
Maison >Périphériques technologiques >IA >Enfin, quelqu'un a enquêté sur le surajustement des petits modèles : les deux tiers d'entre eux présentaient une pollution des données, et Microsoft Phi-3 et Mixtral 8x22B ont été nommés
Enfin, quelqu'un a enquêté sur le surajustement des petits modèles : les deux tiers d'entre eux présentaient une pollution des données, et Microsoft Phi-3 et Mixtral 8x22B ont été nommés

- 王林avant
- 2024-05-04 13:05:13701parcourir
L'amélioration des capacités de raisonnement des grands modèles de langage est l'une des directions les plus importantes de la recherche actuelle. Dans ce type de tâche, de nombreux petits modèles récemment publiés semblent bien fonctionner et peuvent bien gérer de telles tâches. Par exemple, le Phi-3 de Microsoft, le Mistral 8x22B et d'autres modèles.
Les chercheurs ont souligné qu'il existe un problème clé dans le domaine actuel de la recherche sur les grands modèles : de nombreuses études ne parviennent pas à évaluer avec précision les capacités des LLM existants. Cela suggère que nous devons consacrer plus de temps à évaluer et tester le niveau de capacité actuel du LLM.

C'est parce que la plupart des recherches actuelles utilisent des ensembles de tests tels que GSM8k, MATH, MBPP, HumanEval, SWEBench, etc. comme références. Étant donné que le modèle est formé sur un vaste ensemble de données extraites d'Internet, l'ensemble de données de formation peut contenir des échantillons très similaires aux questions du test de référence.
Ce type de contamination peut entraîner une sous-évaluation de la capacité de raisonnement du modèle - Ils peuvent simplement être confus par la question pendant le processus de formation et réciter la bonne réponse.
Tout à l'heure, un article de Scale AI a mené une enquête approfondie sur les grands modèles les plus populaires, notamment GPT-4 d'OpenAI, Gemini, Claude, Mistral, Llama, Phi, Abdin et d'autres séries avec différentes quantités de paramètres. . Modèle.
Les résultats des tests confirment un soupçon largement répandu : de nombreux modèles sont contaminés par des données de référence.
Titre de l'article : A Careful Examination of Large Language Model Performance on Grade School Arithmetic
Lien de l'article : https://arxiv.org/pdf/2405.00332
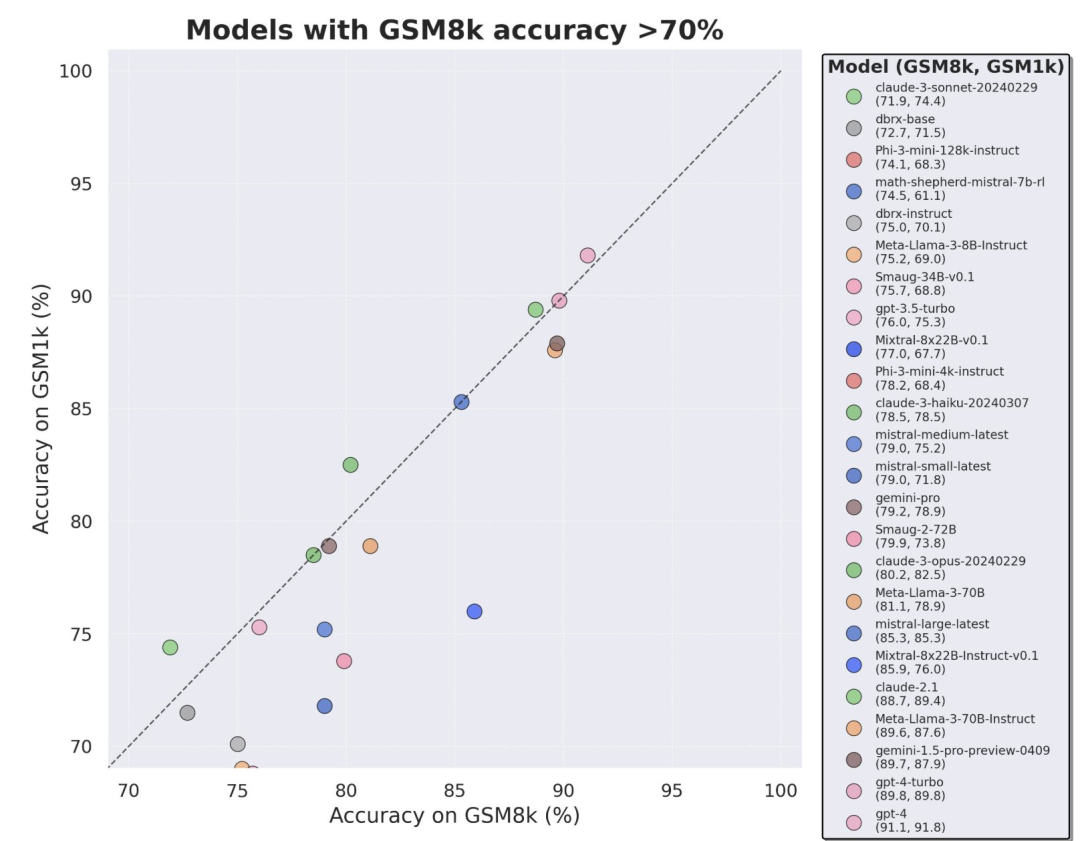
Afin d'éviter les données problèmes de pollution, les chercheurs de Scale AI n'ont utilisé aucun LLM ou autre source de données synthétiques et se sont entièrement appuyés sur l'annotation manuelle pour créer l'ensemble de données GSM1k. Semblable à GSM8k, GSM1k contient 1 250 problèmes mathématiques de niveau élémentaire. Afin de garantir des tests de référence équitables, les chercheurs ont fait de leur mieux pour garantir que la répartition des difficultés du GSM1k est similaire à celle du GSM8k. Sur GSM1k, les chercheurs ont comparé une série de modèles de langage à grande échelle open source et fermés et ont constaté que le modèle le moins performant avait des performances 13 % inférieures sur GSM1k par rapport à GSM8k.
En particulier les séries de modèles Mistral et Phi, connues pour leur petite quantité et leur haute qualité. Selon les résultats des tests du GSM1k, presque toutes les versions présentent des preuves cohérentes de surajustement.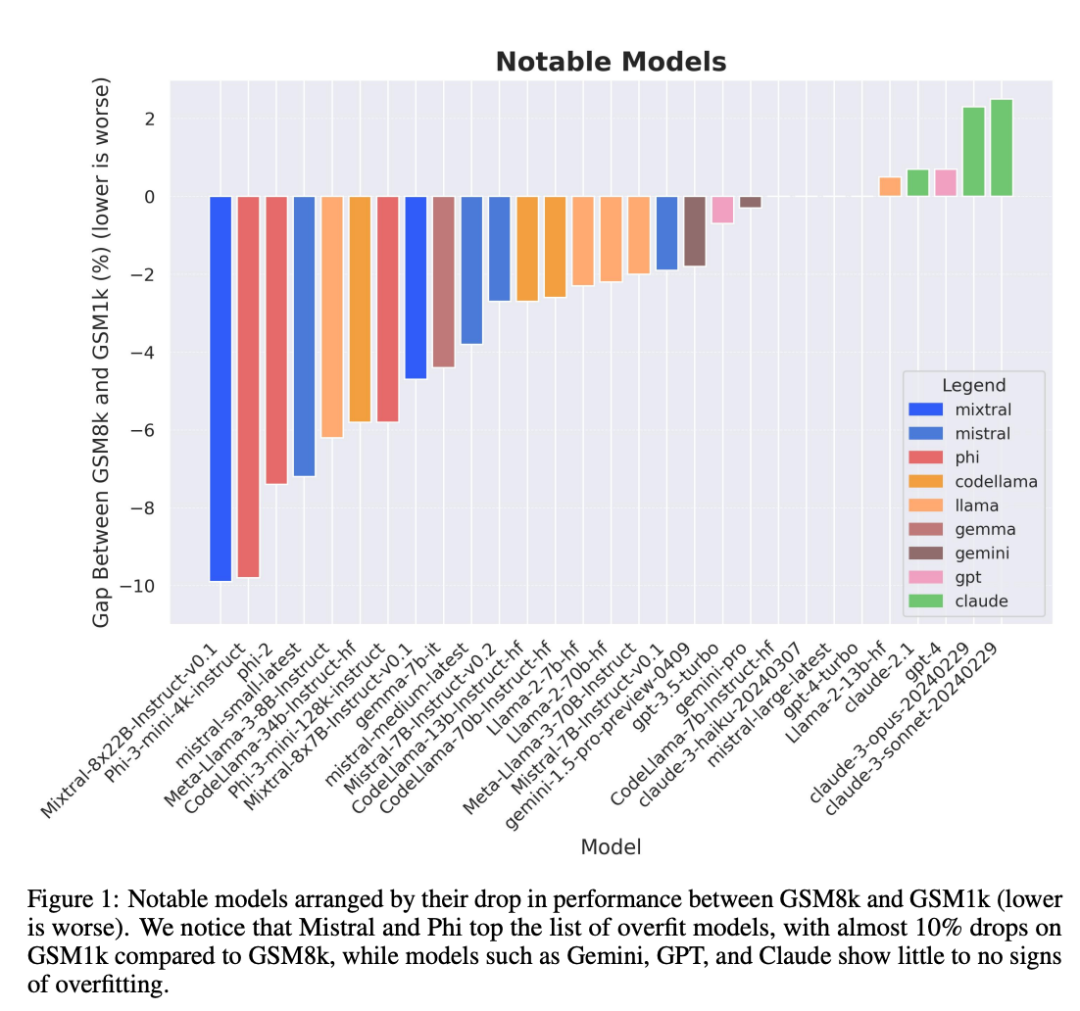
Cependant, les séries Gemini, GPT, Claude et Llama2 ont montré très peu de signes d'adaptation. De plus, tous les modèles, y compris le modèle le plus surajusté, étaient toujours capables de généraliser avec succès à de nouveaux problèmes de mathématiques à l'école primaire, bien que parfois avec des taux de réussite inférieurs à ceux indiqués par leurs données de base.

Ensemble de données GSM1k
GSM1k contient 1250 questions mathématiques pour l'école primaire. Ces problèmes peuvent être résolus uniquement avec un raisonnement mathématique de base. Scale AI a montré à chaque annotateur humain 3 exemples de questions de GSM8k et leur a demandé de poser de nouvelles questions de difficulté similaire, ce qui a abouti à l'ensemble de données GSM1k. Les chercheurs ont demandé aux annotateurs humains de ne pas utiliser de concepts mathématiques avancés et d'utiliser uniquement l'arithmétique de base (addition, soustraction, multiplication et division) pour formuler des questions. Comme GSM8k, les solutions à tous les problèmes sont des entiers positifs. Aucun modèle de langage n'a été utilisé dans la construction de l'ensemble de données GSM1k.
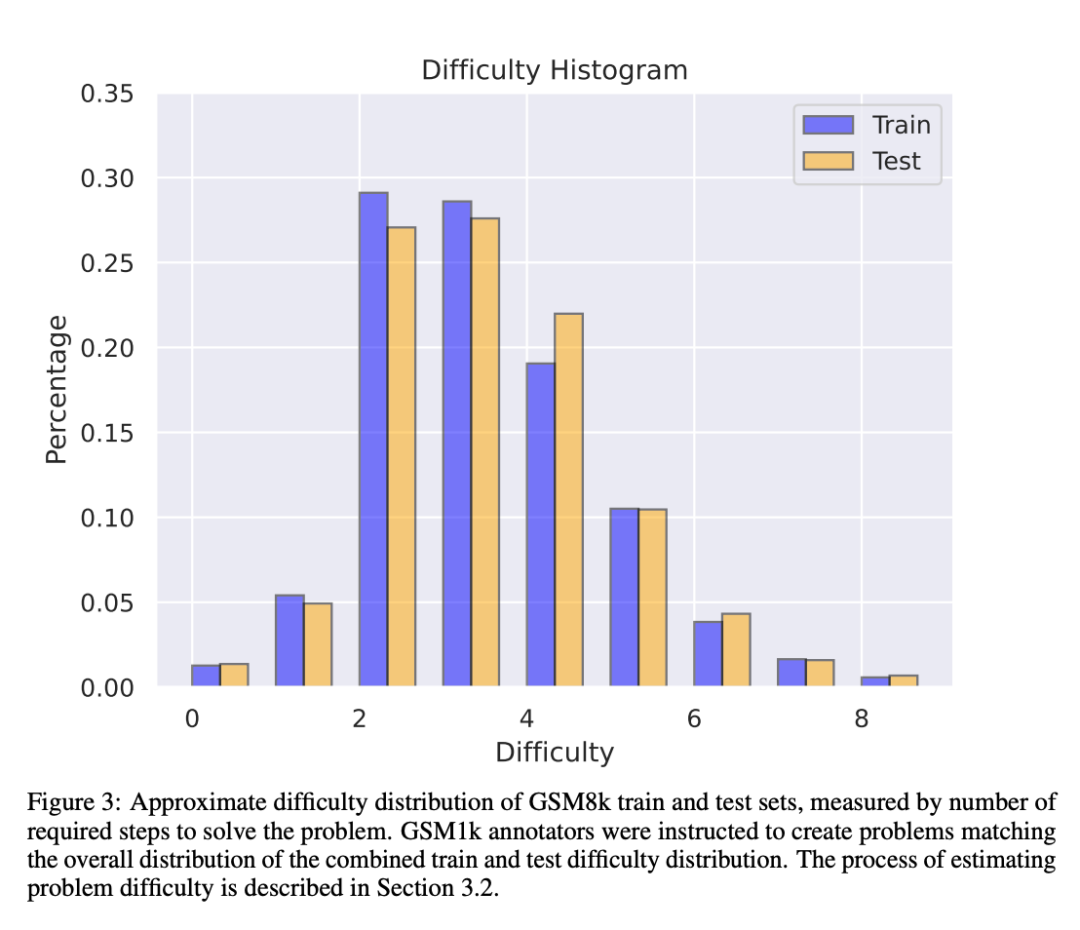
Pour éviter les problèmes de pollution des données avec l'ensemble de données GSM1k, Scale AI ne publiera pas l'ensemble de données pour le moment, mais ouvrira la source du cadre d'évaluation GSM1k, qui est basé sur le harnais d'évaluation LM d'EleutherAI.
Mais Scale AI promet : L'ensemble complet de données GSM1k sera publié sous la licence MIT une fois que l'une des deux conditions suivantes sera remplie en premier : (1) Il existe trois modèles open source basés sur différentes lignées de modèles de base pré-entraînées. Atteindre une précision de 95 % sur GSM1k (2) D’ici fin 2025. À ce stade, il est probable que les mathématiques à l’école primaire ne constitueront plus une référence valable pour évaluer les performances du LLM.
Afin d'évaluer des modèles propriétaires, les chercheurs publieront des ensembles de données via des API. La raison de cette approche de publication est que les auteurs estiment que les fournisseurs LLM n'utilisent généralement pas de points de données API pour former des modèles. Néanmoins, si les données GSM1k sont divulguées via l'API, les auteurs ont conservé des points de données qui n'apparaissent pas dans l'ensemble de données GSM1k final, et ces points de données de sauvegarde seront publiés avec GSM1k lorsque les conditions ci-dessus seront remplies.
Ils espèrent que les futures versions de référence suivront un schéma similaire - sans les publier publiquement dans un premier temps, mais en promettant de les publier à une date ultérieure ou lorsqu'une certaine condition sera remplie pour empêcher toute manipulation.
De plus, malgré les meilleurs efforts de Scale AI pour assurer une cohérence maximale entre GSM8k et GSM1k. Mais l'ensemble de test du GSM8k a été rendu public et largement utilisé pour les tests de modèles, donc GSM1k et GSM8k ne sont que des approximations dans des conditions idéales. Les résultats d'évaluation suivants sont obtenus lorsque les distributions de GSM8k et GSM1k ne sont pas exactement les mêmes.
Résultats de l'évaluation
Pour évaluer le modèle, les chercheurs ont utilisé la branche LM Evaluation Harness d'EleutherAI et ont utilisé les paramètres par défaut. Les invites en cours d'exécution pour les problèmes GSM8k et GSM1k sont les mêmes. Ils sélectionnent au hasard 5 échantillons dans l'ensemble d'apprentissage GSM8k, qui est également la configuration standard dans ce domaine (voir l'annexe B pour des informations complètes sur les invites).
Tous les modèles open source sont évalués à une température de 0 pour garantir la répétabilité. Le kit d'évaluation LM extrait la dernière réponse numérique de la réponse et la compare à la bonne réponse. Par conséquent, les réponses modèles qui produisent des réponses « correctes » dans un format qui ne correspond pas à l'échantillon seront marquées comme incorrectes.
Pour les modèles open source, si le modèle est compatible avec la bibliothèque, vLLM sera utilisé pour accélérer l'inférence du modèle, sinon la bibliothèque standard HuggingFace sera utilisée pour l'inférence par défaut. Les modèles à source fermée sont interrogés via la bibliothèque LiteLLM, qui unifie le format d'appel API pour tous les modèles propriétaires évalués. Tous les résultats du modèle d'API proviennent de requêtes effectuées entre le 16 et le 28 avril 2024 et utilisent les paramètres par défaut.
En ce qui concerne les modèles évalués, les chercheurs les ont sélectionnés en fonction de leur popularité et ont également évalué plusieurs modèles moins connus qui étaient bien classés sur OpenLLMLeaderboard.
Fait intéressant, les chercheurs ont trouvé des preuves de la loi de Goodhart dans le processus : de nombreux modèles ont obtenu des résultats bien moins bons sur GSM1k que sur GSM8k, ce qui suggère qu'ils répondaient principalement au benchmark GSM8k plutôt que d'améliorer réellement les capacités de raisonnement du modèle. Les performances de tous les modèles sont présentées à l’annexe D ci-dessous.
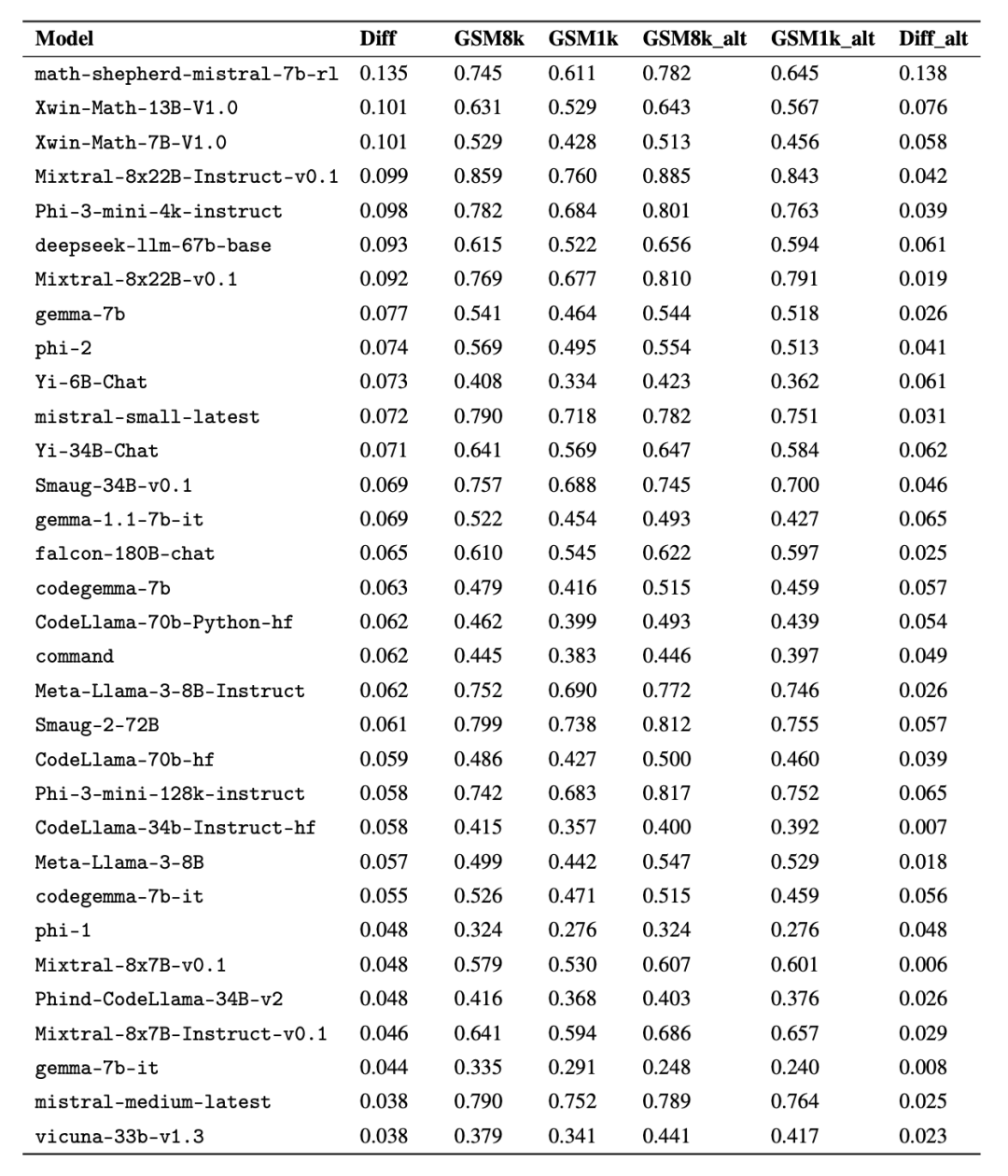
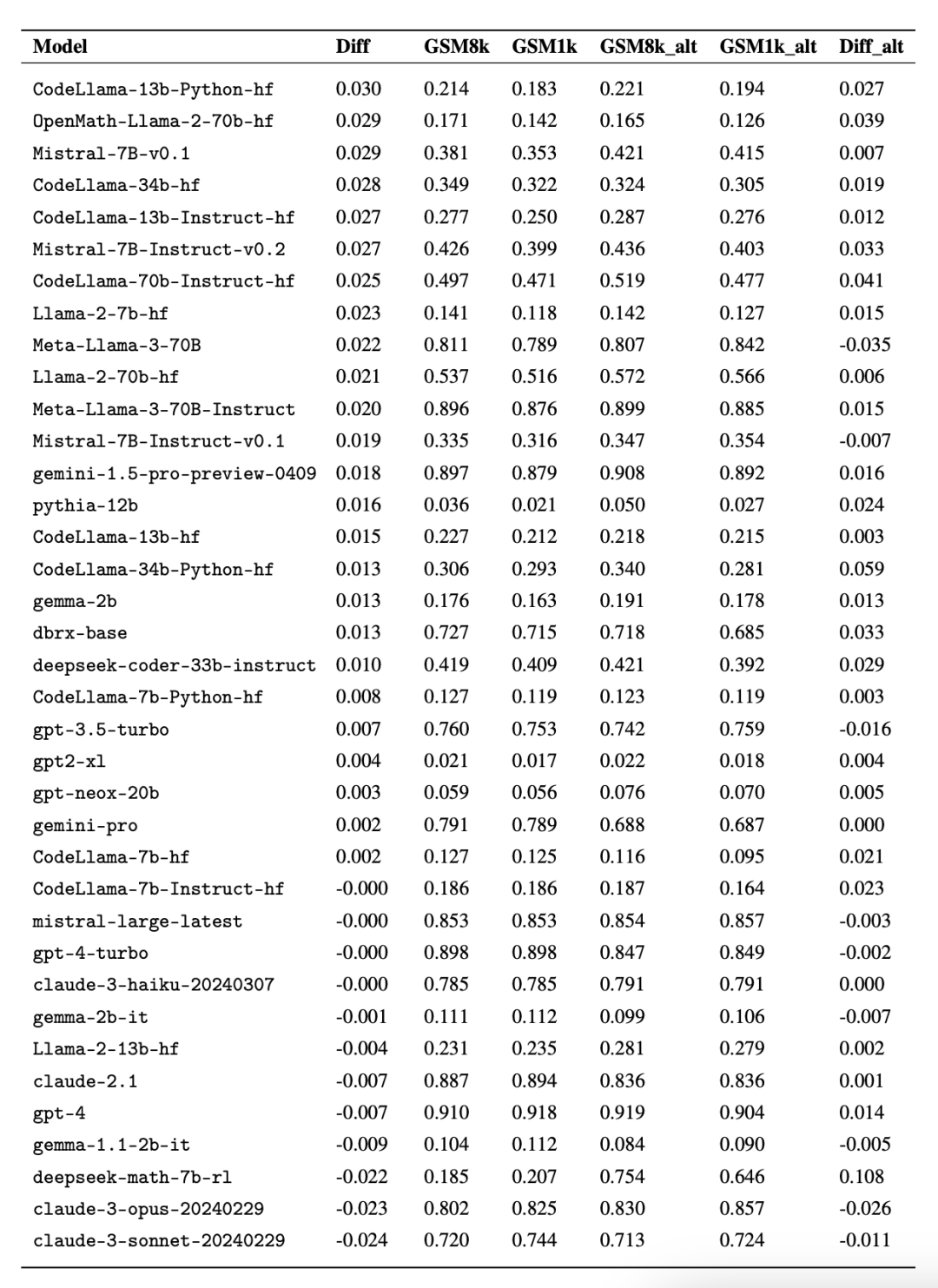
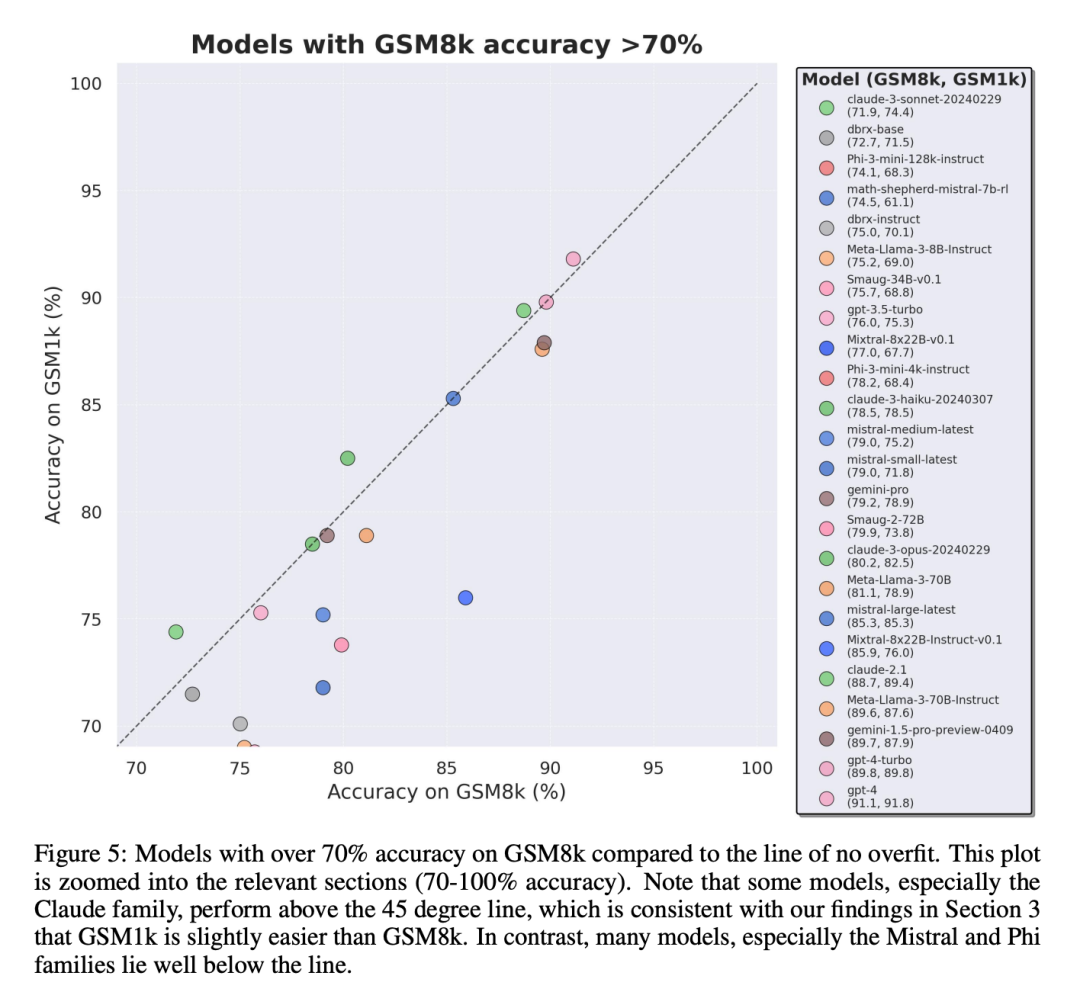
Afin de faire une comparaison équitable, les chercheurs ont divisé les modèles en fonction de leurs performances sur GSM8k et les ont comparés à d'autres modèles ayant des performances similaires (Figure 5, Figure 6, Figure 7).
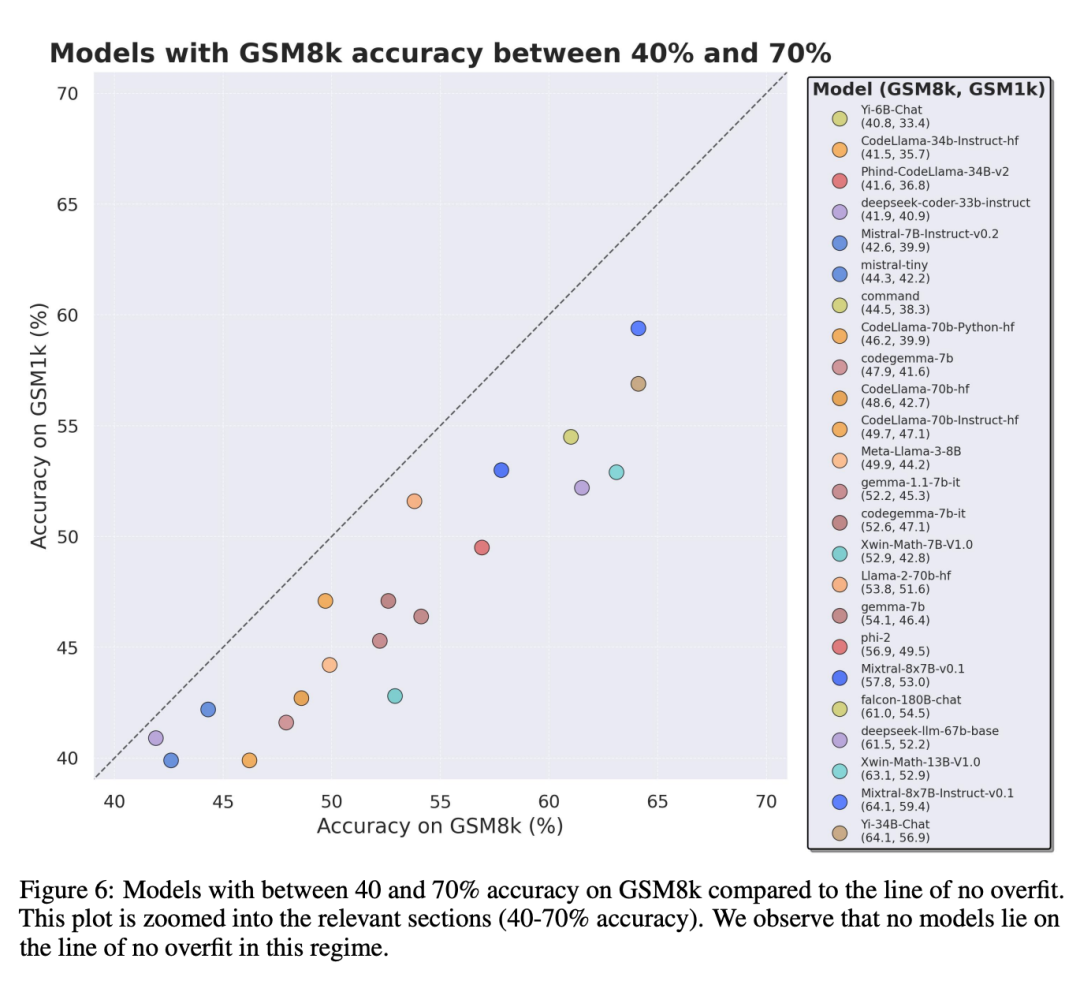
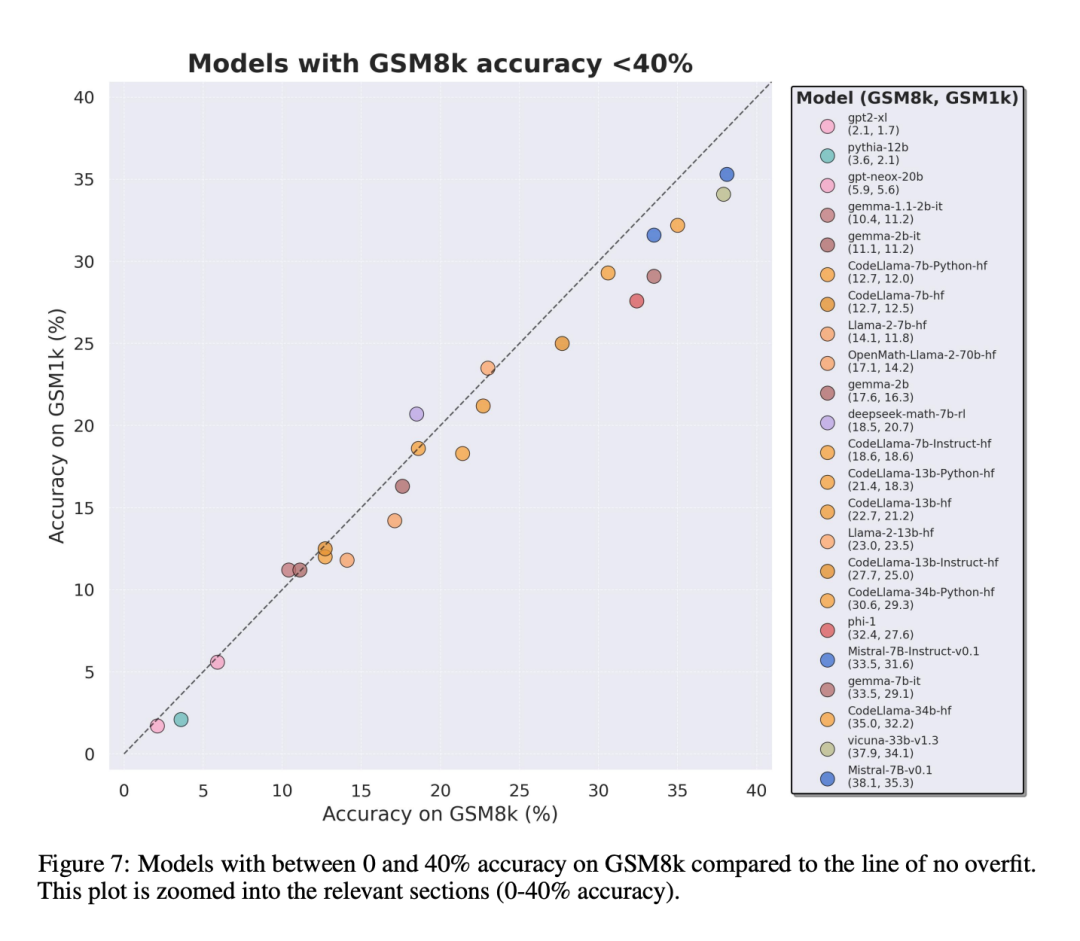
Quelles conclusions ont été tirées ?
Bien que les chercheurs aient fourni des résultats d'évaluation objectifs de plusieurs modèles, ils ont également déclaré que l'interprétation des résultats de l'évaluation, comme l'interprétation des rêves, est souvent une tâche très subjective. Dans la dernière partie de l'article, ils développent quatre implications de l'évaluation ci-dessus de manière plus subjective :
Conclusion 1 : Certaines familles modèles sont systématiquement surajustées
Bien qu'il soit souvent difficile de déterminer à partir d'un seul point de données ou conclusion de la version du modèle, mais l'examen de la famille de modèles et l'observation des modèles de surajustement permettent de faire une déclaration plus définitive. Certaines familles de modèles, notamment Phi et Mistral, affichent une tendance vers des performances système plus élevées sur le GSM8k que sur le GSM1k dans presque toutes les versions et tailles de modèles. Il existe d'autres familles de modèles telles que Yi, Xwin, Gemma et CodeLlama qui affichent également ce modèle dans une moindre mesure.
Conclusion 2 : D'autres modèles, en particulier les modèles de pointe, ne montrent aucun signe de surajustement
De nombreux modèles présentent de petits signes de surajustement dans tous les domaines de performance, notamment le modèle exclusif Mistral Large All de pointe ou presque. Les modèles Edge au sein de , semblent fonctionner de la même manière sur GSM8k et GSM1k. À cet égard, les chercheurs avancent deux hypothèses possibles : 1) les modèles Frontier ont des capacités de raisonnement suffisamment avancées, donc même si le problème GSM8k est déjà apparu dans leur ensemble de formation, ils peuvent être généralisés à de nouveaux problèmes ; Soyez plus prudent en cas de contamination des données.
Bien qu'il soit impossible d'examiner l'ensemble d'entraînement de chaque modèle et de déterminer ces hypothèses, un élément de preuve à l'appui de la première est que Mistral Large est le seul modèle de la série Mistral qui ne montre aucun signe de surapprentissage. L'hypothèse selon laquelle Mistral garantit uniquement que son plus grand modèle est exempt de contamination des données semble peu probable. Les chercheurs sont donc favorables à ce qu'un LLM suffisamment puissant acquière également des capacités d'inférence de base pendant la formation. Si un modèle apprend à raisonner suffisamment bien pour résoudre un problème d'une difficulté donnée, il sera capable de généraliser à de nouveaux problèmes même si GSM8k est présent dans son ensemble d'apprentissage.
Conclusion 3 : Le modèle de surajustement a toujours la capacité de raisonner
L'une des inquiétudes de nombreux chercheurs concernant le surajustement du modèle est que le modèle ne peut pas raisonner et mémorise uniquement les réponses dans les données d'entraînement, mais cet article Les résultats n’a pas soutenu cette hypothèse. Le fait qu’un modèle soit surajusté ne signifie pas que ses capacités d’inférence sont médiocres, cela signifie simplement qu’il n’est pas aussi bon que l’indique le benchmark. En fait, les chercheurs ont découvert que de nombreux modèles surajustés sont encore capables de raisonner et de résoudre de nouveaux problèmes. Par exemple, la précision de Phi-3 a chuté de près de 10 % entre GSM8k et GSM1k, mais il a quand même résolu correctement plus de 68 % des problèmes du GSM1k – des problèmes qui n’apparaissaient certainement pas dans sa distribution de formation. Cette performance est similaire à des modèles plus grands tels que dbrx-instruct, qui contiennent près de 35 fois plus de paramètres. De même, même en tenant compte du surajustement, le modèle Mistral reste l'un des modèles open source les plus puissants. Cela fournit davantage de preuves pour la conclusion de cet article selon laquelle un modèle suffisamment puissant peut apprendre l'inférence de base même si les données de référence s'infiltrent accidentellement dans la distribution d'entraînement, ce qui est susceptible de se produire avec la plupart des modèles surajustés.
Conclusion 4 : La contamination des données n'est peut-être pas une explication complète du surajustement
Une hypothèse a priori naturelle est que la principale cause du surajustement est la contamination des données, par exemple dans le pré-entraînement ou les instructions de création du modèle Pour la partie mise au point, l’ensemble de test a fui. Des recherches antérieures ont montré que les modèles attribuent une log-vraisemblance plus élevée aux données qu'ils ont vues pendant l'entraînement (Carlini et al. [2023]). Les chercheurs ont testé l'hypothèse selon laquelle la contamination des données est la cause du surajustement en mesurant la probabilité que le modèle génère des échantillons à partir de l'ensemble de test GSM8k et en comparant son degré de surajustement par rapport à GSM8k et GSM1k.
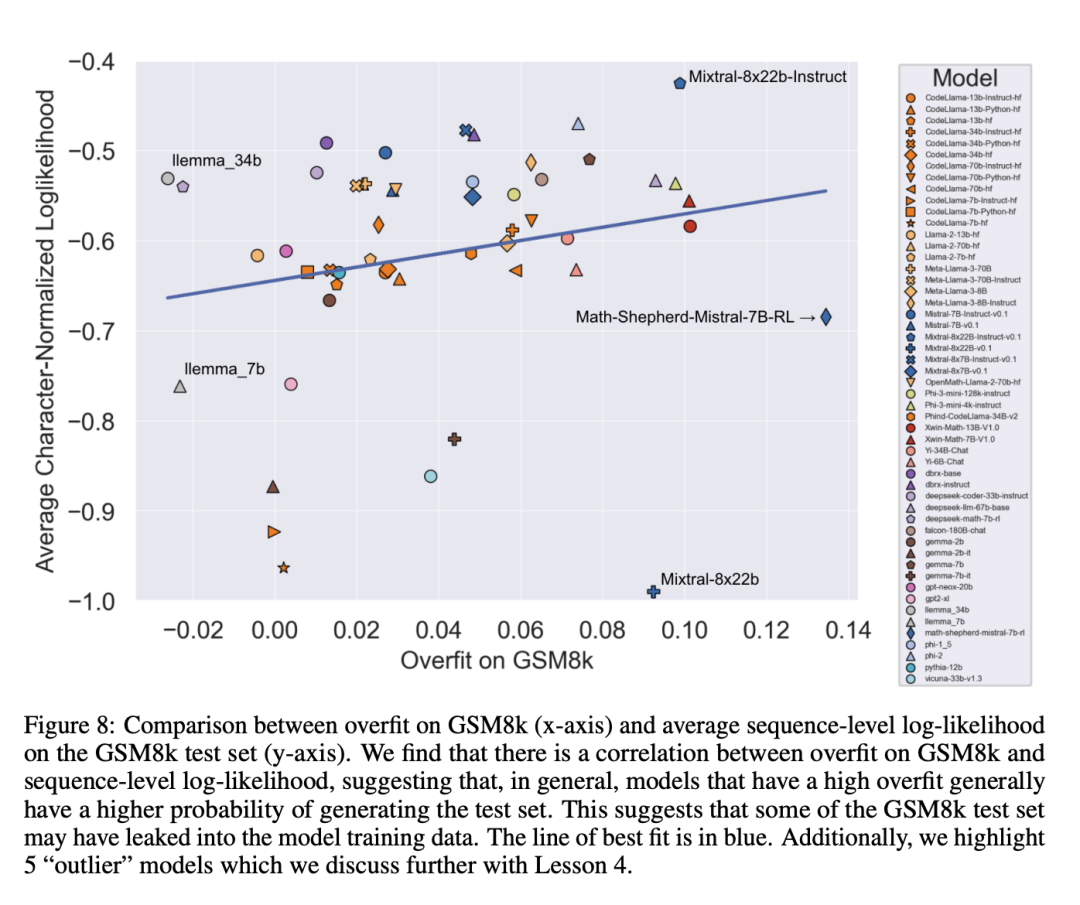
Les chercheurs affirment que la pollution des données n’est peut-être pas la seule raison. Ils ont observé cela avec plusieurs valeurs aberrantes. Un examen plus approfondi de ces valeurs aberrantes révèle que le modèle avec la log-vraisemblance par caractère la plus faible (Mixtral-8x22b) et le modèle avec la log-vraisemblance par caractère la plus élevée (Mixtral-8x22b-Instruct) ne sont pas seulement des variantes du même modèle. et a un degré similaire de surapprentissage. Plus intéressant encore, le modèle le plus surajusté (Math-Shepherd-Mistral-7B-RL (Yu et al. [2023])) a une log-vraisemblance par caractère relativement faible (Math Shepherd utilise des données synthétiques Entraîner des modèles de récompense sur des données au niveau du processus ).
Ainsi, les chercheurs ont émis l’hypothèse que le processus de modélisation des récompenses aurait pu divulguer des informations sur les chaînes d’inférence correctes pour GSM8k, même si les problèmes eux-mêmes ne sont jamais apparus dans l’ensemble de données. Enfin, ils ont constaté que le modèle Llema présentait une log-vraisemblance élevée et un surajustement minimal. Étant donné que ces modèles sont open source et que leurs données de formation sont connues, plusieurs instances du problème GSM8k apparaissent dans le corpus de formation, comme décrit dans l'article de Llema. Cependant, les auteurs ont constaté que ces quelques cas n’entraînaient pas de surapprentissage grave. L'existence de ces valeurs aberrantes suggère que le surajustement sur GSM8k n'est pas uniquement dû à la contamination des données, mais peut être causé par d'autres moyens indirects, tels que la collecte par le constructeur du modèle de données ayant des propriétés similaires à celles de la ligne de base en tant que données d'entraînement, ou basées sur les performances du modèle. le benchmark sélectionne le point de contrôle final du modèle, même si le modèle lui-même n'a peut-être vu l'ensemble de données GSM8k à aucun moment pendant la formation. L’inverse est également vrai : une petite quantité de contamination des données ne conduit pas nécessairement à un surapprentissage.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Ronglian Cloud a été sélectionné dans la carte mondiale de l'industrie de l'IA générative 2023
- L'innovation technologique accélère la mise en œuvre de l'industrie chinoise des interfaces cerveau-ordinateur
- L'alliance industrielle de l'interface cerveau-ordinateur publie dix technologies clés pour l'interface cerveau-ordinateur
- OpenAI s'associe à Scale AI pour améliorer les capacités de réglage fin des modèles GPT d'entreprise
- Construisons ensemble le Guangxi numérique et allons ensemble vers un avenir numérique ! La conférence écologique de l'industrie de l'intelligence artificielle du Guangxi Kunpeng Shengteng 2023 s'est tenue avec succès