
Maison >Périphériques technologiques >IA >58 lignes de code échelle Llama 3 à 1 million de contextes, toute version affinée est applicable
58 lignes de code échelle Llama 3 à 1 million de contextes, toute version affinée est applicable

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-05-06 18:10:081346parcourir
Llama 3, le majestueux roi de l'open source, fenêtre de contexte originale n'a en fait que... 8k, ce qui m'a fait ravaler les mots "ça sent si bon".
À partir de 32k, 100k est courant aujourd'hui. Est-ce intentionnel de laisser de la place aux contributions à la communauté open source ?
La communauté open source n'a certainement pas manqué cette opportunité :
Désormais, avec seulement 58 lignes de code, toute version affinée de Llama 3 70b peut automatiquement évoluer jusqu'à 1048k (un million) contexte.
Derrière se trouve un LoRA, extrait d'une version affinée de Llama 3 70B Instruct qui étend un bon contexte, Le fichier ne fait que 800 Mo.
Ensuite, en utilisant Mergekit, vous pouvez l'exécuter avec d'autres modèles de la même architecture ou le fusionner directement dans le modèle.
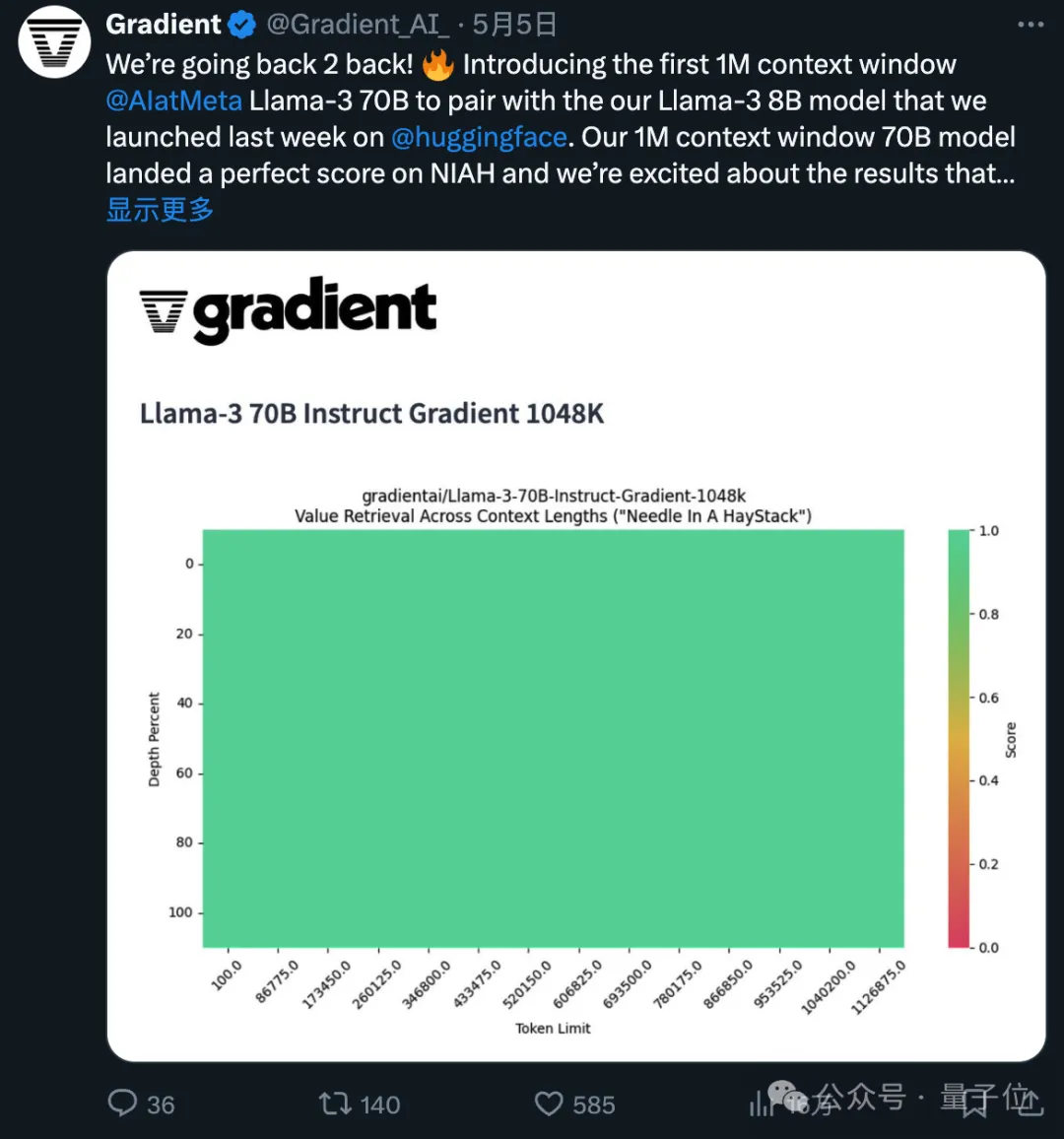
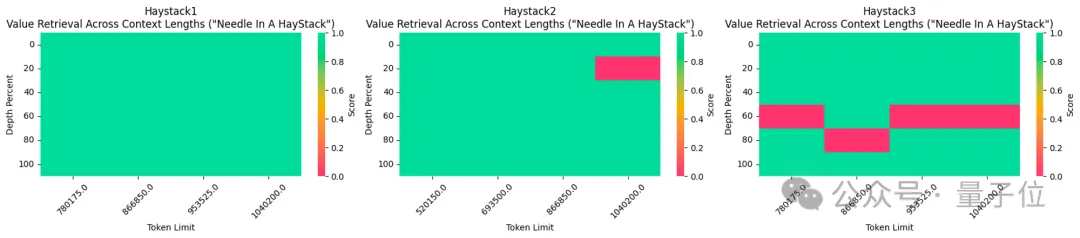
La version affinée du contexte 1048k utilisé vient d'obtenir un score entièrement vert (100 % de précision) au populaire test de l'aiguille dans une botte de foin.
Je dois dire que la vitesse de progression de l'open source est exponentielle.
Comment la LoRA contextuelle 1048k a été créée
Tout d'abord, la version contextuelle 1048k du modèle affiné de Llama 3 provient de Gradient AI, une startup de solutions d'IA d'entreprise.

La LoRA correspondante provient du développeur Eric Hartford En comparant les différences entre le modèle affiné et la version originale, les modifications des paramètres sont extraites.
Il a d'abord produit une version contextuelle 524k, puis a mis à jour la version 1048k.
Tout d'abord, l'équipe Gradient a continué sa formation basée sur le Llama 3 70B Instruct original et a obtenu Llama-3-70B-Instruct-Gradient-1048k.
La méthode spécifique est la suivante :
- Ajuster l'encodage de position : Utilisez l'interpolation compatible NTK pour initialiser la planification optimale de RoPE theta et l'optimiser pour éviter la perte d'informations haute fréquence après l'extension de la length
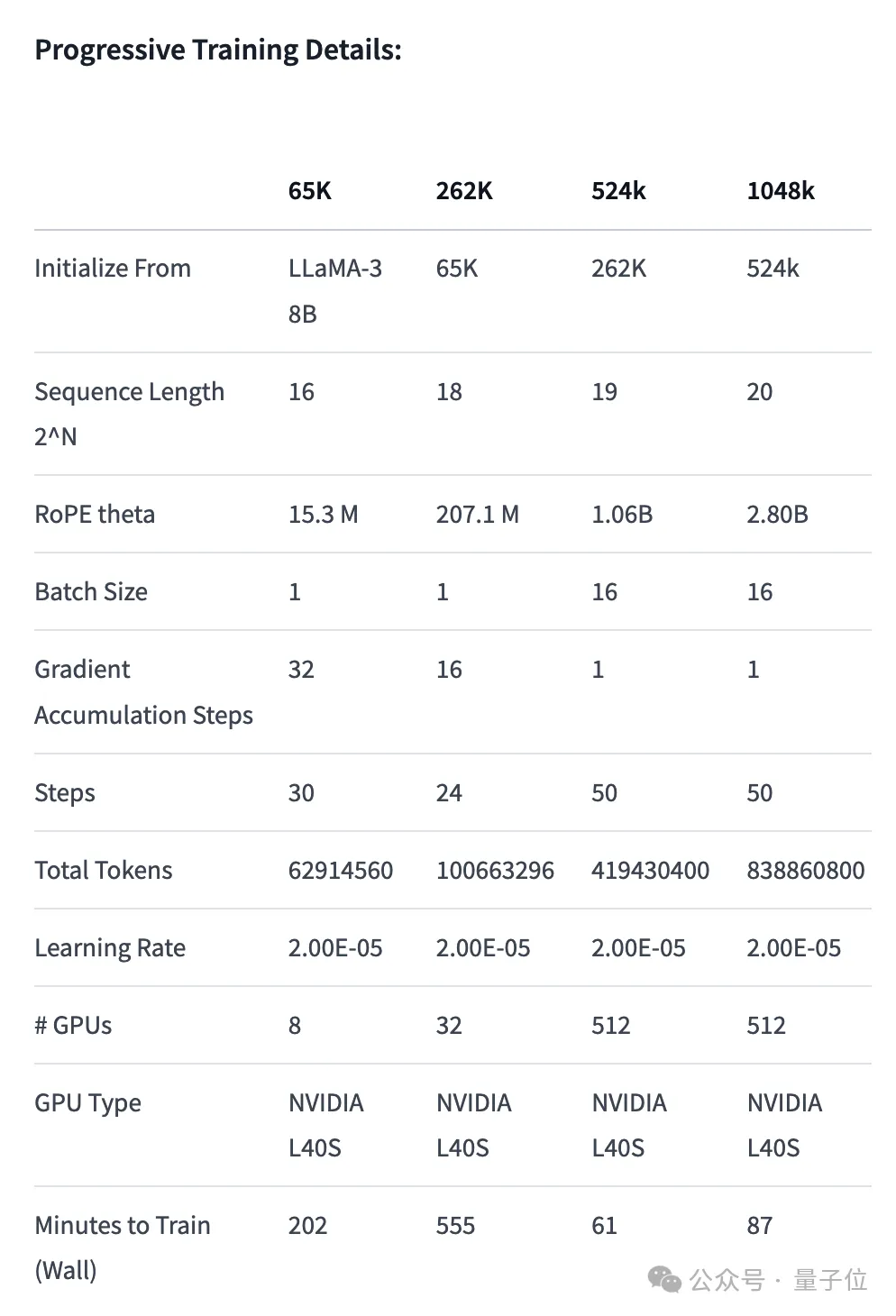
- Formation progressive : Utilisez la méthode Blockwise RingAttention proposée par l'équipe Pieter Abbeel de l'UC Berkeley pour étendre la longueur du contexte du modèle
Il convient de noter que l'équipe a superposé la parallélisation au-dessus de Ring Attention grâce à une topologie de réseau personnalisée pour mieux utiliser les clusters GPU à grande échelle, ils sont utilisés pour gérer les goulots d'étranglement du réseau causés par le transfert de nombreux blocs KV entre appareils.
En fin de compte, la vitesse d'entraînement du modèle est augmentée de 33 fois.
Dans l'évaluation des performances de récupération de texte long, uniquement dans la version la plus difficile, des erreurs sont susceptibles de se produire lorsque « l'aiguille » est cachée au milieu du texte.

Après avoir affiné le modèle avec un contexte étendu, utilisez l'outil open source Mergekit pour comparer le modèle affiné et le modèle de base, et extraire la différence de paramètres pour devenir LoRA.
En utilisant également Mergekit, vous pouvez fusionner la LoRA extraite dans d'autres modèles avec la même architecture.
Le code de fusion est également open source sur GitHub par Eric Hartford et ne fait que 58 lignes.
On ne sait pas si cette fusion LoRA fonctionnera avec Llama 3, qui est affiné sur le chinois.
Cependant, on constate que la communauté des développeurs chinois a prêté attention à ce développement.
Version 524k LoRA : https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-524k-adapter
Version 1048k LoRA : https://huggingface.co/ cognitivecomputations/Llama-3-70B-Gradient-1048k-adapter
Code de fusion : https://gist.github.com/ehartford/731e3f7079db234fa1b79a01e09859ac
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!