
Maison >Périphériques technologiques >IA >Comment OctopusV3, avec moins d'un milliard de paramètres, peut-il se comparer à GPT-4V et GPT-4 ?
Comment OctopusV3, avec moins d'un milliard de paramètres, peut-il se comparer à GPT-4V et GPT-4 ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-05-02 16:01:01836parcourir
Les systèmes d'IA multimodaux se caractérisent par leur capacité à traiter et à apprendre divers types de données, notamment le langage naturel, la vision, l'audio, etc., pour guider leurs décisions comportementales. Récemment, la recherche sur l'intégration de données visuelles dans de grands modèles de langage (tels que GPT-4V) a réalisé des progrès importants, mais la manière de convertir efficacement les informations d'image en opérations exécutables pour les systèmes d'IA reste confrontée à des défis. Afin de réaliser la transformation des informations d'image, une méthode courante consiste à convertir les données d'image en descriptions textuelles correspondantes, puis le système d'IA fonctionne sur la base des descriptions. Cela peut être fait en effectuant un apprentissage supervisé sur des ensembles de données d'images existants, permettant au système d'IA d'apprendre automatiquement la relation de mappage image-texte. De plus, les méthodes d’apprentissage par renforcement peuvent également être utilisées pour apprendre à prendre des décisions basées sur des informations d’image en interagissant avec l’environnement. Une autre méthode consiste à combiner directement les informations d'image avec un modèle de langage pour construire
Dans un article récent, des chercheurs ont proposé un modèle multimodal conçu spécifiquement pour les applications d'IA, introduisant le concept de « jeton fonctionnel ».
Titre de l'article : Octopus v3 : Rapport technique pour un agent d'IA multimodal d'un milliard d'euros sur appareil
Lien de l'article : https://arxiv.org/pdf/2404.11459.pdf
Poids et inférence des modèles Code : https://www.nexa4ai.com/apply
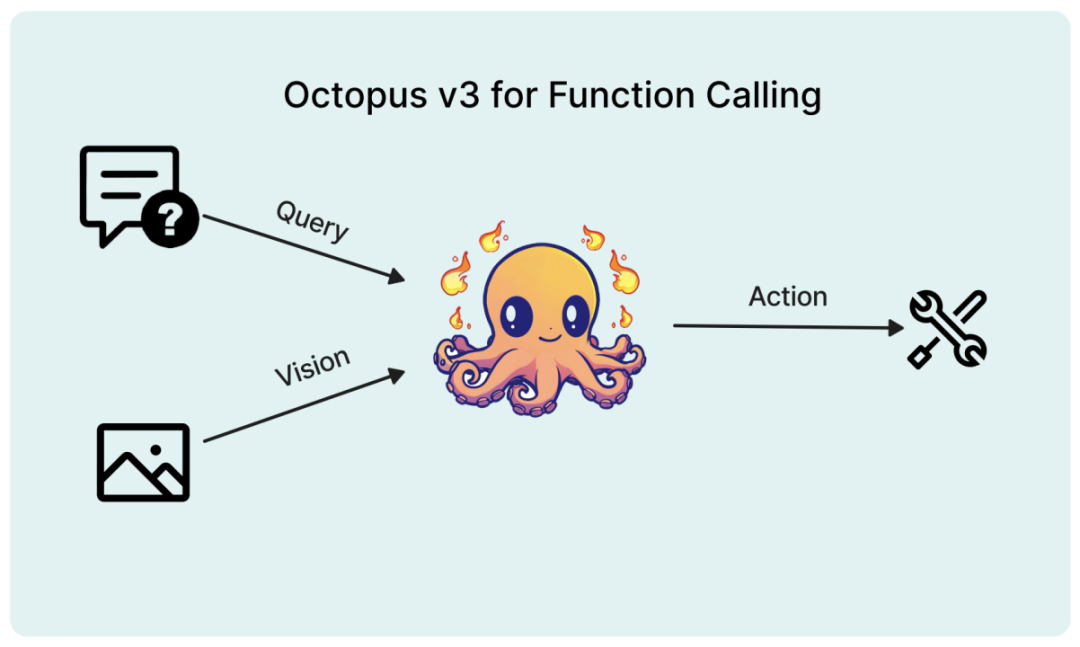
Ce modèle peut entièrement prendre en charge les appareils de pointe, et les chercheurs ont optimisé son nombre de paramètres à moins d'un milliard. Semblable au GPT-4, ce modèle peut gérer à la fois l’anglais et le chinois. Des expériences ont prouvé que le modèle peut fonctionner efficacement sur divers terminaux aux ressources limitées, notamment le Raspberry Pi.
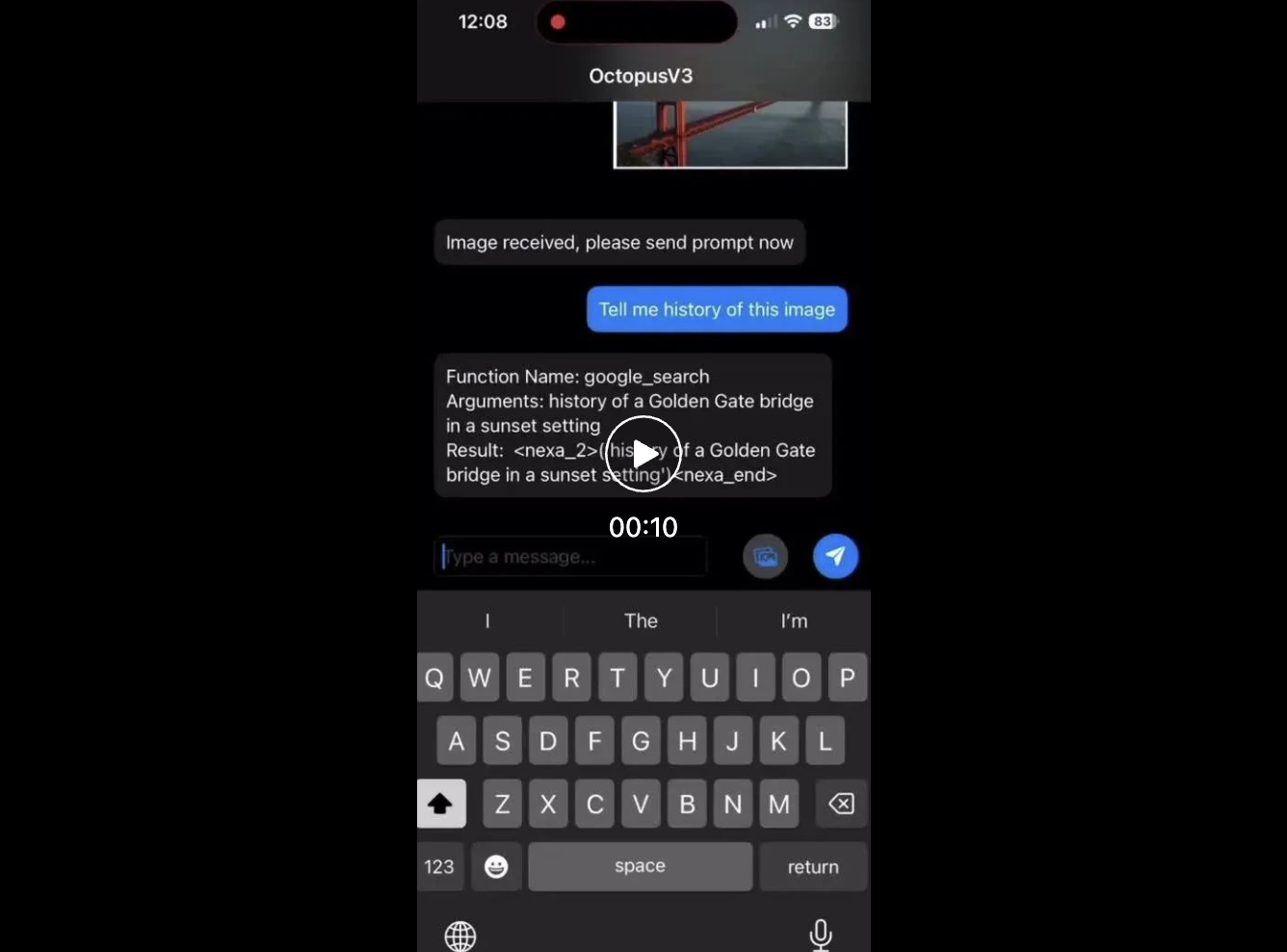
Contexte de recherche
Le développement rapide de la technologie de l'intelligence artificielle a complètement changé la façon dont se produisent les interactions homme-machine, donnant naissance à un certain nombre de systèmes d'IA intelligents capables d'effectuer des tâches complexes et de prendre des décisions basées sur diverses formes d'entrée telles que le langage naturel et la vision. Ces systèmes devraient tout automatiser, depuis des tâches simples telles que la reconnaissance d'images et la traduction linguistique jusqu'à des applications complexes telles que le diagnostic médical et la conduite autonome. Les modèles linguistiques multimodaux sont au cœur de ces systèmes intelligents, leur permettant de comprendre et de générer des réponses quasi humaines en traitant et en intégrant des données multimodales telles que du texte, des images et même de l'audio et de la vidéo. Par rapport aux modèles linguistiques traditionnels qui se concentrent principalement sur le traitement et la génération de texte, les modèles linguistiques multimodaux constituent un grand pas en avant. En incorporant des informations visuelles, ces modèles sont capables de mieux comprendre le contexte et la sémantique des données d'entrée, ce qui donne lieu à une sortie plus précise et pertinente. La capacité de traiter et d'intégrer des données multimodales est cruciale pour développer des systèmes d'IA multimodaux capables de comprendre simultanément des tâches telles que le langage et les informations visuelles, telles que la réponse visuelle aux questions, la navigation dans les images, l'analyse des sentiments multimodaux, etc.
L'un des défis du développement de modèles linguistiques multimodaux est de savoir comment encoder efficacement les informations visuelles dans un format que le modèle peut traiter. Cela se fait généralement à l'aide d'architectures de réseaux neuronaux, telles que les transformateurs visuels (ViT) et les réseaux neuronaux convolutifs (CNN). La capacité d'extraire des caractéristiques hiérarchiques des images est largement utilisée dans les tâches de vision par ordinateur. En utilisant ces architectures comme modèles, on peut apprendre à extraire des représentations plus complexes à partir des données d'entrée. De plus, l'architecture basée sur un transformateur est non seulement capable de capturer les dépendances à longue distance, mais excelle également dans la compréhension des relations entre les objets dans les images. Très populaire ces dernières années. Ces architectures permettent aux modèles d'extraire des caractéristiques significatives des images d'entrée et de les convertir en représentations vectorielles pouvant être combinées avec la saisie de texte.
Une autre façon d'encoder des informations visuelles est la tokenisation d'image, qui consiste à diviser l'image en unités discrètes ou jetons plus petites. Cette approche permet au modèle de traiter les images de la même manière que le texte, permettant une intégration plus transparente des deux modalités. Les informations sur les jetons d'image peuvent être introduites dans le modèle avec la saisie de texte, ce qui lui permet de se concentrer sur les deux modalités et de produire une sortie plus précise et contextuelle. Par exemple, le modèle DALL-E développé par OpenAI utilise une variante de VQ-VAE (Vector Quantized Variational Autoencoder) pour symboliser les images, permettant au modèle de générer de nouvelles images basées sur des descriptions textuelles. Le développement de petits modèles efficaces capables d’agir sur les requêtes et les images fournies par les utilisateurs aura de profondes implications pour le développement futur des systèmes d’IA. Ces modèles peuvent être déployés sur des appareils aux ressources limitées tels que les smartphones et les appareils IoT, élargissant ainsi leur portée d'application et leurs scénarios. Tirant parti de la puissance des modèles de langage multimodaux, ces petits systèmes peuvent comprendre et répondre aux requêtes des utilisateurs de manière plus naturelle et intuitive, tout en prenant en compte le contexte visuel fourni par l'utilisateur. Cela ouvre la possibilité d’interactions homme-machine plus engageantes et personnalisées, telles que des assistants virtuels qui fournissent des recommandations visuelles basées sur les préférences de l’utilisateur, ou des appareils domestiques intelligents qui ajustent les paramètres en fonction des expressions faciales de l’utilisateur.
En outre, le développement de systèmes d’IA multimodaux devrait démocratiser la technologie de l’intelligence artificielle, bénéficiant ainsi à un plus large éventail d’utilisateurs et d’industries. Des modèles plus petits et plus efficaces peuvent être formés sur du matériel doté d'une puissance de calcul plus faible, réduisant ainsi les ressources informatiques et la consommation d'énergie nécessaires au déploiement. Cela pourrait conduire à une application généralisée des systèmes d’IA dans divers domaines tels que les soins médicaux, l’éducation, le divertissement, le commerce électronique, etc., modifiant ainsi la façon dont les gens vivent et travaillent.
Travail connexe
Les modèles multimodaux ont attiré beaucoup d'attention en raison de leur capacité à traiter et à apprendre plusieurs types de données tels que le texte, les images, l'audio, etc. Ce type de modèle peut capturer les interactions complexes entre différentes modalités et utiliser leurs informations complémentaires pour améliorer la performance de diverses tâches. Les modèles Vision-Language Pre-trained (VLP) tels que ViLBERT, LXMERT, VisualBERT, etc. apprennent l'alignement des fonctionnalités visuelles et textuelles grâce à une attention intermodale pour générer de riches représentations multimodales. Les architectures de transformateurs multimodaux telles que MMT, ViLT, etc. ont amélioré les transformateurs pour gérer efficacement plusieurs modalités. Les chercheurs ont également essayé d'incorporer d'autres modalités telles que les expressions audio et faciales dans les modèles, tels que les modèles d'analyse multimodale des sentiments (MSA), les modèles de reconnaissance multimodale des émotions (MER), etc. En utilisant les informations complémentaires de différentes modalités, les modèles multimodaux atteignent de meilleures performances et capacités de généralisation que les méthodes monomodales.
Les modèles de langage de terminal sont définis comme des modèles comportant moins de 7 milliards de paramètres, car les chercheurs ont découvert que même avec la quantification, il est très difficile d'exécuter un modèle de 13 milliards de paramètres sur des appareils de pointe. Les avancées récentes dans ce domaine incluent les Gemma 2B et 7B de Google, le Stable Code 3B de Stable Diffusion et le Llama 7B de Meta. Il est intéressant de noter que les recherches de Meta montrent que, contrairement aux grands modèles de langage, les petits modèles de langage fonctionnent mieux avec des architectures profondes et étroites. D'autres techniques bénéfiques pour le modèle de terminal incluent le partage intégré, l'attention aux requêtes groupées et le partage instantané du poids des blocs proposé dans MobileLLM. Ces résultats mettent en évidence la nécessité de prendre en compte des méthodes d'optimisation et des stratégies de conception différentes lors du développement de petits modèles de langage pour les applications finales plutôt que pour les grands modèles.
Méthode Octopus
La principale technologie utilisée dans le développement du modèle Octopus v3. Deux aspects clés du développement de modèles multimodaux consistent à intégrer les informations d'image à la saisie de texte et à optimiser la capacité du modèle à prédire les actions.
Encodage des informations visuelles
Il existe de nombreuses méthodes de codage des informations visuelles dans le traitement d'images, et l'intégration de couches cachées est couramment utilisée. Par exemple, l'intégration de couches cachées du modèle VGG-16 est utilisée pour les tâches de transfert de style. Le modèle CLIP d'OpenAI démontre la capacité d'aligner l'intégration de texte et d'images, en tirant parti de son encodeur d'image pour intégrer des images. Des méthodes telles que ViT utilisent des technologies plus avancées telles que la tokenisation d'images. Les chercheurs ont évalué diverses techniques de codage d’images et ont découvert que la méthode du modèle CLIP était la plus efficace. Par conséquent, cet article utilise un modèle basé sur CLIP pour le codage d’images.
Jeton fonctionnel
Semblable à la tokenisation appliquée au langage naturel et aux images, des fonctions spécifiques peuvent également être encapsulées sous forme de jetons fonctionnels. Les chercheurs ont introduit une stratégie de formation pour ces jetons, s'appuyant sur la technologie des modèles de langage naturel pour traiter des mots invisibles. Cette méthode est similaire à word2vec et enrichit la sémantique du token grâce à son contexte. Par exemple, les modèles de langage de haut niveau peuvent initialement avoir des difficultés avec des termes chimiques complexes tels que PEGylation et Endosomal Escape. Mais grâce à la modélisation causale du langage, notamment en s’entraînant sur un ensemble de données contenant ces termes, le modèle peut apprendre ces termes. De même, les jetons fonctionnels peuvent également être appris via des stratégies parallèles, le modèle Octopus v2 fournissant une plate-forme puissante pour de tels processus d'apprentissage. La recherche montre que l’espace de définition des jetons fonctionnels est infini, permettant à n’importe quelle fonction spécifique d’être représentée sous forme de jeton.
Formation en plusieurs étapes
Pour développer un système d'IA multimodal haute performance, les chercheurs ont adopté une architecture de modèle qui intègre des modèles de langage causal et des encodeurs d'images. Le processus de formation de ce modèle est divisé en plusieurs étapes. Premièrement, le modèle de langage causal et l’encodeur d’image sont formés séparément pour établir un modèle de base. Par la suite, les deux composants sont fusionnés, alignés et entraînés pour synchroniser les capacités de traitement d'image et de texte. Sur cette base, la méthode d’Octopus v2 est utilisée pour favoriser l’apprentissage des tokens fonctionnels. Dans la phase finale de formation, ces jetons fonctionnels qui interagissent avec l'environnement fournissent des commentaires pour une optimisation ultérieure du modèle. Par conséquent, dans la phase finale, les chercheurs ont adopté l’apprentissage par renforcement et ont sélectionné un autre grand modèle de langage comme modèle de récompense. Cette méthode de formation itérative améliore la capacité du modèle à traiter et à intégrer des informations multimodales.
Évaluation du modèle
Cette section présente les résultats expérimentaux du modèle et les compare aux effets de l'intégration des modèles GPT-4V et GPT-4. Dans l’expérience comparative, les chercheurs ont d’abord utilisé GPT-4V (gpt-4-turbo) pour traiter les informations d’image. Les données extraites sont ensuite introduites dans le framework GPT-4 (gpt-4-turbo-preview), qui contextualise toutes les descriptions de fonctions et applique un apprentissage en quelques étapes pour améliorer les performances. Dans la démonstration, les chercheurs ont converti 10 API de smartphone couramment utilisées en jetons fonctionnels et ont évalué leurs performances, comme détaillé dans les sections suivantes.
Il convient de noter que bien que cet article ne montre que 10 jetons fonctionnels, le modèle peut entraîner davantage de jetons pour créer un système d'IA plus général. Les chercheurs ont découvert que pour certaines API, les modèles comportant moins d’un milliard de paramètres fonctionnaient comme une IA multimodale comparable à la combinaison de GPT-4V et GPT-4.
De plus, l'évolutivité de ce modèle permet l'inclusion d'une large gamme de jetons fonctionnels, permettant la création de systèmes d'IA hautement spécialisés adaptés à des domaines ou à des scénarios spécifiques. Cette adaptabilité rend notre approche particulièrement précieuse dans des secteurs tels que la santé, la finance et le service client, où les solutions basées sur l'IA peuvent améliorer considérablement l'efficacité et l'expérience utilisateur.
Parmi tous les noms de fonctions ci-dessous, Octopus ne génère que des jetons fonctionnels tels que
Envoyer un e-mail

Envoyer un SMS

Recherche Google

Amazon Shopping
Recyclage intelligent
Perdu et Trouvé 
Design d'intérieur

Instacart Shopping

Livraison DoorDash

Soins des animaux

Impact social
Basé sur Octopus v2, le modèle mis à jour intègre des informations textuelles et visuelles , une avancée significative par rapport à son prédécesseur, l’approche textuelle uniquement. Cette avancée significative permet le traitement simultané de données visuelles et en langage naturel, ouvrant la voie à des applications plus larges. Le jeton fonctionnel introduit dans Octopus v2 peut être adapté à plusieurs domaines, tels que les industries médicale et automobile. Avec l'ajout de données visuelles, le potentiel des jetons fonctionnels s'étend à des domaines tels que la conduite autonome et la robotique. De plus, le modèle multimodal présenté dans cet article permet de transformer réellement des appareils tels que Raspberry Pi en matériel intelligent tel que Rabbit R1 et Humane AI Pin, en utilisant un modèle de point final plutôt qu'une solution basée sur le cloud.
Le jeton fonctionnel est actuellement autorisé. Le chercheur encourage les développeurs à participer dans le cadre de cet article et à innover librement sous réserve de respecter l'accord de licence. Dans les recherches futures, les chercheurs visent à développer un cadre de formation pouvant accueillir des modalités de données supplémentaires telles que l’audio et la vidéo. De plus, les chercheurs ont découvert que les entrées visuelles peuvent entraîner une latence considérable et optimisent actuellement la vitesse d’inférence.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!