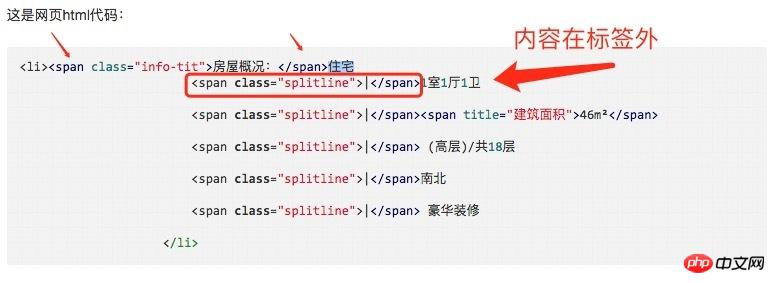
soup.select('.house-info li')[1].text.strip()Voici le code html de la page web :
<li><span class="info-tit">房屋概况:</span>住宅
<span class="splitline">|</span>1室1厅1卫
<span class="splitline">|</span><span title="建筑面积">46m²</span>
<span class="splitline">|</span> (高层)/共18层
<span class="splitline">|</span>南北
<span class="splitline">|</span> 豪华装修
</li>曾经蜡笔没有小新2017-05-18 10:54:42
En fait, c'est très simple. Vous pouvez voir qu'il y a un modèle là-dedans. Le modèle se trouve dans le séparateur |. J'ai écrit une DÉMO
.something = '''<li><span class="info-tit">房屋概况:</span>住宅 <span class="splitline">|</span>1室1厅1卫<span class="splitline">|</span><span title="建筑面积">46m²</span><span class="splitline">|</span> (高层)/共18层
<span class="splitline">|</span>南北
<span class="splitline">|</span> 豪华装修
</li>''';
soup = BeautifulSoup(something, 'lxml')
plaintext = soup.select('li')[0].get_text().strip()Récupérez tout le contenu interne via get_text(), puis supprimez les espaces. Vous pouvez utiliser split pour le diviser plus tard, et je n’écrirai pas le reste.
Si vous avez des questions, veuillez communiquer.
给我你的怀抱2017-05-18 10:54:42
Aperçu de la maison :
46m²
滿天的星座2017-05-18 10:54:42
Dans votre cas, je pense qu'il est plus pratique d'utiliser une boucle for plus des expressions régulières, si tous les modèles sont corrigés comme ceci

黄舟2017-05-18 10:54:42
用pyquery吧
from pyquery importer PyQuery en tant que Q
Q(text).find('.house-info li').text()