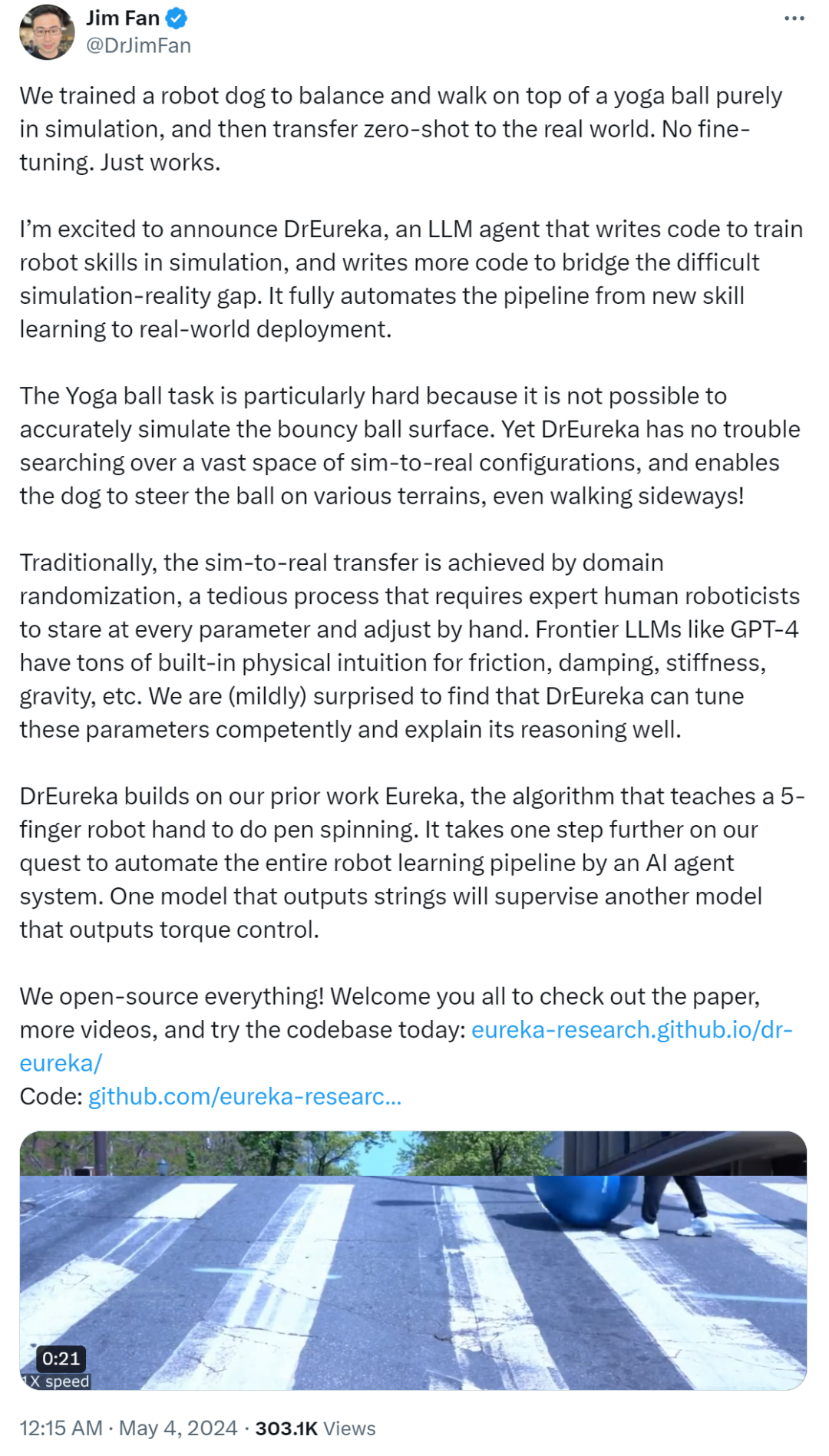
Le chien robot marche régulièrement sur la balle de yoga et son équilibre est assez bon : 
Il peut gérer diverses scènes, qu'il s'agisse d'un trottoir plat ou d'une pelouse difficile, il peut tenir :
Même lorsque les chercheurs frappaient une balle de yoga, le chien robot ne se renversait pas :
Le chien robot pouvait également maintenir l'équilibre lors du dégonflage des ballons :
Les démonstrations ci-dessus sont toutes à une vitesse 1x, sans traitement d'accélération.
- Adresse papier : https://eureka-research.github.io/dr-eureka/assets/dreureka-paper.pdf
- Page d'accueil du projet : https://github.com/eureka- Research/DrEureka
- Titre de l'article : DrEureka : Language Model Guided Sim-To-Real Transfer
Cette recherche a été créée conjointement par des chercheurs de l'Université de Pennsylvanie, de NVIDIA et de l'Université du Texas à Austin. , et est entièrement open source . Ils ont proposé DrEureka (Domain Randomized Eureka), un nouvel algorithme qui utilise LLM pour mettre en œuvre une conception de récompense et une configuration de paramètres aléatoires de domaine, qui peut simultanément réaliser un transfert de simulation à la réalité. L'étude démontre la capacité de l'algorithme DrEureka à résoudre de nouvelles tâches robotiques, telles que l'équilibrage d'un robot quadrupède et la marche sur un ballon de yoga, sans avoir recours à une conception manuelle itérative. Dans la section des résumés de l'article, les chercheurs ont déclaré que le transfert des stratégies apprises lors des simulations vers le monde réel est une stratégie prometteuse pour l'acquisition à grande échelle de compétences robotiques. Cependant, les approches de simulation à la réalité reposent souvent sur la conception et le réglage manuels des fonctions de récompense des tâches et des paramètres physiques de simulation, ce qui rend le processus lent et fastidieux. Cet article examine l'utilisation de grands modèles de langage (LLM) pour automatiser et accélérer la simulation jusqu'à une conception réaliste. Jim Fan, l'un des auteurs de l'article et scientifique principal chez NVIDIA, a également participé à cette recherche. Auparavant, NVIDIA avait créé un laboratoire d'IA, dirigé par Jim Fan, spécialisé dans l'intelligence embarquée. Jim Fan a déclaré : « Nous avons entraîné un chien robot à s'équilibrer et à marcher sur une balle de yoga. Cela a été entièrement réalisé en simulation, puis transféré dans le monde réel avec zéro échantillon, sans réglage fin, et exécuté directement. La tâche de promener la balle de yoga est particulièrement difficile pour le chien robot car nous ne pouvons pas simuler avec précision la surface de la balle rebondissante. Cependant, DrEureka peut facilement rechercher un grand nombre de configurations réelles simulées et autoriser le chien robot. pour contrôler le ballon sur différents terrains, voire aller de côté ! De manière générale, la migration de la simulation à la réalité se fait grâce à la randomisation de domaine, qui est un processus fastidieux qui nécessite que des experts en robotique examinent chaque paramètre et manuellement. ajustez-le. 4 De tels LLM de pointe ont beaucoup d'intuition physique intégrée, notamment la friction, l'amortissement, la rigidité, la gravité, etc. Avec GPT-4, DrEureka peut habilement ajuster ces paramètres et bien expliquer son raisonnement 》
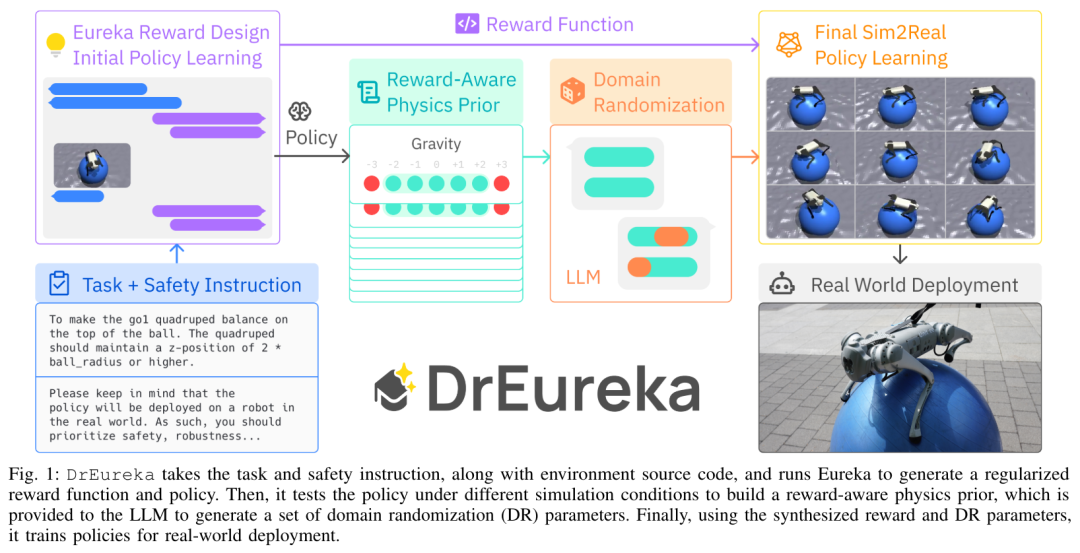
Le processus DrEureka est le suivant, qui accepte les instructions de tâche et de sécurité et le code source de l'environnement, et exécute Eureka pour générer des fonctions et des politiques de récompense régularisées. Il teste ensuite la stratégie dans différentes conditions de simulation pour construire un a priori physique sensible aux récompenses, qui est transmis à un LLM pour générer un ensemble de paramètres de randomisation de domaine (DR). Enfin, la politique est formée à l’aide des paramètres de récompense et de DR synthétisés pour le déploiement réel. Conception de récompense Eureka. Le composant de conception de récompense est basé sur Eureka en raison de sa simplicité et de son expressivité, mais cet article introduit quelques améliorations pour améliorer son applicabilité de la simulation aux environnements du monde réel. Le pseudocode est le suivant : Récompense consciente de la physique préalable (RAPP, récompense consciente de la physique préalable). Les fonctions de récompense de sécurité peuvent réguler le comportement politique pour fixer les choix environnementaux, mais ne suffisent pas à elles seules à réaliser le transfert de la simulation à la réalité. Par conséquent, cet article présente un mécanisme RAPP simple pour limiter la portée de base du LLM. LLM est utilisé pour la randomisation de domaine. Étant donné la plage RAPP pour chaque paramètre DR, la dernière étape de DrEureka demande à LLM de générer des configurations de randomisation de domaine dans les limites de la plage RAPP. Voir la figure 3 pour le processus spécifique : Cette recherche utilise Unitree Go1 pour les expériences. Go1 est un petit robot quadrupède avec 12 degrés de liberté dans ses quatre pattes. Dans la tâche de locomotion quadrupède, cet article évalue également systématiquement les performances des politiques DrEureka sur plusieurs terrains du monde réel et constate qu'elles restent robustes et surpassent les politiques formées à l'aide de configurations de récompense et de DR conçues par l'homme. Pour plus d'informations, veuillez vous référer au document original. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!