
- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
J'ai écrit un petit morceau de code pour explorer les images du blog Blog Park. Ce code est efficace pour certains liens, mais certains liens signalent des erreurs dès qu'ils sont explorés. Quelle en est la raison ?
#coding=utf-8
import urllib
import re
from lxml import etree
#解析地址
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#获取地址并建树
url = "http://www.cnblogs.com/fnng/archive/2013/05/20/3089816.html"
html = getHtml(url)
html = html.decode("utf-8")
tree = etree.HTML(html)
#保存图片至本地
reg = r'src="(.*?)" alt'
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl, '%s.jpg' % x)
x += 1Comme le montre l'image, l'image peut être explorée correctement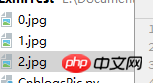
Si vous changez l'URL en
url = "http://www.cnblogs.com/baronzhang/p/6861258.html"Ensuite, une erreur sera signalée immédiatement

Veuillez le résoudre, merci !
我想大声告诉你2017-05-18 10:47:39
Le message d'erreur est déjà très évident. Si vous regardez le code source de la page Web, la première image correspondante est au format GIF, et il s'agit toujours d'un chemin relatif, vous ne pouvez donc pas la télécharger, donc cela provoque IOerror, même si vous l'avez téléchargé, parce que vous avez spécifié le format JPG, vous ne pouvez pas l'ouvrir. Il ne vous reste plus qu'à juger et filtrer
for imgurl in imglist:
if "gif" not in imgurl:
urllib.urlretrieve(imgurl, '%s.jpg' % x)
x += 1
Regardez ce que j'ai ajouté. Bien sûr, ce n'est que le jugement le plus simple, mais cela peut garantir que votre deuxième programme ne signalera pas d'erreur, et cela vous donne aussi une idée !