
Maison >Périphériques technologiques >IA >Les indicateurs du MoE open source national explosent : capacités de niveau GPT-4, le prix de l'API n'est que de 1 %
Les indicateurs du MoE open source national explosent : capacités de niveau GPT-4, le prix de l'API n'est que de 1 %

- PHPzavant
- 2024-05-07 17:34:01712parcourir
Le dernier grand modèle MoE open source national est devenu populaire juste après ses débuts.
Les performances de DeepSeek-V2 atteignent le niveau GPT-4, mais il est open source, gratuit pour un usage commercial, et le prix de l'API ne représente qu'un pour cent de GPT-4-Turbo.
Donc, dès sa sortie, cela a immédiatement déclenché de nombreuses discussions.
 Photos
Photos
À en juger par les indicateurs de performance publiés, les capacités chinoises complètes de DeepSeek V2 dépassent celles de nombreux modèles open source. Dans le même temps, les modèles fermés tels que GPT-4 Turbo et Wenkuai 4.0 sont également parmi les premiers. échelon.
La maîtrise complète de l'anglais se situe également dans le même premier échelon que LLaMA3-70B et dépasse Mixtral 8x22B, qui est également un MoE.
Il montre également de bonnes performances en connaissances, mathématiques, raisonnement, programmation, etc. Et prend en charge le contexte 128K.
 Images
Images
Ces fonctionnalités peuvent être directement utilisées gratuitement par les utilisateurs ordinaires. La bêta fermée est maintenant ouverte, vous pouvez en faire l'expérience immédiatement après votre inscription.
 Pictures
Pictures
L'API est encore plus chère : l'entrée est de 1 yuan et la sortie est de 2 yuans par million de jetons (contexte 32K). Le prix ne représente que près d’un pour cent de celui du GPT-4-Turbo.
Dans le même temps, l'architecture du modèle est également innovée, en utilisant des structures MLA (Multi-head Latent Attention) et Sparse auto-développées, ce qui peut réduire considérablement la quantité de calcul du modèle et de mémoire d'inférence.
Les internautes ont déploré : DeepSeek apporte toujours des surprises aux gens !
 Photos
Photos
Nous avons été les premiers à ressentir les effets spécifiques !
Testez-le en pratique
Actuellement, la version bêta interne V2 peut expérimenter l'assistant universel de dialogue et de code.
 Images
Images
Vous pouvez tester la logique, les connaissances, la génération, les mathématiques et d'autres capacités des grands modèles dans des conversations générales.
Par exemple, vous pouvez lui demander d'imiter le style de "La Légende de Zhen Huan" pour rédiger un texte de plantation de rouge à lèvres.
 Images
Images
peuvent également expliquer de manière populaire ce qu'est l'intrication quantique.
 Images
Images
En termes de mathématiques, il peut répondre à des questions de calcul avancées, telles que :
Utilisez le calcul pour prouver la représentation en série infinie de la base e du logarithme naturel.
 Images
Images
peuvent également éviter certains pièges logiques du langage.
 Photos
Photos
Le test montre que le contenu des connaissances de DeepSeek-V2 a été mis à jour jusqu'en 2023.
 Photos
Photos
En termes de code, la page de test interne montre que DeepSeek-Coder-33B est utilisé pour répondre aux questions.
En générant des codes plus simples, il n'y a eu aucune erreur dans plusieurs tests réels.
 Pictures
Pictures
peut également expliquer et analyser le code donné.
 Photos
Photos
 Photos
Photos
Cependant, il existe également des cas de mauvaises réponses dans le test.
Dans la question logique suivante, pendant le processus de calcul, DeepSeek-V2 a calculé par erreur le temps nécessaire pour qu'une bougie soit allumée par les deux extrémités en même temps et s'éteigne comme étant un quart du temps nécessaire pour qu'elle brûle. d'une extrémité. Quelles améliorations apportent
 pictures
pictures
?
Selon l'introduction officielle, DeepSeek-V2 a un paramètre total de 236B et une activation de 21B, ce qui atteint à peu près la capacité du modèle de 70B ~ 110B Dense.
 Photos
Photos
Par rapport au précédent DeepSeek 67B, il offre des performances plus élevées et des coûts de formation inférieurs. Il peut économiser 42,5 % des coûts de formation, réduire le cache KV de 93,3 % et augmenter le débit maximum à 5,76 fois.
Officiellement déclaré, cela signifie que la mémoire vidéo (KV Cache) consommée par DeepSeek-V2 ne représente que 1/5~1/100 du modèle Dense du même niveau, et le coût par jeton est considérablement réduit.
De nombreuses optimisations de communication ont été réalisées spécifiquement pour les spécifications H800. Il est actuellement déployé sur une machine H800 à 8 cartes. Le débit d'entrée dépasse 100 000 jetons par seconde et la sortie dépasse 50 000 jetons par seconde.
 Pictures
Pictures
Sur certains Benchmarks de base, les performances du modèle de base DeepSeek-V2 sont les suivantes :
 Pictures
Pictures
DeepSeek-V2 adopte une architecture innovante.
Proposition d'architecture MLA (Multi-head Latent Attention) pour réduire considérablement la quantité de mémoire de calcul et d'inférence.
En parallèle, nous avons développé nous-mêmes la structure Sparse pour réduire encore davantage le montant du calcul.
 Photos
Photos
Certaines personnes ont déclaré que ces mises à niveau pourraient être très utiles pour l'informatique à grande échelle dans les centres de données.
 Photos
Photos
Et en termes de prix API, DeepSeek-V2 est presque inférieur à tous les modèles stars du marché.
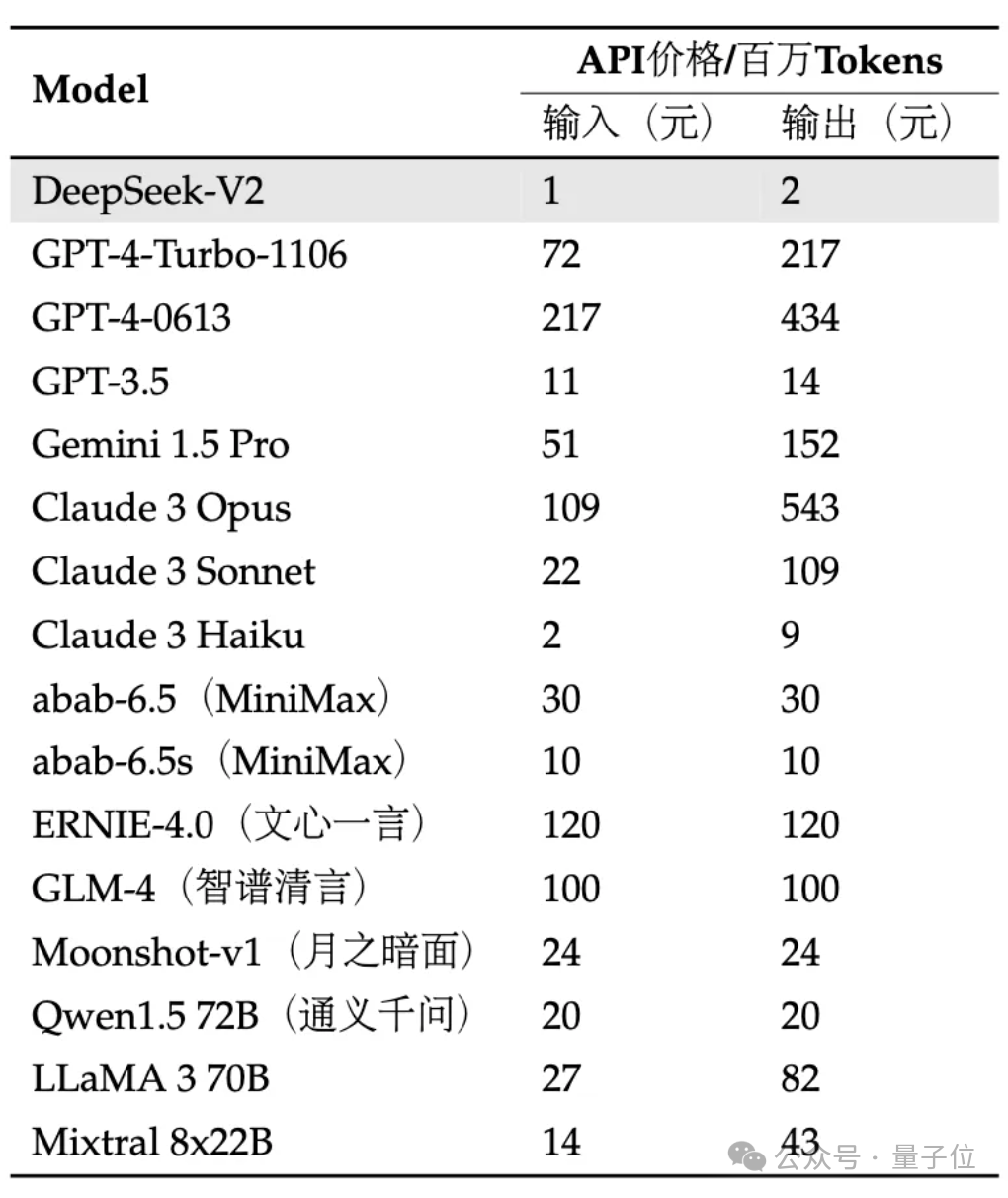 Photos
Photos
L'équipe a déclaré que le modèle et le papier DeepSeek-V2 seront également entièrement open source. Les poids des modèles et les rapports techniques sont fournis.
Connectez-vous dès maintenant à la plateforme ouverte de l'API DeepSeek et inscrivez-vous pour recevoir 10 millions de jetons d'entrée/5 millions de sortie en cadeau. L’essai normal est entièrement gratuit.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!