
Maison >Périphériques technologiques >IA >7 262 articles ont été soumis, l'ICLR 2024 est devenu un succès et deux articles nationaux ont été nominés pour les articles exceptionnels.
7 262 articles ont été soumis, l'ICLR 2024 est devenu un succès et deux articles nationaux ont été nominés pour les articles exceptionnels.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-05-08 20:34:241225parcourir
Au total, 5 prix d'articles exceptionnels et 11 mentions honorables ont été sélectionnés cette année.
ICLR signifie International Conference on Learning Representations. Cette année, c'est la 12ème conférence, qui se tient à Vienne, en Autriche, du 7 au 11 mai.
Dans la communauté de l'apprentissage automatique, l'ICLR est une conférence académique de premier plan relativement « jeune ». Elle est organisée par les géants de l'apprentissage profond et lauréats du prix Turing, Yoshua Bengio et Yann LeCun. Elle vient de tenir sa première session en 2013. Cependant, l’ICLR a rapidement acquis une large reconnaissance auprès des chercheurs universitaires et est considérée comme la principale conférence universitaire sur l’apprentissage profond.
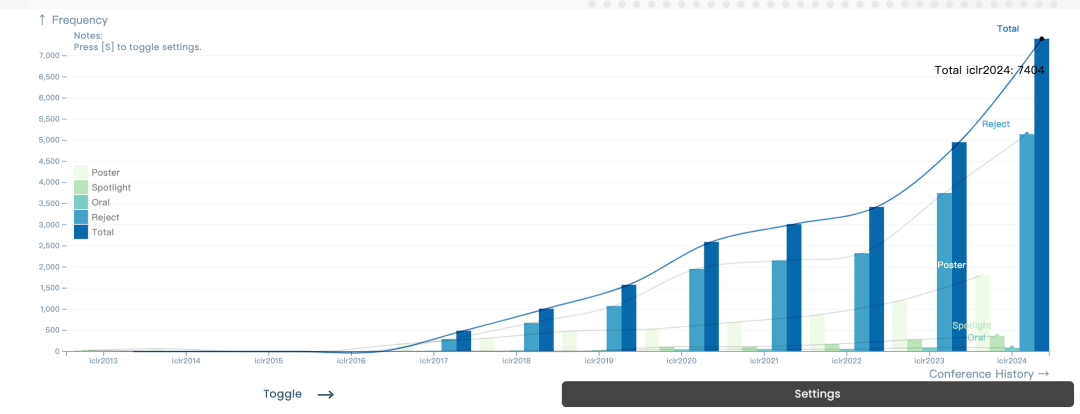
Cette conférence a reçu un total de 7 262 articles soumis et a accepté 2 260 articles. Le taux d'acceptation global était d'environ 31 %, le même que l'année dernière (31,8 %). De plus, la proportion d'articles Spotlights est de 5 % et la proportion d'articles oraux est de 1,2 %.


Par rapport aux années précédentes, qu'il s'agisse du nombre de participants ou du nombre de soumissions d'articles, on peut dire que la popularité de l'ICLR a considérablement augmenté. R Pour les données de thèse précédentes de l'ICLR
5 Outstanding Paper Awards
Lauréats d'Outstanding Paper
Article : La généralisation dans les modèles de diffusion découle de représentations harmoniques adaptatives à la géométrie
Adresse de l'article : https://openreview.net / pdf?id=ANvmVS2Yr0

- Auteur : Zahra Kadkhodaie, Florentin Guth, Eero P. Simoncelli, Stéphane Mallat
- Cet article généralise le modèle de diffusion d'images et Important analyse approfondie de la mémoire. Les auteurs étudient empiriquement le moment où un modèle de génération d'images passe de l'entrée mémoire au mode de généralisation et le relient à l'idée d'analyse harmonique via une représentation harmonique géométriquement adaptative, expliquant davantage ce phénomène du point de vue du biais d'induction architecturale. Cet article couvre un élément clé manquant dans notre compréhension des modèles génératifs de vision et a de grandes implications pour les recherches futures.
Article : Apprendre des simulateurs interactifs du monde réel
Adresse de l'article : https://openreview.net/forum?id=sFyTZEqmUY

- Auteurs : Sherry Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Leslie Kaelbling, Dale Schuurmans, Pieter Abbeel
- L'agrégation de données provenant de plusieurs sources pour former un modèle de base pour les robots est un travail à long terme but. Étant donné que différents robots ont des interfaces sensorimotrices différentes, cela pose des défis importants pour la formation sur des ensembles de données à grande échelle.
-
UniSim
, est une étape importante dans cette direction et une prouesse d'ingénierie, en tirant parti d'une interface unifiée basée sur des descriptions textuelles de la perception visuelle et du contrôle pour agréger les données et en tirant parti des dernières avancées en matière de vision et de langage développées pour former des simulateurs de robots. .
Comme le montre la figure 3 ci-dessous, UniSim peut simuler une série d'actions riches, telles que se laver les mains, prendre des bols, couper des carottes et se sécher les mains dans une scène de cuisine ; La figure 3 montre deux scènes de navigation. # La scène de navigation en bas à droite de la figure 3

Thèse : Ne jamais s'entraîner à partir de zéro : une comparaison équitable des modèles à séquence longue nécessite une approche basée sur les données avant Jonathan Berant, Ankit Cet article explore les capacités des modèles d'espace d'état et des architectures de transformateur récemment proposés pour modéliser les dépendances de séquence à long terme.
Étonnamment, les auteurs ont découvert que la formation d'un modèle de transformateur à partir de zéro entraîne une sous-estimation de ses performances, et que des améliorations significatives des performances peuvent être obtenues grâce à un pré-entraînement et à des réglages précis. Le document excelle dans l’accent mis sur la simplicité et les informations systématiques. 
Article : Protein Discovery with Discrete Walk-Jump Sampling
Adresse de l'article : https://openreview.net/forum?id=zMPHKOmQNb

- Auteurs : Nathan C. Frey, Dan Berenberg, Karina Zadorozhny, Joseph Kleinhenz, Julien Lafrance-Vanasse, Isidro Hotzel, Yan Wu, Stephen Ra, Richard Bonneau, Kyunghyun Cho, Andreas Loukas, Vladimir Gligorijevic, Saeed Saremi
- Cet article aborde le problème de la conception d’anticorps basée sur la séquence, une application importante et opportune des modèles de génération de séquences protéiques.
- À cette fin, l'auteur présente une nouvelle méthode de modélisation innovante et efficace spécifiquement ciblée sur le problème du traitement des données de séquences protéiques discrètes. En plus de valider la méthode in silico, les auteurs ont réalisé de nombreuses expériences en laboratoire humide pour mesurer les affinités de liaison des anticorps in vitro, démontrant ainsi l'efficacité de leur méthode générée. Article : Vision Transformers Need Registers
Adresse de l'article : https://openreview.net/forum?id=2dnO3LLiJ1

- Auteur : Othée Darce t. Maxime Oquab, Julien Mairal, Piotr Bojanowski
- Cet article identifie les artefacts dans la carte caractéristique d'un réseau de transformateurs de vision, qui sont caractérisés par des jetons de haute norme dans des régions d'arrière-plan à faible information.
- Les auteurs proposent des hypothèses clés sur la manière dont ce phénomène se produit et proposent une solution simple mais élégante utilisant des jetons de registre supplémentaires pour traiter ces traces, améliorant ainsi les performances du modèle sur diverses tâches. Les enseignements tirés de ces travaux pourraient également avoir un impact sur d’autres domaines d’application. Cet article est parfaitement rédigé et fournit un bon exemple de conduite de recherche : "Identifier le problème, comprendre pourquoi il se produit, puis proposer une solution."
11 mentions honorables
En plus de 5 articles exceptionnels Articles, L'ICLR 2024 a également sélectionné 11 mentions honorables.Article : Amortizing intractable inference in large Language Models

- Institution : Université de Montréal, Université d'Oxford
- Auteur : Edward J Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio , Nikolay Malkin
- Adresse de l'article : https://openreview.net/forum?id=Ouj6p4ca60
- Cet article propose une alternative au décodage autorégressif dans les grands modèles de langage du point de vue de l'inférence bayésienne. ce qui pourrait inspirer des recherches de suivi.
Institution : DeepMind
Auteur : Ian Gimp, Luke Marris, Georgios Piliouras
Adresse de l'article : https://open review .net/forum?id=cc8h3I3V4E
-
Il s'agit d'un article très clair qui contribue de manière significative à résoudre le problème important du développement de solveurs Nash efficaces et évolutifs.
Article : Au-delà de Weisfeiler-Lehman : Un cadre quantitatif pour l'expressivité du GNN
Institution : Université de Pékin, Institut de recherche sur l'intelligence artificielle Zhiyuan de Pékin
Auteur : Zhang Bohang Gai Jingchu Du Yiheng Ye Qiwei Hedi Wang Liwei
Adresse papier : https://openreview.net/forum?id=HSKaGOi7Ar
La capacité d'expression du GNN est un sujet important, et les solutions actuelles ont encore de grandes limites. L'auteur propose une nouvelle théorie de l'expressivité basée sur le comptage homomorphe.
Article : Flow Matching on General Geometries
Institution : Meta
Auteur : Ricky T. Q. Chen, Yaron Lipman
Adresse de l'article : https://openreview.net/forum?id=g7ohDlTITL
Cet article explore le problème difficile mais important de la modélisation générative sur les variétés géométriques générales et propose un algorithme pratique et efficace. L'article est parfaitement présenté et entièrement validé expérimentalement sur un large éventail de tâches.
Article : ImageNet vaut-il 1 vidéo ? Apprendre des encodeurs d'images puissants à partir d'une longue vidéo non étiquetée
Institutions : Université de Floride centrale, Google DeepMind, Université d'Amsterdam, etc.
Auteurs : Shashanka Venkataramanan, Mamshad Nayeem Rizve, Joao Carreira, Yuki M Asano, Yannis Avrithis
Adresse papier : https://openreview.net/forum?id=Yen1lGns2o
Cet article propose une nouvelle méthode de pré-formation d'images auto-supervisée , c'est-à-dire en s'entraînant à partir d'apprendre à partir de vidéos continues. Cet article apporte à la fois un nouveau type de données et une méthode pour apprendre à partir de nouvelles données.
Article : L'apprentissage continu méta revisité : amélioration implicite de l'approximation hessienne en ligne via la réduction de la variance
Institution : City University of Hong Kong, Tencent AI Lab, Xi'an Jiaotong University, etc.
Auteur : Yichen Wu, Long-Kai Huang, Renzhen Wang, Deyu Meng et Ying Wei
Adresse papier : https://openreview.net/forum?id=TpD2aG1h0D
Les auteurs ont proposé une nouvelle variante d'apprentissage méta-continu méthode de réduction. La méthode fonctionne bien et a non seulement un impact pratique, mais est également étayée par une analyse des regrets.
Papier : Le modèle vous indique ce qu'il faut supprimer : Compression adaptative du cache KV pour les LLM
Institution : Université de l'Illinois à Urbana-Champaign, Microsoft
Auteurs : Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, Jianfeng Gao
Adresse papier : https://openreview.net/forum?id=uNrFpDPMyo
Cet article se concentre sur le problème de compression du cache KV (ce problème a un grand impact sur Transformer- basé LLM), avec une idée simple qui réduit la mémoire et peut être déployée sans ajustement ni recyclage coûteux. Cette méthode est très simple et s’est avérée très efficace.
Article : Prouver la contamination des ensembles de tests dans des modèles linguistiques en boîte noire
Institution : Université de Stanford, Université de Columbia
-
Auteur : Yonatan Oren, Nicole Meister, Niladri S. Chatterji, Faisal Ladhak, Tatsunori Hashimoto
Adresse de l'article : https://openreview.net/forum?id=KS8mIvetg2
Cet article utilise une méthode simple et élégante pour tester si des ensembles de données d'apprentissage supervisé ont été inclus dans de grands modèles de langage en formation.
Article : Les agents robustes apprennent les modèles du monde causal
Institution : Google DeepMind
Auteur : Jonathan Richens, Tom Everitt
Adresse de l'article : https://openreview.net/forum?id= pOoKI3ouv1
Cet article fait de grands progrès en posant les bases théoriques pour comprendre le rôle du raisonnement causal dans la capacité d'un agent à généraliser à de nouveaux domaines, avec des implications pour une gamme de domaines connexes.
Article : La base mécanistique de la dépendance aux données et de l'apprentissage brutal dans une tâche de classification en contexte
Institution : Université de Princeton, Université Harvard, etc.
Auteur : Gautam Reddy
Adresse papier : https ://openreview.net/forum?id=aN4Jf6Cx69
Il s'agit d'une étude opportune et extrêmement systématique qui explore la relation entre l'apprentissage en contexte et l'apprentissage en poids alors que nous commençons à comprendre ces phénomènes.
Article : Vers une théorie statistique de la sélection de données sous supervision faible
Institution : Granica Computing
Auteur : Germain Kolossov, Andrea Montanari, Pulkit Tandon
Adresse de l'article : https://openreview .net/forum?id=HhfcNgQn6p
Cet article établit une base statistique pour la sélection de sous-ensembles de données et identifie les lacunes des méthodes de sélection de données populaires.
Lien de référence : https://blog.iclr.cc/2024/05/06/iclr-2024-outstanding-paper-awards/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Simulateur essentiel pour le développement d'APP : Comment télécharger et utiliser le simulateur Yeshen (images et texte)
- Ronglian Cloud a été sélectionné dans la carte mondiale de l'industrie de l'IA générative 2023
- L'orientation de l'application du langage Go dans l'industrie médicale intelligente
- Comment utiliser le doigt d'or du simulateur Nozoomer
- Tutoriel de démarrage ASUS VT : Comment configurer le simulateur de foudre