
Maison >Périphériques technologiques >IA >Le Sora domestique le plus puissant à l'heure actuelle ! L'équipe Tsinghua réalise une vidéo de 16 secondes, comprend le langage multi-objectifs et peut simuler les lois physiques
Le Sora domestique le plus puissant à l'heure actuelle ! L'équipe Tsinghua réalise une vidéo de 16 secondes, comprend le langage multi-objectifs et peut simuler les lois physiques

- 王林avant
- 2024-04-28 13:04:011156parcourir
Vous avez dit que la boîte devait être remplie de diamants, donc la boîte était remplie de diamants, ce qui était encore plus éblouissant que la vraie photo. Quel équipage n’apprécierait pas de telles compétences ?
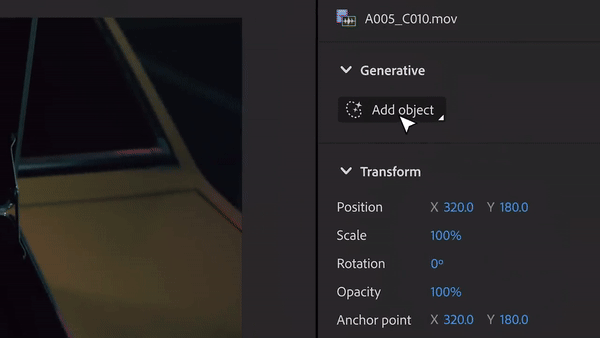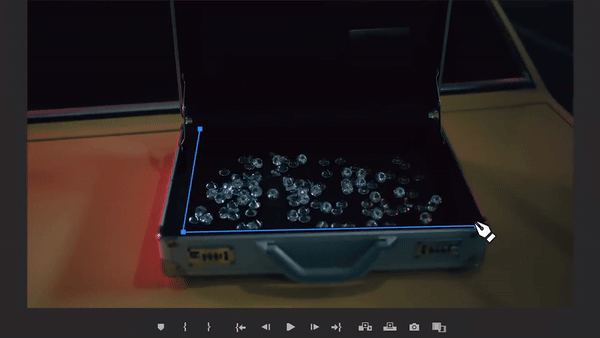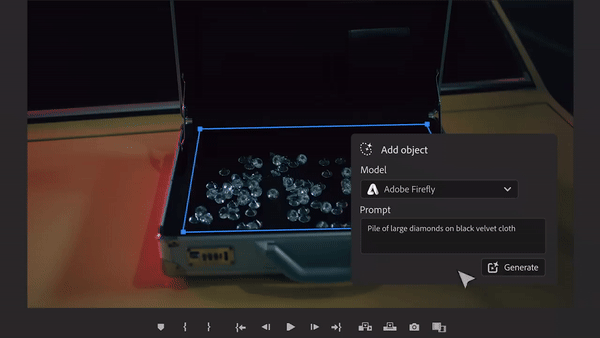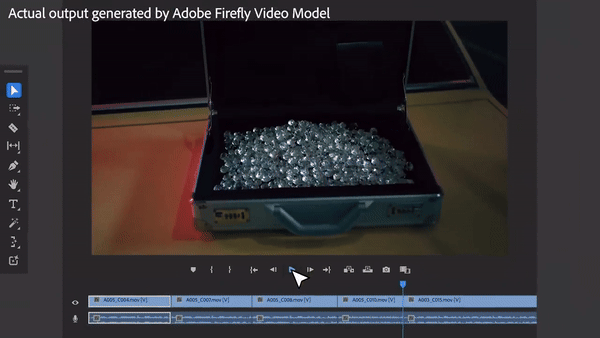
C'est la "magie" présentée par le logiciel de montage vidéo d'Adobe Premiere Pro il y a quelques temps. Ce logiciel introduit des outils vidéo d'IA tels que Sora, Runway et Pika pour permettre d'ajouter des objets, de supprimer des objets et de générer des clips vidéo dans des vidéos. Ceci est considéré comme une autre innovation technologique dans le domaine vidéo.
Depuis février, lorsque Sora a de nouveau emporté le monde avec la magie d'Adobe, l'outre-mer bat son plein. En revanche, la Chine est toujours dans un état « d'attente » dans le domaine de la vidéo, notamment en ce qui concerne la génération de vidéos longues. Au cours des deux derniers mois, nous avons entendu des allégations selon lesquelles Sora serait poursuivi, mais nous n'avons pas encore constaté de progrès significatifs au niveau national. Mais la courte vidéo que vient de publier aujourd'hui Shengshu Technology nous réserve bien des surprises. 
Ceci est la vidéo officielle du dernier Modèle vidéo "Vidu" publié par Shengshu Technology et l'Université Tsinghua. On constate que la vidéo qu'il génère n'est plus un "GIF" qui dure quelques secondes, mais atteint plus de dix secondes (la plus longue peut atteindre environ 16 secondes). Bien sûr, ce qui est encore plus surprenant, c'est que l'effet d'image de "Vidu" est très proche de celui de Sora. Il fonctionne très bien en langage multi-objectifs, en cohérence temporelle et spatiale, et suit les lois physiques, et il peut aussi créer fictivement un monde qui n'existe pas. Des images super-réalistes , difficiles à réaliser avec les modèles de génération vidéo actuels. En seulement deux mois, Shengshu Technology a pu obtenir de tels résultats, ce qui est vraiment surprenant.
Le premier modèle vidéo en Chine qui se compare pleinement à Sora
Depuis la sortie de Sora, la bataille pour le « Sora domestique » a commencé. Mais lorsque l'industrie se concentre sur la fonctionnalité "longue", ils ignorent tous que derrière Sora se cache en réalité l'amélioration d'effets complets, tels que la cohérence, le réalisme, la beauté, etc. dans de longues séquences.
Du point de vue global des effets, "Vidu" est le premier et le seul modèle vidéo à se comparer pleinement à Sora au niveau des effets, non seulement au niveau national, mais aussi mondial, et c'est également le premier modèle vidéo à atteindre une percée après Sora. D'après les effets spécifiques, nous pouvons clairement voir plusieurs avantages évidents :
Injecter le « langage de l'objectif » dans la vidéo
Il existe un concept très important dans la production vidéo : le langage de l'objectif. C'est le principal moyen d'exprimer le scénario, de révéler la psychologie du personnage, de créer l'atmosphère et de guider les émotions du public à travers les images. Différents choix de plans, angles, mouvements et combinaisons affecteront grandement le récit et l'expérience du public.
Les vidéos existantes générées par l'IA peuvent clairement ressentir la monotonie du langage de l'objectif, et le mouvement de l'objectif est limité à des prises de vue simples telles qu'une légère poussée, traction et déplacement. La principale raison en est que la plupart des générations de contenu vidéo existantes génèrent d'abord une seule image, puis prédisent des images consécutives avant et après. Cependant, avec la voie technique traditionnelle, il est difficile d'obtenir de petites prévisions dynamiques cohérentes à long terme.在 Bande-annonce du film de science-fiction de Runway "Trailer: Genesis" générée en juillet de l'année dernière.

Astuce : Dans un chalet pittoresque en bord de mer, le soleil baigne la pièce, la caméra passe lentement vers un balcon surplombant la mer tranquille, et enfin la caméra se fige sur la mer flottante, les voiliers et les nuages réfléchissants. (Clip vidéo complet publié par le site officiel du produit PixWeaver de Shengshu)
De plus, comme le montrent plusieurs clips du court métrage, "Vidu" peut générer directement des effets tels que des transitions, un suivi de la mise au point et des plans longs, y compris la possibilité de générer des séquences de cinéma et de télévision, d'injecter un langage d'objectif dans la vidéo et améliorer l'image globale.



Maintenir la cohérence du temps et de l'espace
La cohérence et la fluidité de l'image vidéo sont très importantes. Derrière cela se cache en fait la cohérence spatio-temporelle des personnages et des scènes, par exemple. en tant que personnages dans l'espace Le mouvement est toujours cohérent et la scène ne peut pas changer soudainement sans aucune transition. C'est difficile à réaliser pour l'IA, surtout si cela dure longtemps. Les vidéos générées par l'IA auront des problèmes tels que des ruptures narratives, des incohérences visuelles et des erreurs logiques. Ces problèmes affecteront sérieusement le réalisme et le plaisir de la vidéo.
"Vidu" surmonte ces problèmes dans une certaine mesure. De la vidéo de "Chat avec une boucle d'oreille" générée par celui-ci, nous pouvons voir que lorsque la caméra bouge, le chat en tant que sujet de l'image conserve toujours la même expression et les mêmes vêtements dans l'espace 3D, et dans la vidéo dans son ensemble. est très cohérent et fluide, conservant une bonne cohérence temporelle et spatiale. 
Conseils : Il s'agit d'un portrait d'un chat orange aux yeux bleus, tournant lentement, inspiré de la "Fille à la perle" de Vermeer, la photo porte une boucle d'oreille en perles et des cheveux bruns comme Holland Cap pareil, fond noir, lumières de studio. (Clip vidéo complet publié par le site officiel du produit PixWeaver sous Shengshu)
Simulation du monde physique réel
L'une des fonctionnalités étonnantes de Sora est qu'il peut simuler le mouvement du monde physique réel, tel que le mouvement et l'interaction des objets. L'un des cas classiques publiés par Sora - l'image d'un "vieux SUV roulant à flanc de colline", simule très bien la poussière soulevée par les pneus, la lumière et l'ombre dans les bois, et l'ombre change pendant la conduite de la voiture. . Sous le même mot d'invite, les effets générés par "Vidu" et Sora sont très similaires, et des détails tels que la poussière, la lumière et l'ombre sont très proches de l'expérience humaine dans le monde physique réel.  Astuce : La caméra suit un SUV vintage blanc avec une galerie de toit noire alors qu'il roule à toute vitesse sur un chemin de terre escarpé entouré de pins, les pneus soulevant la poussière et la lumière du soleil éclairant le SUV, projetant une lueur chaleureuse sur le SUV. scène entière. Le chemin de terre serpentait doucement au loin, sans aucune autre voiture ou véhicule en vue. Il y a des séquoias des deux côtés de la route, avec des parcelles de verdure dispersées ici et là. Vue de derrière, la voiture suit les courbes avec aisance et donne l'impression de rouler sur un terrain accidenté. Le chemin de terre est entouré de collines et de montagnes escarpées, avec un ciel bleu clair et des volutes de nuages au-dessus. (Fragments vidéo complets publiés par le site officiel du produit Pixweaver)
Astuce : La caméra suit un SUV vintage blanc avec une galerie de toit noire alors qu'il roule à toute vitesse sur un chemin de terre escarpé entouré de pins, les pneus soulevant la poussière et la lumière du soleil éclairant le SUV, projetant une lueur chaleureuse sur le SUV. scène entière. Le chemin de terre serpentait doucement au loin, sans aucune autre voiture ou véhicule en vue. Il y a des séquoias des deux côtés de la route, avec des parcelles de verdure dispersées ici et là. Vue de derrière, la voiture suit les courbes avec aisance et donne l'impression de rouler sur un terrain accidenté. Le chemin de terre est entouré de collines et de montagnes escarpées, avec un ciel bleu clair et des volutes de nuages au-dessus. (Fragments vidéo complets publiés par le site officiel du produit Pixweaver) 
L'effet de production de Sora.
Bien sûr, "Vidu" n'a pas réussi à générer les détails partiels de "avec galerie de toit noire". Mais ses défauts ne cachent pas ses mérites et son effet global est très proche du monde réel.
🎜🎜Riche imagination🎜🎜🎜Par rapport à la prise de vue réelle, l'utilisation de l'IA pour générer des vidéos présente un gros avantage : elle peut générer des images qui n'existent pas dans le monde réel. Dans le passé, ces images nécessitaient souvent beaucoup de main d’œuvre et de ressources matérielles pour construire ou créer des effets spéciaux, mais l’IA peut les générer automatiquement en peu de temps. 🎜Par exemple, dans la scène ci-dessous, « Voilier » et « Vagues » apparaissent rarement en studio, et l'interaction entre les vagues et le voilier est très naturelle. 
Invite : Un navire dans le studio se dirige vers la caméra. (Clip vidéo complet publié par le site officiel du produit PixWeaver de Shengshu)

Le clip "fish tank girl" dans le court métrage est également fantastique mais a un certain sens du raisonnable. Cette capacité à fabriquer des images qui n'existent pas dans le monde réel est très utile pour créer du contenu surréaliste. Elle peut non seulement inspirer les créateurs et offrir de nouvelles expériences visuelles, mais également élargir les limites de l'expression artistique, apportant des formats de contenu plus riches et plus diversifiés.
Comprendre les éléments chinois
En plus des quatre caractéristiques ci-dessus, nous avons également vu différentes surprises des courts métrages sortis par "Vidu". "Vidu" peut générer des images avec des éléments chinois uniques, tels que des pandas et des dragons, scènes de palais, etc. 
Conseils : Au bord du lac tranquille, un panda joue avec impatience de la guitare, donnant vie à tout l'environnement. Refletée sur des eaux calmes sous un ciel clair, la scène est capturée dans des prises de vue panoramiques éclatantes qui mélangent le réalisme avec l'esprit vif du panda géant, créant un mélange harmonieux d'énergie et de calme. (Clip vidéo complet publié par le site officiel du produit PixWeaver de Shenshu)
Comment avez-vous réalisé cette percée rapide en deux mois ?
Shengshu Technology, l'équipe R&D derrière « Vidu », est une équipe entrepreneuriale dans le domaine des grands modèles multimodaux en Chine. Les principaux membres sont issus de l'Institut de recherche sur l'intelligence artificielle de l'Université Tsinghua. champs de génération modale tels que les images, la 3D et les vidéos.
En janvier de cette année, Shengshu Technology a lancé une fonction de génération de vidéos courtes sur sa plateforme de conception créative visuelle PixWeaver, prenant en charge un contenu vidéo court hautement esthétique de 4 secondes. Après le lancement de Sora en février, il est rapporté que Shengshu Technology a créé une équipe de recherche interne formelle pour accélérer les progrès de la recherche et du développement de la direction vidéo originale. En mars, elle a réalisé une génération vidéo de 8 secondes en interne, puis a percé. la 16e génération en avril, réalisant des percées dans tous les aspects de la qualité et de la durée de la génération.
Comme nous le savons tous, Sora n'a pas annoncé trop de détails techniques. La base de sa capacité à réaliser des percées en si peu de temps est la profonde accumulation technique de l'équipe et de nombreuses réalisations originales de 0 à 1, en particulier dans le domaine du football. niveau d'architecture technique de base.
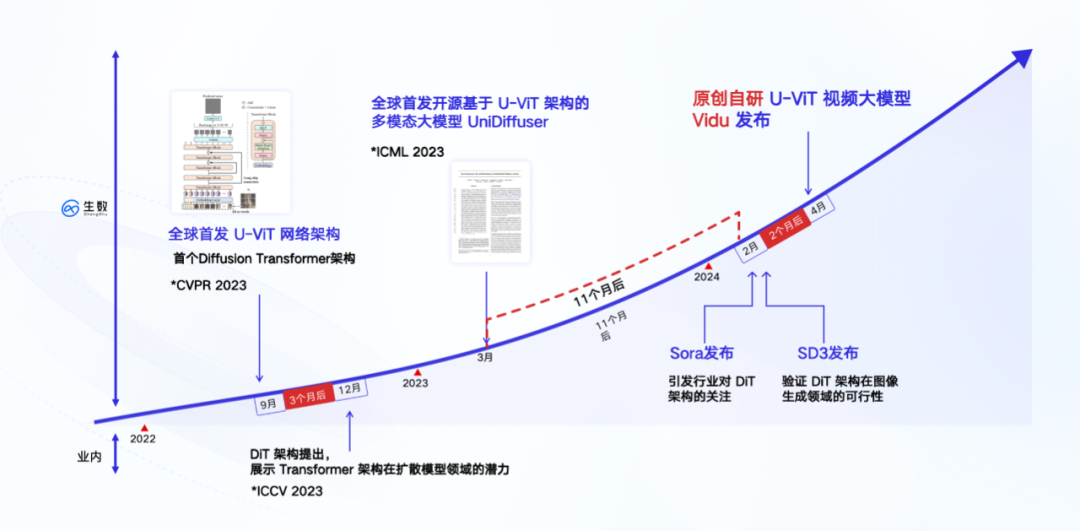
La couche inférieure de "Vidu" est basée sur l'architecture U-ViT entièrement auto-développée, qui a été proposée par l'équipe en septembre 2022. Elle est antérieure à l'architecture DiT adoptée par Sora et est la première architecture au monde qui intègre Diffusion et Transformer.

Deux mois avant la publication de l'article DiT, l'équipe de Zhu Jun de l'Université Tsinghua a soumis un article intitulé "Tous valent des mots : une épine dorsale ViT pour les modèles de diffusion". Cet article propose une architecture de réseau U-ViT qui utilise Transformer pour remplacer l'U-Net basé sur CNN. C'est la base technique la plus importante de "Vidu".
Sur le plan technique, "Vidu" adopte l'architecture de fusion Diffusion et Transformer qui est exactement la même que Sora. Différent de l'utilisation de la méthode de traitement en plusieurs étapes consistant à interpoler des images pour générer de longues vidéos, "Vidu" adopte le même chemin que Sora, c'est-à-dire générer directement des vidéos de haute qualité en une seule étape. D'un point de vue de bas niveau, il s'agit d'une méthode de mise en œuvre « en une étape » entièrement générée de bout en bout sur la base d'un modèle unique. Elle n'implique pas l'insertion de trames intermédiaires ni d'autres traitements en plusieurs étapes. la vidéo est directe et continue. De plus, sur la base de l'architecture U-ViT, en mars 2023, l'équipe a formé un modèle multimodal avec 1 milliard de paramètres - UniDiffuser sur l'ensemble de données graphiques et textuelles open source à grande échelle LAION-5B, et l'a réalisé open source (voir "L'équipe de Tsinghua Zhu Jun a open source le premier modèle de diffusion multimodale à grande échelle basé sur Transformer, avec interopérabilité et réécriture de textes et de graphiques, le tout réalisé》).
UniDiffuser est principalement bon pour les tâches graphiques et textuelles et peut prendre en charge la génération et la conversion arbitraires entre les modes graphique et texte. La mise en œuvre d'UniDiffuser a une valeur importante : elle a vérifié pour la première fois l'évolutivité (loi de mise à l'échelle) de l'architecture de fusion dans des tâches de formation à grande échelle, ce qui équivaut à parcourir tous les processus de l'architecture U-ViT à grande échelle. tâches de formation à grande échelle. Il convient de mentionner qu'UniDiffuser a un an d'avance sur l'introduction de Stable Diffusion 3, un modèle graphique avec la même architecture DiT.
Ces expériences d'ingénierie accumulées dans des tâches graphiques et textuelles ont jeté les bases du développement de modèles vidéo. La vidéo étant essentiellement un flux d’images, elle équivaut à une expansion de l’image sur la chronologie. Par conséquent, les résultats obtenus dans les tâches d’image et de texte peuvent souvent être réutilisés dans les tâches vidéo. C'est exactement ce que fait Sora : il utilise la technologie de réannotation de DALL・E 3 pour générer des descriptions détaillées des données d'entraînement visuel, permettant au modèle de suivre plus précisément les instructions textuelles de l'utilisateur pour générer des vidéos. Cet effet se produira inévitablement sur "Vidu".
Selon l'actualité précédente, "Vidu" réutilise également une grande partie de l'expérience de Bioshu Technology dans les tâches graphiques et textuelles, notamment l'accélération de la formation, la formation parallèle, la formation à faible mémoire, etc., parcourant ainsi rapidement le processus de formation. Il est rapporté qu'ils ont utilisé la technologie de compression des données vidéo pour réduire la dimension de séquence des données d'entrée et ont en même temps adopté un cadre de formation distribué auto-développé. Tout en garantissant la précision des calculs, l'efficacité de la communication a été doublée et la surcharge de mémoire a été réduite. de 80 % et la vitesse d'entraînement a été augmentée de 40 fois au total.
De l'unification des tâches graphiques à l'intégration des capacités vidéo, « Vidu » peut être considéré comme un modèle visuel général pouvant prendre en charge la génération de contenu vidéo plus diversifié et plus long. Les responsables ont également révélé que « Vidu » accélère actuellement les améliorations itératives. Face à l’avenir, l’architecture de modèle flexible de « Vidu » sera également compatible avec un plus large éventail de capacités multimodales.
Une équipe compétente de l'Université Tsinghua
Enfin, parlons de l'équipe derrière « Vidu » - Shengshu Technology. Il s'agit d'une équipe compétente avec une expérience Tsinghua.
L'équipe principale de Shengshu Technology vient de l'Institut de recherche en intelligence artificielle de l'Université Tsinghua. Le scientifique en chef est Zhu Jun, directeur adjoint de l'Institut d'intelligence artificielle de Tsinghua ; le PDG Tang Jiayu a étudié au Département d'informatique de l'Université de Tsinghua et est membre du groupe THUNLP ; doctorant au Département d'informatique de l'Université Tsinghua et professeur Zhu Jun. Membre de l'équipe de recherche, il s'intéresse depuis longtemps à la recherche dans le domaine des modèles de diffusion. Il a dirigé la réalisation d'U-ViT et d'UniDiffuser. L'équipe est engagée dans la recherche sur l'intelligence artificielle générative et l'apprentissage automatique bayésien depuis plus de 20 ans et a mené des recherches approfondies dès les premiers jours de la percée des modèles génératifs profonds. En termes de modèles de diffusion, l'équipe a pris l'initiative de lancer des recherches dans cette direction en Chine, et les résultats impliquent des orientations technologiques complètes telles que les réseaux fédérateurs, les algorithmes d'inférence à haut débit et la formation à grande échelle.
 L'équipe a publié près de 30 articles liés au domaine multimodal lors des principales conférences sur l'intelligence artificielle telles que ICML, NeurIPS et ICLR. Parmi eux, les algorithmes d'inférence sans formation proposés Analytic-DPM, DPM-Solver et. d'autres résultats révolutionnaires ont remporté le prix ICLR Outstanding Paper Award et ont été adoptés par des institutions étrangères de pointe telles que OpenAI, Apple et Stability.ai, et utilisés dans des projets vedettes tels que DALL・E 2 et Stable Diffusion.
L'équipe a publié près de 30 articles liés au domaine multimodal lors des principales conférences sur l'intelligence artificielle telles que ICML, NeurIPS et ICLR. Parmi eux, les algorithmes d'inférence sans formation proposés Analytic-DPM, DPM-Solver et. d'autres résultats révolutionnaires ont remporté le prix ICLR Outstanding Paper Award et ont été adoptés par des institutions étrangères de pointe telles que OpenAI, Apple et Stability.ai, et utilisés dans des projets vedettes tels que DALL・E 2 et Stable Diffusion.
Depuis sa création en 2023, l'équipe a été reconnue par de nombreuses institutions industrielles bien connues telles que Ant Group, Qiming Venture Partners, BV Baidu Ventures, Byte Jinqiu Fund, etc., et a réalisé des centaines de millions de yuans de financement. Il est rapporté que
Shengshu Technology est actuellement l'équipe entrepreneuriale la plus valorisée dans le secteur des grands modèles multimodaux en Chine. Le lancement de « Vidu » est une autre innovation et leadership de Shenshu Technology dans le domaine des grands modèles natifs multimodaux. Lecture connexe :
《
Entretien exclusif avec Tang Jiayu de Shengshu Technology : Après avoir reçu des centaines de millions de financement, Transformer peut fabriquer de grands modèles multimodauxLes entreprises nationales sont-elles censées fabriquer Sora ? Cette grande équipe modèle de l'Université Tsinghua donne de l'espoirCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Que faire si l'écran de Premiere se bloque
- Comment exporter des vidéos dans Premiere
- Comment faire en sorte que la vidéo remplisse tout l'écran dans Premiere
- Comment réduire la quantité de données transmises par les sites Web Python et améliorer la vitesse d'accès grâce à la technologie de compression ?
- Comment les robots collaboratifs peuvent-ils permettre la fabrication intelligente et la modernisation de l'industrie chimique quotidienne ? Écoutez ce que disent les experts