- communauté
- Apprendre
- Bibliothèque d'outils
- Loisirs
Maison > Questions et réponses > le corps du texte
Problèmes de vérification lors de la récupération des articles du compte public WeChat sous Linux ! ! ! ! ! ! ! !
Voici le lien vers le Quotidien du Peuple que je souhaite récupérer : http://mp.weixin.qq.com/profile?src=3×tamp=1492739045&ver=1&signature=bSSQMK1LY77M4O22qTi37cbhjhwNV7C9V4aor9HLhAvbGc2ybWX*qg3WqxntZ7iq0kvYe87oPpcSJKFdmGMx5g==
1 : Tout d’abord, il est normal d’y accéder sur le navigateur.
2 : L'invite d'accès sous Linux nécessite une vérification. Ce qui suit est un code simple
url = http://mp.weixin.qq.com/profile?src=3×tamp=1492738883&ver=1&signature=bSSQMK1LY77M4O22qTi37cbhjhwNV7C9V4aor9HLhAvbGc2ybWX*qg3WqxntZ7iq2xTLUTfxAMzK79UGvalY1A==
response = urllib2.urlopen(url)
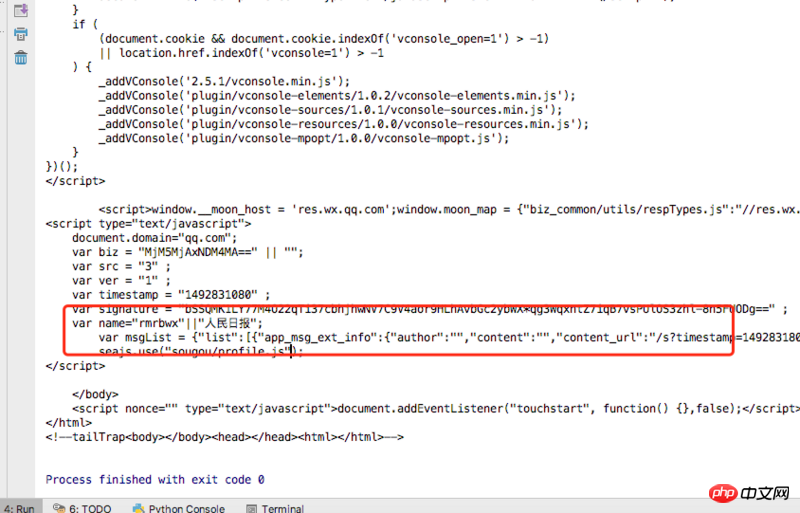
print response.read()Les résultats de la visite sont les suivants : 
Explication supplémentaire sur la façon d'obtenir le lien vers le compte officiel :
1 : Visitez d'abord le lien : http://weixin.sogou.com/weixi...
2 : Obtenez ensuite le lien vers le compte officiel du Quotidien du Peuple pour saut.
習慣沉默2017-05-16 13:35:44
Peut-il être capturé sans simuler l'en-tête de la requête ? Il est recommandé de simuler d'abord l'en-tête de la requête et de réessayer
某草草2017-05-16 13:35:44
# coding: utf-8
import requests
headers = {}
headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
url = 'http://mp.weixin.qq.com/profile?src=3×tamp=1492739045&ver=1&signature=bSSQMK1LY77M4O22qTi37cbhjhwNV7C9V4aor9HLhAvbGc2ybWX*qg3WqxntZ7iq0kvYe87oPpcSJKFdmGMx5g=='
r = requests.get(url, headers=headers)
print r.text淡淡烟草味2017-05-16 13:35:44

Maintenant, après avoir ajouté l'en-tête à la requête, l'erreur renvoyée est la suivante. S'il vous plaît, donnez-moi quelques conseils supplémentaires
習慣沉默2017-05-16 13:35:44
import requests
headers = {'user-agent' : 'Mozilla/5.0'}
respon = requests.get('http://mp.weixin.qq.com/profile?src=3×tamp=1492831080&ver=1&signature=bSSQMK1LY77M4O22qTi37cbhjhwNV7C9V4aor9HLhAvbGc2ybWX*qg3WqxntZ7iqB7vsPUlOS3zhl-8n5FUODg==', headers = headers)
respon.encoding = 'utf-8'
print(respon.text)