
Maison >Périphériques technologiques >IA >CVPR 2024 | Avec l'aide de la lumière structurée neuronale, l'Université du Zhejiang réalise l'acquisition et la reconstruction en temps réel de phénomènes tridimensionnels dynamiques
CVPR 2024 | Avec l'aide de la lumière structurée neuronale, l'Université du Zhejiang réalise l'acquisition et la reconstruction en temps réel de phénomènes tridimensionnels dynamiques

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-05-06 14:50:14960parcourir

La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com.
La reconstruction efficace et de haute qualité de phénomènes physiques dynamiques tridimensionnels tels que la fumée est une question importante dans la recherche scientifique connexe. Elle a de larges perspectives d'application dans la vérification de la conception aérodynamique, l'observation météorologique tridimensionnelle et d'autres domaines. En reconstruisant collectivement des séquences de densité tridimensionnelles qui changent au fil du temps, les scientifiques peuvent mieux comprendre et vérifier divers phénomènes physiques complexes dans le monde réel.

La figure 1 montre l'importance de l'observation de phénomènes physiques dynamiques tridimensionnels pour la recherche scientifique. La photo montre la plus grande soufflerie au monde, la NFAC, menant des expériences aérodynamiques sur des entités de camions commerciaux.
Cependant, il est assez difficile d'acquérir et de reconstruire rapidement des champs de densité 3D dynamiques de haute qualité dans le monde réel. Premièrement, les informations tridimensionnelles sont difficiles à mesurer directement via des capteurs d’images bidimensionnels courants (tels que des caméras). De plus, les phénomènes dynamiques changeants à grande vitesse imposent des exigences élevées aux capacités d'acquisition physique : un échantillonnage complet d'un seul champ de densité tridimensionnel doit être intercepté dans un laps de temps très court, sinon le champ de densité tridimensionnel lui-même changera. Le défi fondamental ici est de savoir comment résoudre le manque d’informations entre l’échantillon de mesure lui-même et les résultats de reconstruction dynamique du champ de densité tridimensionnelle.
Les travaux de recherche traditionnels actuels utilisent des connaissances préalables pour compenser le manque d'informations dans les échantillons de mesure. Le coût de calcul est élevé et la qualité de la reconstruction est médiocre lorsque les conditions préalables ne sont pas remplies. Contrairement aux idées de recherche dominantes, l'équipe de recherche du Laboratoire national clé de conception et de systèmes graphiques assistés par ordinateur de l'Université du Zhejiang estime que la clé pour résoudre le problème réside dans l'augmentation du contenu informatif de l'échantillon de mesure unitaire.
L'équipe de recherche utilise non seulement l'IA pour optimiser l'algorithme de reconstruction, mais utilise également l'IA pour aider à concevoir des méthodes de collecte physique afin d'obtenir une optimisation conjointe logicielle et matérielle entièrement automatique motivée par le même objectif, augmentant essentiellement la quantité d'informations sur l'objet cible. dans l’échantillon de mesure unitaire. En simulant des phénomènes optiques physiques dans le monde réel, l’intelligence artificielle peut décider comment projeter une lumière structurée, comment collecter les images correspondantes et comment reconstruire un champ de densité tridimensionnel dynamique à partir du livre d’échantillons. En fin de compte, l'équipe de recherche n'a utilisé qu'un prototype matériel léger contenant un seul projecteur et un petit nombre de caméras (1 ou 3) pour réduire le nombre de modèles de lumière structurés afin de modéliser un seul champ de densité tridimensionnel (résolution spatiale 128x128x128). à 6, permettant d'obtenir un ensemble d'acquisition efficace de 40 champs de densité tridimensionnels par seconde.
L'équipe a proposé de manière innovante un décodeur unidimensionnel léger dans l'algorithme de reconstruction, utilisant la lumière d'entrée locale dans le cadre de l'entrée du décodeur et partageant les paramètres du décodeur sous différents matériaux capturés par différentes caméras, réduisant considérablement la complexité du réseau. améliorer la vitesse de calcul. Afin de fusionner les résultats de décodage de différentes caméras, un réseau de fusion 3D U-Net avec une structure simple est conçu. La reconstruction finale d'un seul champ de densité tridimensionnelle ne prend que 9,2 millisecondes. Par rapport aux travaux de recherche SOTA, la vitesse de reconstruction est augmentée de 2 à 3 ordres de grandeur, permettant ainsi une reconstruction de haute qualité en temps réel du champ de densité tridimensionnelle. . Le document de recherche connexe « Acquisition et reconstruction en temps réel de volumes dynamiques avec éclairage structuré neuronal » a été accepté par CVPR 2024, la plus grande conférence universitaire internationale dans le domaine de la vision par ordinateur.

Lien papier : https://svbrdf.github.io/publications/realtimedynamic/realtimedynamic.pdf
Page d'accueil de la recherche : https://svbrdf.github.io/publications/realtimedynamic/project. html


Les travaux connexes peuvent être divisés en deux catégories suivantes selon que l'éclairage est contrôlé ou non pendant le processus de collecte.
Le premier type de travail basé sur un éclairage non contrôlable ne nécessite pas de source de lumière spéciale et ne contrôle pas l'éclairage pendant le processus de collecte, les exigences relatives aux conditions de collecte sont donc plus souples [2,3]. Puisqu’une caméra à vue unique capture une projection bidimensionnelle d’une structure tridimensionnelle, il est difficile de distinguer différentes structures tridimensionnelles avec une qualité élevée. À cet égard, une idée consiste à augmenter le nombre d’échantillons d’angles de vue collectés, par exemple en utilisant des réseaux de caméras denses ou des caméras à champ lumineux, ce qui entraînerait des coûts matériels élevés. Une autre idée consiste toujours à échantillonner de manière clairsemée le domaine de perspective et à combler le manque d'informations grâce à divers types d'informations préalables, telles que les a priori heuristiques, les règles physiques ou les connaissances préalables apprises à partir de données existantes. Une fois que les conditions a priori ne sont pas remplies en pratique, la qualité des résultats de reconstruction de ce type de méthode va se détériorer. De plus, sa charge de calcul est trop coûteuse pour prendre en charge une reconstruction en temps réel.
Le deuxième type de travail utilise un éclairage contrôlable pour contrôler activement les conditions d'éclairage pendant le processus de collecte [4,5]. Un tel travail code l'éclairage pour sonder plus activement le monde physique et s'appuie également moins sur les a priori, ce qui se traduit par une qualité de reconstruction supérieure. Selon qu'une seule lampe ou plusieurs lampes sont utilisées simultanément, les travaux associés peuvent être classés en méthodes de balayage et en méthodes de multiplexage d'éclairage. Pour les objets physiques dynamiques, les premiers doivent atteindre des vitesses de numérisation élevées en utilisant du matériel coûteux, ou sacrifier l'intégrité des résultats pour réduire la charge d'acquisition. Ce dernier améliore considérablement l’efficacité de la collecte en programmant simultanément plusieurs sources lumineuses. Cependant, pour les champs de densité en temps réel rapides de haute qualité, l’efficacité d’échantillonnage des méthodes existantes est encore insuffisante [5].
Les travaux de l'équipe de l'Université du Zhejiang appartiennent à la deuxième catégorie. Différent de la plupart des travaux existants, ces travaux de recherche utilisent l’intelligence artificielle pour optimiser conjointement l’acquisition physique (c’est-à-dire la lumière structurée neuronale) et la reconstruction informatique, obtenant ainsi une modélisation dynamique de champ de densité tridimensionnelle efficace et de haute qualité.
Prototype matériel
L'équipe de recherche a construit un seul projecteur commercial (BenQ X3000 : résolution 1920×1080, vitesse 240 ips) et trois caméras industrielles (Basler acA1440-220umQGR : résolution 1440×1080, vitesse 240 ips) Un prototype matériel simple (illustré à la figure 3). Six modèles de lumière structurée pré-entraînés sont projetés de manière cyclique à travers le projecteur, et trois caméras filment simultanément, et une reconstruction dynamique du champ de densité tridimensionnelle est effectuée sur la base des images collectées par les caméras. Les angles des quatre dispositifs par rapport à l'objet de collection sont les dispositions optimales sélectionnées après des simulations issues de différentes expériences de simulation.
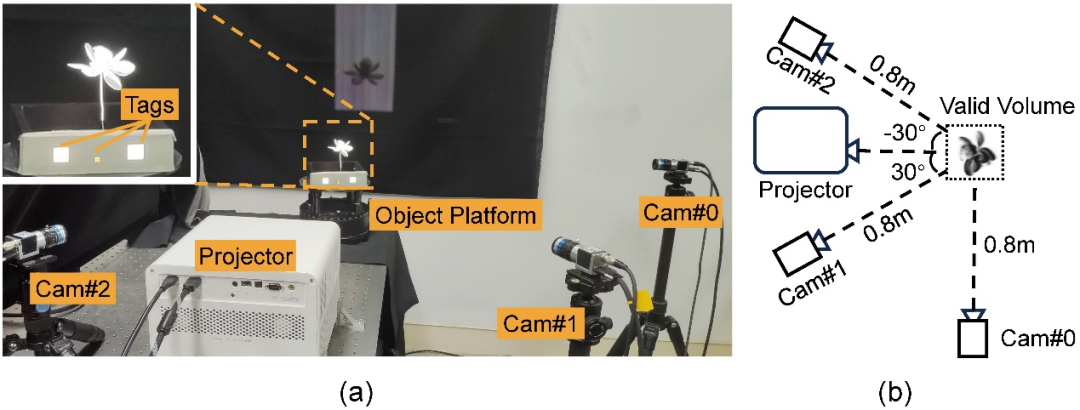
Figure 3 : Prototype de matériel de collection. (a) Prise de vue réelle du prototype matériel, avec trois tags blancs sur la scène utilisés pour synchroniser la caméra et le projecteur. (b) Diagramme schématique de la relation géométrique entre la caméra, le projecteur et le sujet (vue de dessus).
Traitement logiciel
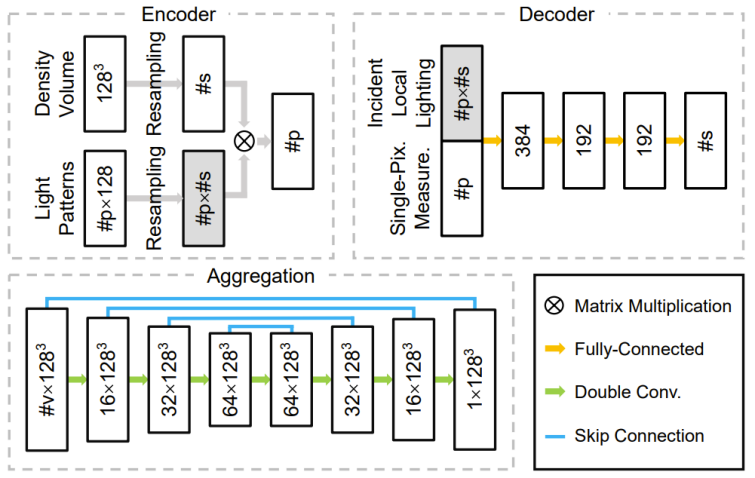
L'équipe R&D conçoit un réseau de neurones profond composé d'encodeurs, de décodeurs et de modules d'agrégation. Les poids dans son codeur correspondent directement à la distribution structurée de l'intensité lumineuse lors de l'acquisition. Le décodeur prend en entrée un échantillon mesuré sur un seul pixel, prédit une distribution de densité unidimensionnelle et l'interpole dans un champ de densité tridimensionnel. Le module d'agrégation combine les multiples champs de densité tridimensionnelle prédits par le décodeur correspondant à chaque caméra dans le résultat final. En utilisant une lumière structurée entraînable et un décodeur unidimensionnel léger, cette étude peut apprendre plus facilement la relation essentielle entre les modèles de lumière structurée, les photos bidimensionnelles et les champs de densité tridimensionnels, ce qui la rend moins susceptible de surajuster les données d'entraînement. . La figure 4 ci-dessous montre le pipeline global et la figure 5 montre la structure du réseau pertinente.

Figure 4 : Pipeline global d'acquisition et de reconstruction (a), et retraitement d'un motif de lumière structuré à une lumière incidente locale unidimensionnelle (b) et de la distribution de densité unidimensionnelle prévue à une lumière tridimensionnelle. champ de densité dimensionnelle (c) processus d'échantillonnage. L'étude commence par un champ de densité tridimensionnelle simulé/réel sur lequel des modèles de lumière structurés pré-optimisés (c'est-à-dire des poids dans l'encodeur) sont d'abord projetés. Pour chaque pixel valide dans chaque vue de caméra, toutes ses mesures et la lumière incidente locale rééchantillonnée sont transmises au décodeur pour prédire la distribution de densité unidimensionnelle sur le rayon de caméra correspondant. Toutes les distributions de densité d'une caméra sont ensuite collectées et rééchantillonnées dans un seul champ de densité tridimensionnel. Dans le cas multi-caméras, cette étude fusionne les champs de densité prédits de chaque caméra pour obtenir le résultat final. Figure 5 : Architecture des 3 composants principaux du réseau : encodeur, décodeur et module d'agrégation.
 Affichage des résultats
Affichage des résultats
La figure 6 montre les résultats de reconstruction partielle de cette méthode pour quatre scènes dynamiques différentes. Pour générer un brouillard d'eau dynamique, les chercheurs ont ajouté de la neige carbonique aux bouteilles contenant de l'eau liquide pour créer un brouillard d'eau, ont contrôlé le débit à travers des vannes et ont utilisé des tubes en caoutchouc pour le guider plus loin vers le dispositif de collecte. Figure 6 : Résultats de reconstruction de différentes scènes dynamiques. Chaque ligne est le résultat de la visualisation d'une partie sélectionnée de l'image reconstruite dans une certaine séquence de brouillard d'eau. Le nombre de sources de brouillard d'eau dans la scène de haut en bas est : 1, 1, 3 et 2 respectivement. Comme le montre la marque orange en haut à gauche, A, B et C correspondent respectivement aux images collectées par les trois caméras d'entrée, et D est une image de référence réelle similaire à la perspective de rendu du résultat de la reconstruction. L'horodatage est affiché dans le coin inférieur gauche. Pour des résultats détaillés de reconstruction dynamique, veuillez consulter la vidéo papier. Afin de vérifier l'exactitude et la qualité de cette recherche, l'équipe de recherche a comparé cette méthode avec les méthodes SOTA associées sur des objets statiques réels (comme le montre la figure 7). La figure 7 compare également la qualité de la reconstruction sous différents numéros de caméra. Tous les résultats de reconstruction sont tracés sous la même nouvelle perspective non acquise et évalués quantitativement par trois mesures d'évaluation. Comme le montre la figure 7, grâce à l'optimisation de l'efficacité d'acquisition, la qualité de reconstruction de cette méthode est meilleure que celle de la méthode SOTA. Figure 7 : Comparaison de différentes techniques sur des objets statiques réels. De gauche à droite se trouve la méthode de découpe de couche optique [4], cette méthode (trois caméras), cette méthode (double caméra), cette méthode (une seule caméra), utilisant une lumière structurée conçue manuellement sous une seule caméra [5], le PINF de SOTA. Visualisation des résultats de reconstruction des méthodes [3] et GlobalTrans [2]. En prenant les résultats de la tranche optique comme référence, et pour tous les autres résultats, leurs erreurs quantitatives sont répertoriées dans le coin inférieur droit des images correspondantes, évaluées avec trois métriques SSIM/PSNR/RMSE (×0,01). Tous les champs de densité reconstruits sont rendus à l'aide de vues sans entrée, #v représente le nombre de vues acquises et #p représente le nombre de modèles de lumière structurés utilisés. L'équipe de recherche a également comparé quantitativement la qualité de reconstruction de différentes méthodes sur des données de simulation dynamique. La figure 8 montre la comparaison de la qualité de reconstruction des séquences de fumée simulées. Pour des résultats détaillés de reconstruction image par image, veuillez consulter la vidéo papier. Figure 8 : Comparaison de différentes méthodes sur des séquences de fumée simulées. De gauche à droite se trouvent les valeurs réelles, résultats de reconstruction de cette méthode, PINF [3] et GlobalTrans [2]. Les résultats de rendu de la vue d'entrée et de la nouvelle vue sont affichés respectivement dans les première et deuxième lignes. L'erreur quantitative SSIM/PSNR/RMSE (×0,01) est affichée dans le coin inférieur droit de l'image correspondante. Pour l’erreur moyenne de l’ensemble de la séquence reconstruite, veuillez vous référer au matériel supplémentaire de l’article. De plus, veuillez consulter la vidéo papier pour les résultats de la reconstruction dynamique de l’ensemble de la séquence. Future Outlook L'équipe de recherche prévoit d'appliquer cette méthode sur des équipements d'acquisition plus avancés (tels que les projecteurs de champ lumineux [6]) pour réaliser une reconstruction d'acquisition dynamique. L’équipe espère également réduire davantage le nombre de modèles de lumière structurée et de caméras requis pour la collecte en collectant des informations optiques plus riches (telles que l’état de polarisation). De plus, combiner cette méthode avec des expressions neuronales (telles que NeRF) est également l’une des futures orientations de développement qui intéresse l’équipe. Enfin, permettre à l’IA d’être impliquée plus activement dans la conception de l’acquisition physique et de la reconstruction informatique, sans se limiter aux logiciels de post-traitement, pourrait fournir de nouvelles idées pour améliorer davantage les capacités de perception physique et, à terme, parvenir à une modélisation efficace et de haute qualité de différents éléments. phénomènes physiques complexes. Références : [1]. À l'intérieur de la plus grande soufflerie du monde https://youtu.be/ubyxYHFv2qw?si=KK994cXtARP3Atwn [2]. haler , et Nils Thuerey. Transport mondial pour une reconstruction fluide avec autosupervision apprise, pages 1632-1642, 2021. [3]. Mengyu Chu, Lingjie Liu, Quan Zheng, Erik Franz, HansPeter Seidel, Christian. Theobalt et Rhaleb Zayer. Physics a informé les champs neuronaux pour la reconstruction de la fumée avec des données éparses, 41 (4) : 1–14, 2022. [4]. Paul Debevec. Acquisition de médias participants variant dans le temps ACM Transactions on Graphics, 24 (3): 812–815, 2005. [5]. . Belhumeur et Ravi Ramamoorthi. Lumière structurée compressive pour récupérer des médias participants inhomogènes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35 (3): 1–1, 2013. [6]. Lin, Haoyang Zhou, Chong Zeng, Yaxin Yu, Kun Zhou et Hongzhi Wu. Une lumière structurée spatiale-angulaire unifiée pour l'acquisition d'une vue unique de la forme et de la réflectance. Dans CVPR, pages 206-215, 2023.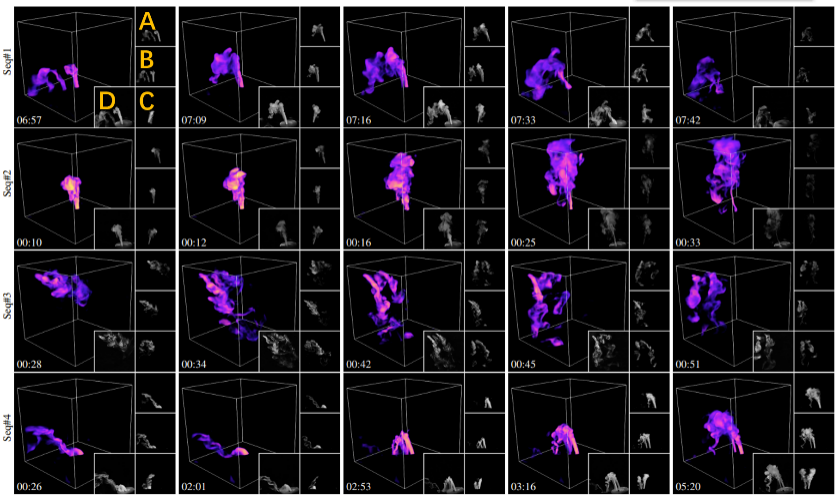


Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!