
Maison >interface Web >js tutoriel >Une brève discussion sur l'historique du développement des connaissances Unicode et JavaScript_Basic
Une brève discussion sur l'historique du développement des connaissances Unicode et JavaScript_Basic

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBoriginal
- 2016-05-16 16:19:261283parcourir
1. Qu'est-ce qu'Unicode ?
Unicode est né d'une idée très simple : inclure tous les caractères du monde dans un seul jeu. Tant que l'ordinateur prend en charge ce jeu de caractères, il peut afficher tous les caractères et il n'y aura plus de caractères tronqués.
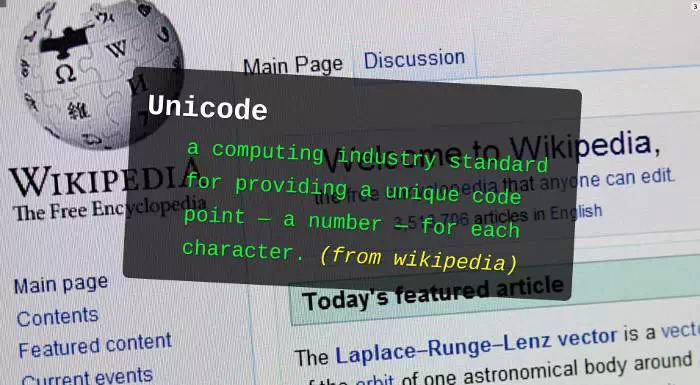
Il part de 0 et attribue un numéro à chaque symbole, appelé "codepoint". Par exemple, le symbole du point de code 0 est nul (ce qui signifie que tous les bits binaires sont 0).
Dans la formule ci-dessus, U indique que le nombre hexadécimal qui suit immédiatement est le point de code Unicode.

Actuellement, la dernière version d'Unicode est la version 7.0, qui contient un total de 109 449 symboles, dont 74 500 caractères chinois, japonais et coréens. On peut estimer que plus des deux tiers des symboles existants dans le monde proviennent d’écritures d’Asie de l’Est. Par exemple, le point de code pour « bon » en chinois est 597D en hexadécimal.
Avec autant de symboles, Unicode n'est pas défini une seule fois, mais par partitions. Chaque zone peut stocker 65 536 (216) caractères, ce que l'on appelle un plan. Actuellement, il y a 17 (25) plans au total, ce qui signifie que la taille de l'ensemble du jeu de caractères Unicode est désormais de 221.
Les 65536 premiers bits de caractères sont appelés le plan de base (abréviation BMP). Sa plage de points de code est de 0 à 216-1. Écrit en hexadécimal, il va de U 0000 à U FFFF. Tous les caractères les plus courants sont placés sur ce plan, qui est le premier plan défini et annoncé par Unicode.
Les caractères restants sont placés dans le plan auxiliaire (en abrégé SMP) et les points de code vont de U 010000 à U 10FFFF.

2.UTF-32 et UTF-8
Unicode stipule uniquement le point de code de chaque caractère. Le type d'ordre des octets utilisé pour représenter ce point de code implique la méthode de codage.
La méthode de codage la plus intuitive est que chaque point de code est représenté par quatre octets et que le contenu de l'octet correspond au point de code un à un. Cette méthode de codage est appelée UTF-32. Par exemple, le point de code 0 est représenté par quatre octets de 0 et le point de code 597D est précédé de deux octets de 0.

L'avantage de l'UTF-32 est que les règles de conversion sont simples et intuitives et que l'efficacité de la recherche est élevée. L'inconvénient est que cela gaspille de l'espace. Pour le même texte anglais, il sera quatre fois plus volumineux que l'encodage ASCII. Cette lacune est si fatale que personne n’utilise réellement cette méthode d’encodage. La norme HTML5 stipule clairement que les pages Web ne doivent pas être encodées en UTF-32.

Ce dont les gens avaient vraiment besoin, c'était d'une méthode d'encodage peu encombrante, ce qui a conduit à la naissance de l'UTF-8. UTF-8 est une méthode de codage à longueur variable, avec des longueurs de caractères allant de 1 octet à 4 octets. Plus les caractères sont couramment utilisés, plus les octets sont courts. Les 128 premiers caractères sont représentés par seulement 1 octet, ce qui est exactement le même que le code ASCII.
Plage de numéros octets 0x0000 - 0x007F10x0080 - 0x07FF20x0800 - 0xFFFF30x010000 - 0x10FFFF4
En raison des caractéristiques d'économie d'espace de l'UTF-8, il est devenu le codage de pages Web le plus courant sur Internet. Cependant, cela n'a pas grand-chose à voir avec le sujet d'aujourd'hui, donc je n'entrerai pas dans les détails pour des méthodes de transcodage spécifiques, vous pouvez vous référer aux « Notes sur le codage des caractères » que j'ai écrites il y a de nombreuses années.
3. Introduction à l'UTF-16
L'encodage UTF-16 se situe entre UTF-32 et UTF-8 et combine les caractéristiques des méthodes d'encodage de longueur fixe et de longueur variable.
Ses règles d'encodage sont très simples : les caractères du plan de base occupent 2 octets, et les caractères du plan auxiliaire occupent 4 octets. C'est-à-dire que la longueur de codage de l'UTF-16 est soit de 2 octets (U 0000 à U FFFF), soit de 4 octets (U 010000 à U 10FFFF).

Il y a donc une question. Lorsque nous rencontrons deux octets, comment pouvons-nous savoir s'il s'agit d'un caractère en soi, ou doit-il être interprété avec les deux autres octets ?
C'est très astucieux. Je ne sais pas si c'est une conception intentionnelle. Dans le plan de base, de U D800 à U DFFF il y a un segment vide, c'est-à-dire que ces points de code ne correspondent à aucun caractère. Par conséquent, ce segment vide peut être utilisé pour mapper des caractères de plan auxiliaire.
Concrètement, il y a 220 bits de caractères dans le plan auxiliaire, ce qui signifie qu'il faut au moins 20 bits binaires pour correspondre à ces caractères. UTF-16 divise ces 20 bits en deux. Les 10 premiers bits sont mappés de U D800 à U DBFF (taille d'espace 210), appelés bit haut (H), et les 10 derniers bits sont mappés de U DC00 à U DFFF ( taille d'espace 210), appelé bit faible (L). Cela signifie qu'un caractère plan auxiliaire est divisé en deux représentations de caractères plan de base.

Ainsi, lorsque nous rencontrons deux octets et constatons que leurs points de code sont compris entre U D800 et U DBFF, nous pouvons conclure que les points de code des deux octets suivants doivent être compris entre U DC00 et U DBFF, ces quatre. les octets doivent être lus ensemble.
4. Formule de transcodage UTF-16
Lors de la conversion de points de code Unicode en UTF-16, distinguez d'abord s'il s'agit d'un caractère plat de base ou d'un caractère plat auxiliaire. Si c'est le premier cas, convertissez directement le point de code sous la forme hexadécimale correspondante, d'une longueur de deux octets.
S'il s'agit d'un caractère plat auxiliaire, la version Unicode 3.0 fournit une formule de transcodage.

Prenons le caractère  comme exemple. Il s'agit d'un caractère plan auxiliaire avec un point de code U 1D306. Le processus de calcul pour le convertir en UTF-16 est le suivant.
comme exemple. Il s'agit d'un caractère plan auxiliaire avec un point de code U 1D306. Le processus de calcul pour le convertir en UTF-16 est le suivant.
Ainsi, le codage UTF-16 du caractère est 0xD834 DF06 et la longueur est de quatre octets.

5. Quel encodage JavaScript utilise-t-il ?

Le langage JavaScript utilise le jeu de caractères Unicode, mais ne prend en charge qu'une seule méthode d'encodage.
Cet encodage n'est ni UTF-16, ni UTF-8, ni UTF-32. Aucune des méthodes de codage ci-dessus n'est utilisée en JavaScript.
JavaScript utilise UCS-2 !

6. Encodage UCS-2
Pourquoi un UCS-2 est-il soudainement apparu ? Cela nécessite un peu d'histoire.
À l'époque précédant l'apparition d'Internet, deux équipes souhaitaient créer un jeu de caractères unifié. L’une est l’équipe Unicode créée en 1988 et l’autre est l’équipe UCS créée en 1989. Lorsqu’ils ont découvert l’existence de l’autre, ils sont rapidement parvenus à un accord : le monde n’a pas besoin de deux jeux de caractères unifiés.
En octobre 1991, les deux équipes décident de fusionner les jeux de caractères. En d'autres termes, à partir de maintenant, un seul jeu de caractères sera publié, à savoir Unicode, et les jeux de caractères précédemment publiés seront révisés. Les points de code d'UCS seront totalement cohérents avec Unicode.

La progression du développement d'UCS est plus rapide que celle d'Unicode. La première méthode de codage UCS-2 a été annoncée en 1990, utilisant 2 octets pour représenter les caractères qui ont déjà des points de code. (A cette époque, il n'y avait qu'un seul plan, le plan de base, donc 2 octets suffisaient.) Le codage UTF-16 n'a été annoncé qu'en juillet 1996, et il a été clairement annoncé qu'il s'agissait d'un surensemble d'UCS-2, c'est-à-dire , les caractères du plan de base ont été hérités du codage UCS-2, les caractères du plan auxiliaire définissent une méthode de représentation sur 4 octets.
Pour faire simple, la relation entre les deux est que UTF-16 remplace UCS-2, ou UCS-2 est intégré à UTF-16. Il n’y a donc plus que UTF-16, pas d’UCS-2.
7. Contexte de la naissance de JavaScript
Alors, pourquoi JavaScript ne choisit-il pas l'UTF-16, plus avancé, mais utilise l'UCS-2 obsolète ?
La réponse est simple : soit vous ne voulez pas, soit vous ne pouvez pas. Car lorsque le langage JavaScript est apparu, il n’existait pas d’encodage UTF-16.
En mai 1995, Brendan Eich a passé 10 jours à concevoir le langage JavaScript ; en octobre, le premier moteur d'interprétation est sorti ; en novembre de l'année suivante, Netscape a officiellement soumis le standard de langage à l'ECMA (pour plus de détails sur l'ensemble du processus, voir "La naissance de JavaScript" ). En comparant l'époque de sortie de l'UTF-16 (juillet 1996), vous comprendrez que Netscape n'avait pas d'autre choix à cette époque, seul UCS-2 était disponible comme méthode d'encodage !

8. Limites des fonctions de caractères JavaScript
Étant donné que JavaScript ne peut gérer que l'encodage UCS-2, tous les caractères de ce langage font 2 octets. S'il s'agit d'un caractère de 4 octets, il sera traité comme deux caractères à deux octets. Les fonctions de caractères de JavaScript sont toutes affectées par cela et ne peuvent pas renvoyer de résultats corrects.

Prenons le caractère comme exemple. Son encodage UTF-16 est de 4 octets de 0xD834DF06. Le problème se pose : le codage sur 4 octets n'appartient pas à UCS-2. JavaScript ne le reconnaît pas et ne le considérera que comme deux caractères distincts, U D834 et U DF06. Comme mentionné précédemment, ces deux points de code sont vides, donc JavaScript pensera que est une chaîne composée de deux caractères vides !

Le code ci-dessus indique que JavaScript considère la longueur du caractère comme étant 2, le premier caractère obtenu est un caractère nul et le point de code du premier caractère obtenu est 0xDB34. Aucun de ces résultats n'est correct !

Pour résoudre ce problème, vous devez porter un jugement sur le point de code puis l'ajuster manuellement. Ce qui suit est la bonne façon de parcourir une chaîne.
Le code ci-dessus indique que lors du parcours d'une chaîne, un jugement doit être porté sur le point de code Tant qu'il est compris entre 0xD800 et 0xDBFF, il doit être lu avec les 2 octets suivants
Des problèmes similaires existent avec toutes les fonctions de manipulation de caractères JavaScript.
String.prototype.replace()
String.prototype.substring()
String.prototype.slice()
...
Les fonctions ci-dessus ne sont valables que pour les points de code à 2 octets. Pour gérer correctement les points de code de 4 octets, vous devez déployer vos propres versions une par une pour déterminer la plage de points de code du caractère actuel.
9.ECMAScript 6

La prochaine version de JavaScript, ECMAScript 6 (ES6 en abrégé), améliore considérablement la prise en charge d'Unicode et résout fondamentalement ce problème.
(1) Identifier correctement les personnages
ES6 peut reconnaître automatiquement les points de code de 4 octets. Par conséquent, parcourir la chaîne est beaucoup plus simple.
Cependant, pour maintenir la compatibilité, l'attribut length se comporte toujours de sa manière d'origine. Afin d'obtenir la bonne longueur de chaîne, vous pouvez utiliser la méthode suivante.
(2) Représentation des points de code
JavaScript vous permet d'utiliser directement des points de code pour représenter des caractères Unicode. La méthode d'écriture est "backslash u code point".
Cependant, cette représentation n'est pas valable pour les points de code à 4 octets. ES6 résout ce problème et les points de code peuvent être correctement reconnus tant qu'ils sont placés entre accolades.

(3) Fonction de traitement de chaîne
ES6 ajoute plusieurs nouvelles fonctions qui gèrent spécifiquement les points de code à 4 octets.
String.fromCodePoint() : renvoie le caractère correspondant du point de code Unicode
String.prototype.codePointAt() : renvoie le point de code correspondant du caractère
String.prototype.at() : Renvoie le caractère à la position donnée dans la chaîne
(4) Expression régulière
ES6 fournit le modificateur u, qui prend en charge l'ajout de points de code de 4 octets aux expressions régulières.

(5) Régularisation Unicode
Certains caractères ont des symboles supplémentaires en plus des lettres. Par exemple, dans le pinyin chinois de Ǒ, les tons au-dessus des lettres sont des symboles supplémentaires. Pour de nombreuses langues européennes, les marques de ton sont très importantes.

Unicode propose deux méthodes de représentation. L'un est un caractère unique avec un symbole supplémentaire, c'est-à-dire qu'un point de code représente un caractère, par exemple, le point de code de Ǒ est U 01D1 ; l'autre est le symbole supplémentaire en tant que point de code distinct, combiné avec le caractère principal ; c'est-à-dire que deux codes Un point représente un caractère, par exemple Ǒ peut être écrit sous la forme O (U 004F) ˇ (U 030C).
Les deux représentations sont visuellement et sémantiquement identiques et doivent être traitées comme équivalentes. Cependant, JavaScript ne peut pas le savoir.
ES6 fournit la méthode normalize, permettant la "normalisation Unicode", c'est-à-dire la conversion de deux méthodes dans la même séquence.
Pour plus d'informations sur ES6, veuillez consulter « Introduction à ECMAScript 6 ».
Articles Liés
Voir plus- Une analyse approfondie du composant de groupe de liste Bootstrap
- Explication détaillée du currying de la fonction JavaScript
- Exemple complet de génération de mot de passe JS et de détection de force (avec téléchargement du code source de démonstration)
- Angularjs intègre l'interface utilisateur WeChat (weui)
- Comment basculer rapidement entre le chinois traditionnel et le chinois simplifié avec JavaScript et l'astuce permettant aux sites Web de prendre en charge le basculement entre les compétences en chinois simplifié et traditionnel_javascript