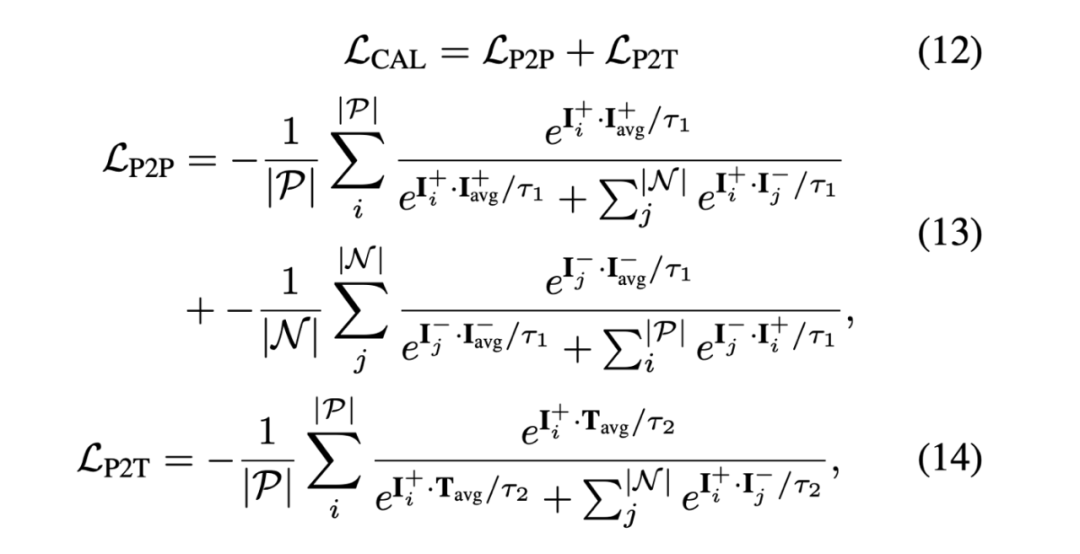La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com.
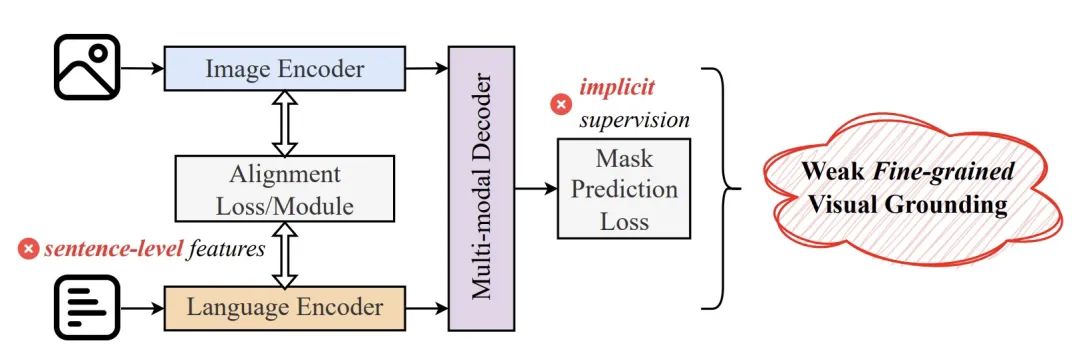
La segmentation d'images de référence (RIS) est une tâche multimodale très difficile qui nécessite des algorithmes pour comprendre simultanément le langage humain et les informations visuelles de l'image, et pour classer les phrases dans l'image. niveau des pixels. Les percées de la technologie RIS devraient apporter des changements révolutionnaires dans de nombreux domaines tels que l'interaction homme-machine, l'édition d'images et la conduite autonome. Cela peut considérablement améliorer l’efficacité et l’expérience de la collaboration homme-machine. Bien que les algorithmes RIS de pointe actuels aient fait des progrès significatifs, ils sont toujours confrontés au problème de l’écart modal, c’est-à-dire que la distribution des caractéristiques de l’image et du texte n’est pas complètement alignée. Ce problème est particulièrement aigu lorsqu’il s’agit d’expressions linguistiques référentielles complexes et de contextes rares.
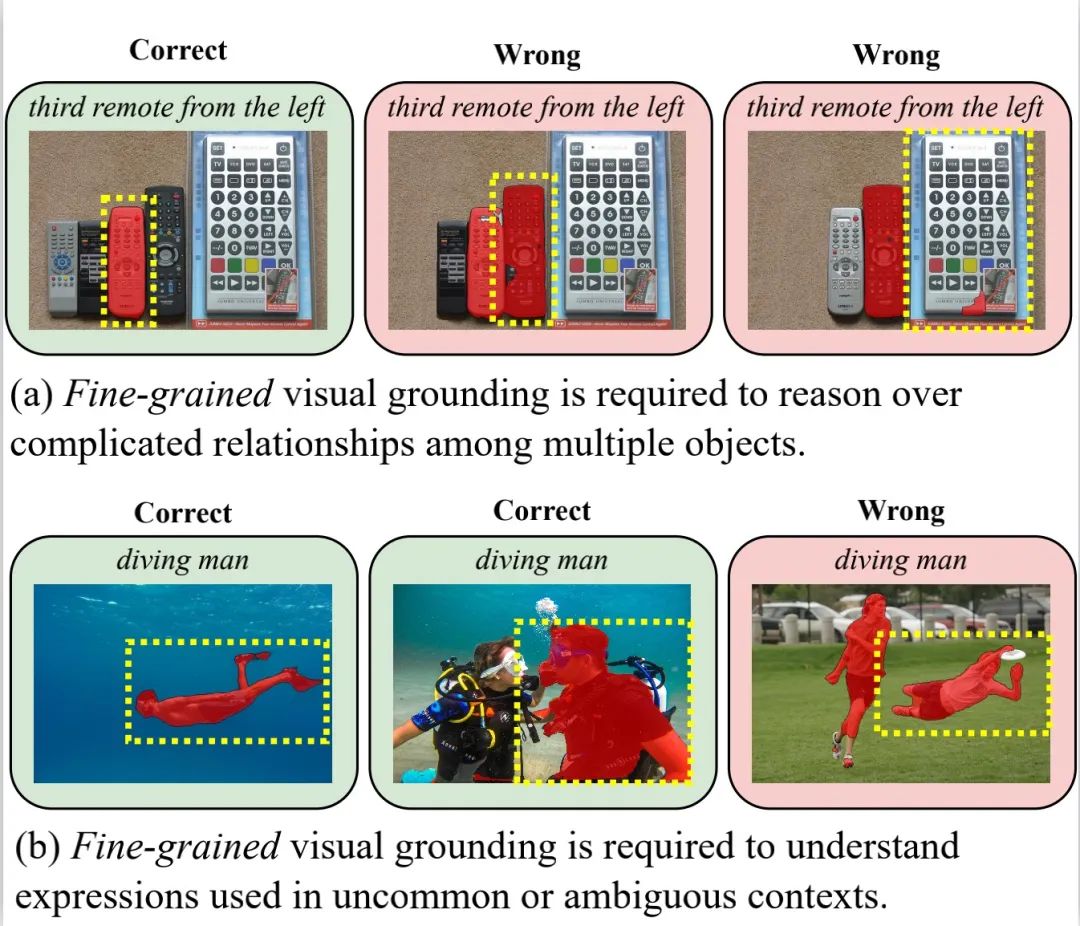
Figure 1 : Diagramme schématique de l'importance des capacités d'alignement langage-image à granularité fine pour RIS. Le masque rouge est le résultat de la prédiction de LAVT, l'un des algorithmes RIS les plus avancés actuellement, et la case en pointillés jaunes est l'annotation correcte. La recherche actuelle de RIS se concentre principalement sur la conception de nouvelles fonctions de perte ou sur l'introduction d'architectures/modules de réseau innovants pour améliorer l'alignement de la distribution langage-image. Malgré des progrès significatifs, il existe encore deux problèmes fondamentaux qui conduisent à leur insuffisance en matière de base visuelle fine : 1 Ces méthodes reposent principalement sur le niveau de la phrase. Les caractéristiques du langage effectuent un alignement langage-image, ce qui entraîne leur faiblesse. capacité d’alignement langue-image au niveau du texte. 2. Ces méthodes manquent souvent de signaux de supervision explicites pendant le processus de formation et ne peuvent pas apprendre efficacement au modèle à effectuer un alignement précis, ce qui entraîne de mauvaises performances dans le traitement de langages référentiels complexes.法 Figure 2 : Les lacunes de l'algorithme existant
Dans un récent travail CVPR 2024, l'équipe de recherche conjointe du Département d'automatisation de l'Université Tsinghua et de l'Institut central de recherche Bosch a conçu un nouveau La tâche auxiliaire Mask Grounding . Cette tâche vise à apprendre explicitement au modèle à apprendre des correspondances fines entre le texte et les objets visuels en masquant aléatoirement des parties de mots du texte et en laissant l'algorithme apprendre à prédire leur véritable identité. En outre, ils ont également proposé un nouveau module d'alignement intermodal et une nouvelle fonction de perte d'alignement intermodal (Cross-modal Alignment Loss) pour réduire davantage l'écart entre le langage et les images. Sur la base de ces technologies, ils ont conçu une nouvelle architecture de réseau de segmentation d'instances Mask-grounded Network (MagNet). Titre de l'article : Mask Grounding for Referring Image Segmentation
Adresse de l'article : https://arxiv.org/abs/2312.12198
- Dans RefCOCO, RefCOCO + etG -Réf activé Dans l'ensemble de données, MagNet a largement surpassé tous les algorithmes optimaux précédents, améliorant considérablement l'indicateur de base du taux global d'intersection sur union (oIoU) de 2,48 points de pourcentage. Les résultats de visualisation confirment également que MagNet présente d'excellentes performances dans le traitement de scènes et d'expressions linguistiques complexes.
Méthode
MagNet se compose de 3 modules indépendants et complémentaires, à savoir Mask Grounding, Cross-modal Alignment Module et Cross-modal Alignment Loss. 1.Masque de mise à la terre
Figure 3 : Organigramme de mise à la terre du masque Comme le montre la figure 3, compte tenu de l'image d'entrée, de l'expression référentielle correspondante et du masque de segmentation, l'auteur sélectionne au hasard une partie du vocabulaire des phrases et le remplace par un jeton de masque spécial à apprendre. Le modèle est ensuite entraîné pour prédire l’identité réelle de ces mots remplacés. En prédisant avec succès l'identité du jeton masqué, le modèle est capable de comprendre quels mots du texte correspondent à quelles parties de l'image, apprenant ainsi des capacités d'alignement langage-image à granularité fine. Pour effectuer cette tâche auxiliaire, les coordonnées centrales de la région du masque sont d'abord extraites et transmises à un MLP à 2 couches pour coder les caractéristiques du masque de segmentation. Dans le même temps, une couche linéaire est utilisée pour mapper les caractéristiques du langage aux mêmes dimensions que les caractéristiques de l’image. Ensuite, ces caractéristiques sont traitées conjointement à l'aide du prédicteur de jeton de masque proposé, et le module de mécanisme d'attention est utilisé pour la prédiction du jeton de masque. Bien que Mask Grounding nécessite un passage supplémentaire via l'encodeur de langage pour traiter les expressions masquées, le coût de calcul global est presque négligeable car l'encodeur de langage est si petit. Module d'alignement intermodal (CAM)
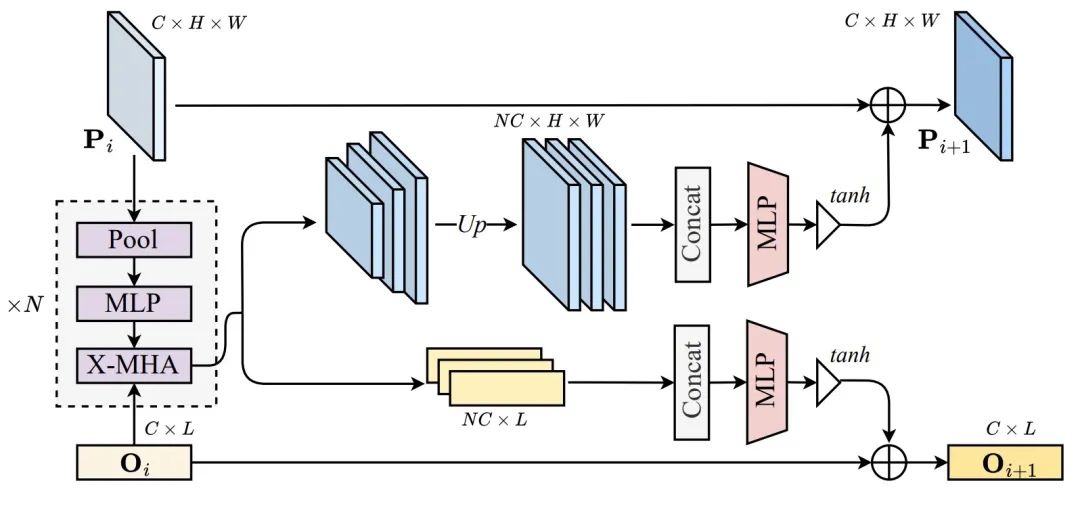
Comme le montre la figure 4, afin d'améliorer encore les performances du modèle, les auteurs ont également proposé un module d'alignement intermodal (CAM) pour améliorer l'effet d'alignement langue-image. en injectant un contexte global au préalable dans les caractéristiques de l'image avant d'effectuer la fusion langage-image. CAM génère d'abord K cartes de caractéristiques de différentes échelles de pyramide en utilisant des opérations de pooling avec différentes tailles de fenêtre. Ensuite, chaque carte de caractéristiques passe par un MLP à 3 couches pour mieux extraire les informations globales et effectue une opération d'attention croisée avec une autre modalité. Ensuite, toutes les entités en sortie sont suréchantillonnées à la taille de la carte des entités d'origine par interpolation bilinéaire et concaténées dans la dimension du canal. Par la suite, un MLP à 2 couches est utilisé pour réduire le nombre de canaux de fonctionnalités concaténés aux dimensions d'origine. Pour éviter que les signaux multimodaux ne submergent le signal d'origine, une unité fermée avec non-linéarité Tanh est utilisée pour moduler la sortie finale. Enfin, cette fonctionnalité fermée est rajoutée aux fonctionnalités d'entrée et transmise à l'étape suivante de l'encodeur d'image ou de langage. Dans l'implémentation des auteurs, CAM est ajouté à la fin de chaque étape des encodeurs d'image et de langage. 3. Perte d'alignement intermodal (CAL)
Pour superviser le modèle afin d'aligner les caractéristiques du langage et de l'image, auteur A une nouvelle fonction de perte d'alignement intermodal (CAL) est proposée. La figure 5 montre la formule mathématique de cette fonction de perte. Contrairement aux travaux précédents, CAL prend en compte à la fois l’alignement pixel à pixel (P2P) et pixel à texte (P2T). Un alignement précis pixel à pixel garantit que le modèle peut segmenter et générer des masques de segmentation avec des formes et des limites précises, tandis qu'un alignement précis pixel à texte permet au modèle d'associer correctement les descriptions de texte aux régions d'image auxquelles elles correspondent. Dans le tableau 1, l'auteur utilise la métrique oIoU pour évaluer MagNet et comparer ses performances avec les algorithmes de pointe existants. Les données de test sont RefCOCO, RefCOCO + et G-Ref. Dans les paramètres d'ensemble de données simples et multiples/supplémentaires, les performances de MagNet sont entièrement SOTA sur ces ensembles de données.
Tableau 1 : Résultats expérimentaux 视 Résultats de visualisation Figure 6 : Résultats de visualisation de l'aimant dans la figure 6, nous pouvons voir que la visualisation de l'aimant Les résultats sont également remarquables , surpassant le LAVT de base dans de nombreux scénarios difficiles.
Cet article se penche sur les défis et les enjeux actuels dans le domaine de la segmentation de référence (RIS), en particulier les lacunes dans l'alignement fin langage-image. En réponse à ces problèmes, des chercheurs de l'Université Tsinghua et de l'Institut central de recherche Bosch ont proposé une nouvelle méthode appelée MagNet, qui améliore considérablement le langage en introduisant la tâche auxiliaire Mask Grounding, un module d'alignement intermodal et une fonction de perte d'alignement intermodal. l'effet d'alignement entre les images. Les expériences prouvent que MagNet atteint des performances nettement meilleures sur les ensembles de données RefCOCO, RefCOCO+ et G-Ref, surpassant les algorithmes de pointe précédents et démontrant de fortes capacités de généralisation. Les résultats de visualisation confirment également la supériorité de MagNet dans le traitement de scènes et d'expressions linguistiques complexes. Cette recherche fournit une inspiration utile pour le développement ultérieur du domaine de la segmentation de référence et devrait favoriser de plus grandes percées dans ce domaine.
Ce document provient du Département d'automatisation de l'Université Tsinghua (https://www.au.tsinghua.edu.cn) et de l'Institut central de recherche Bosch (https:// www.bosch.com/research/). Parmi eux, Zhuang Rongxian, le premier auteur de l'article, est doctorant à l'Université Tsinghua et est en stage à la Bosch Academia Sinica ; le chef du projet est le Dr Qiu Xuchong, scientifique principal en R&D à la Bosch Academia Sinica ; Professeur Huang Gao du Département d'automatisation de l'Université Tsinghua.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!