
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
Je souhaite utiliser urllib pour récupérer le lien de téléchargement xls de la liste boursière de la Bourse de Shanghai, comme indiqué dans le petit encadré rouge ci-dessous :
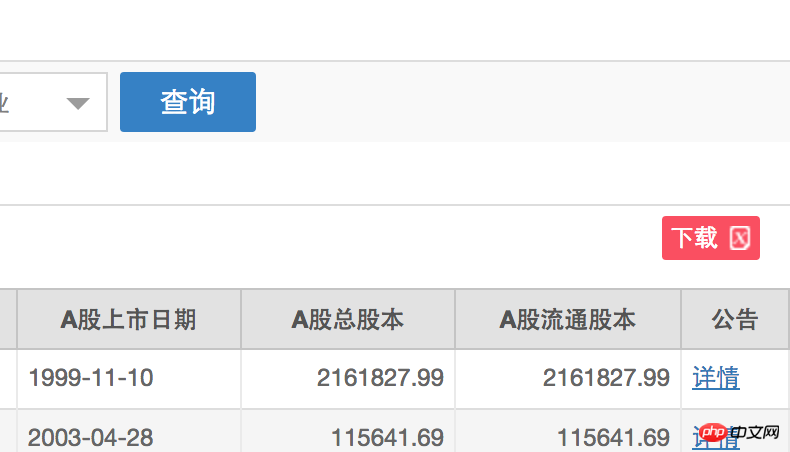
J'ai constaté que les fichiers xls capturés signalaient uniquement un message d'erreur :
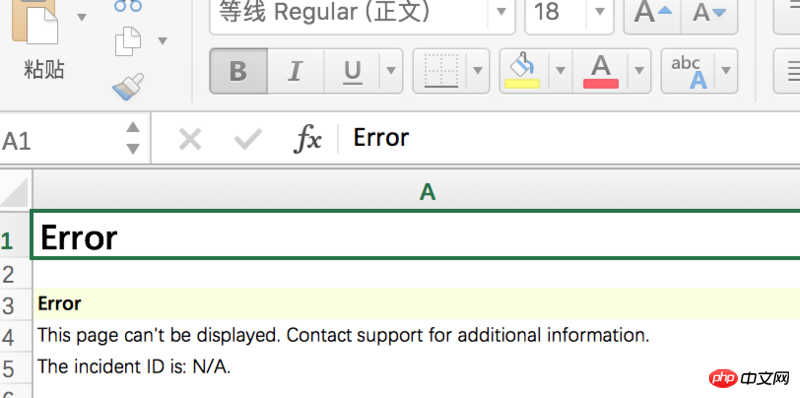
Comment puis-je capturer les xls avec du contenu ?
Le code est le suivant
from urllib import request
from datetime import datetime
# -*- coding:utf-8 -*-
url = 'http://query.sse.com.cn/security/stock/downloadStockListFile.do?' \
'csrcCode=&stockCode=&areaName=&stockType=1'
myheaders = [('User - Agent', 'Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13'
' (KHTML, like Gecko) Version/3.1 Safari/525.13'),]
opener = request.build_opener()
opener.addheaders = myheaders
request.install_opener(opener)
local = "/Users/Mty/Downloads/data/" + str(datetime.now().date()) + " .xls"
request.urlretrieve(url, local)
黄舟2017-05-18 10:48:56
Vous pouvez voir les informations renvoyées sur l'entreprise sur l'URL marquée d'une ligne rouge. Le reste sert à simuler le navigateur demandant cette URL. La référence dans l'en-tête de la requête ne doit pas être omise, sinon 403 sera signalé
.N'oubliez pas de simuler la valeur de référence.
http://blog.csdn.net/ssshen14...
Il s'agit d'une solution existante
