
Maison >Périphériques technologiques >IA >NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !

- PHPzavant
- 2024-04-17 18:22:161047parcourir
Écrit au début et point de départ
Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, la prédiction et la planification des mouvements sont revisitées, tandis qu'un cadre de planification des mouvements plus raisonnable est conçu. Sur l'ensemble de données nuScenes, SparseAD atteint des performances de pointe pour l'ensemble des tâches dans une approche de bout en bout et réduit l'écart de performances entre le paradigme de bout en bout et les approches à tâche unique.
Contexte de terrain
Les systèmes de conduite autonome doivent prendre les bonnes décisions dans des scénarios de conduite complexes pour garantir la sécurité et le confort de conduite. En règle générale, les systèmes de conduite autonome intègrent plusieurs tâches telles que la détection, le suivi, la cartographie en ligne, la prédiction de mouvement et la planification. Comme le montre la figure 1a, le paradigme modulaire traditionnel divise les systèmes complexes en plusieurs tâches individuelles, chacune étant optimisée indépendamment. Dans ce paradigme, un post-traitement manuel est requis entre des modules indépendants à tâche unique, ce qui rend l'ensemble du processus plus fastidieux. D'un autre côté, en raison de la perte de compression des informations de scène entre les tâches empilées, des erreurs dans l'ensemble du système s'accumulent, ce qui peut entraîner des problèmes de sécurité potentiels.
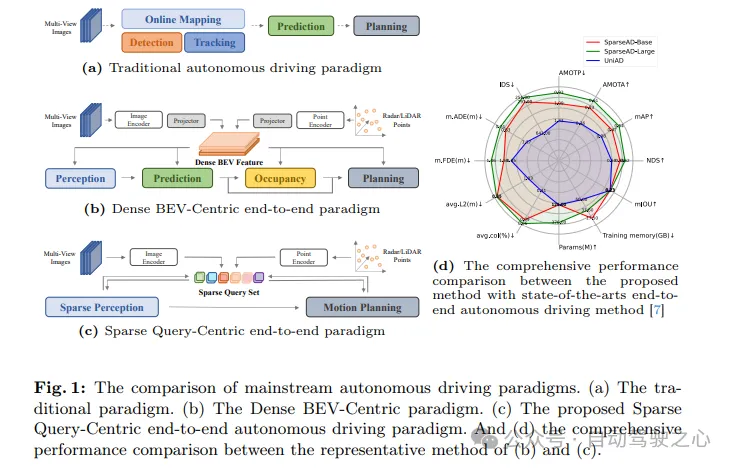
Concernant les problèmes ci-dessus, le système de conduite autonome de bout en bout prend les données brutes du perceptron en entrée et renvoie les résultats de la planification de manière plus concise. Les premiers travaux proposaient de sauter les tâches intermédiaires et de prédire les résultats de la planification directement à partir des données brutes du perceptron. Bien que cette approche soit plus simple, elle n’est pas satisfaisante en termes d’optimisation du modèle, d’interprétabilité et de performances de planification. Un autre paradigme à multiples facettes avec une meilleure interprétabilité consiste à intégrer plusieurs parties de la conduite autonome dans un modèle modulaire de bout en bout, qui introduit une supervision multidimensionnelle pour améliorer la compréhension des scénarios de conduite complexes et apporte la capacité d'effectuer plusieurs tâches à la fois.
Comme le montre la figure 1b, dans les méthodes modulaires de bout en bout les plus avancées, l'ensemble du scénario de conduite est caractérisé par une collection dense de fonctionnalités de vue à vol d'oiseau (BEV) qui incluent des informations multi-capteurs et temporelles et servent de Entrées full-stack qui pilotent les tâches, notamment la perception, la prédiction et la planification. Bien que les fonctionnalités BEV densément agrégées jouent un rôle clé dans la réalisation de la multimodalité et du multitâche dans l’espace et dans le temps, les méthodes de bout en bout précédentes utilisant la représentation BEV sont résumées sous le nom de paradigme Dense BEV-Centric. Malgré la simplicité et l’interprétabilité de ces méthodes, leurs performances sur chaque sous-tâche de la conduite autonome sont encore loin derrière les méthodes correspondantes à tâche unique. De plus, dans le cadre du paradigme Dense BEV-Centric, la fusion temporelle à long terme et la fusion multimodale sont principalement réalisées grâce à plusieurs cartes de fonctionnalités BEV, ce qui entraîne une augmentation significative des coûts de calcul et de l'utilisation de la mémoire, et alourdit la charge réelle. déploiement. .
Un nouveau paradigme de conduite autonome de bout en bout centré sur la recherche éparse (SparseAD) est proposé ici. Dans ce paradigme, les éléments spatiaux et temporels de l'ensemble de la scène de conduite sont représentés par des tables de recherche clairsemées, abandonnant la fonction traditionnelle d'ensemble dense Bird's Eye View (BEV), comme le montre la figure 1c. Cette représentation clairsemée permet aux modèles de bout en bout d'utiliser plus efficacement des informations historiques plus longues et de s'adapter à davantage de modes et de tâches, tout en réduisant considérablement les coûts de calcul et l'empreinte mémoire.
Repensé l'architecture modulaire de bout en bout et l'a simplifiée en une structure concise composée d'une perception clairsemée et d'un planificateur de mouvement. Dans le module de perception clairsemée, un décodeur temporel universel est utilisé pour unifier les tâches de perception, notamment la détection, le suivi et la cartographie en ligne. Dans ce processus, les fonctionnalités multicapteurs et les enregistrements historiques sont traités comme des jetons, tandis que les requêtes d'objets et les requêtes de carte représentent respectivement les obstacles et les éléments de la route dans la scène de conduite. Dans le planificateur de mouvement, des requêtes de perception clairsemée sont utilisées comme représentation de l'environnement, et des prédictions de mouvement multimodales sont effectuées simultanément sur le véhicule et les agents environnants pour obtenir plusieurs solutions de planification initiales pour le véhicule autonome. Par la suite, les contraintes de conduite multidimensionnelles sont pleinement prises en compte pour générer les résultats finaux de la planification.
Principales contributions :
- Proposer un nouveau paradigme de conduite autonome de bout en bout (SparseAD) centré sur les requêtes clairsemées, qui abandonne la méthode traditionnelle de représentation dense à vol d'oiseau (BEV) et a donc un énorme potentiel pour s'adapter efficacement à davantage de modalités et de tâches.
- Simplifiez l'architecture modulaire de bout en bout en deux parties : la détection éparse et la planification de mouvement. Dans la partie perception clairsemée, les tâches de perception telles que la détection, le suivi et la cartographie en ligne sont unifiées de manière totalement clairsemée, tandis que dans la partie planification du mouvement, la prédiction et la planification du mouvement sont effectuées dans un cadre plus raisonnable ;
- Sur l'ensemble de données nuScenes, SparseAD atteint des performances de pointe parmi les méthodes de bout en bout et réduit considérablement l'écart de performances entre le paradigme de bout en bout et les méthodes à tâche unique. Cela démontre pleinement l’énorme potentiel du paradigme de bout en bout clairsemé proposé. SparseAD améliore non seulement les performances et l'efficacité des systèmes de conduite autonome, mais offre également de nouvelles orientations et possibilités pour les recherches et applications futures.
Structure du réseau SparseAD
Comme le montre la figure 1c, dans le paradigme proposé centré sur les requêtes clairsemées, différentes requêtes clairsemées représentent entièrement l'ensemble de la scène de conduite et ne sont pas seulement responsables du transfert d'informations et de l'interaction entre les modules. également propagé sur plusieurs tâches de bout en bout à des fins d'optimisation. Contrairement aux précédentes méthodes centrées sur la vue à vol d'oiseau (BEV) dense, aucune projection de vue et les fonctionnalités BEV denses ne sont utilisées dans SparseAD, évitant ainsi de lourdes charges de calcul et de mémoire. L'architecture détaillée de SparseAD est présentée dans la figure 2.
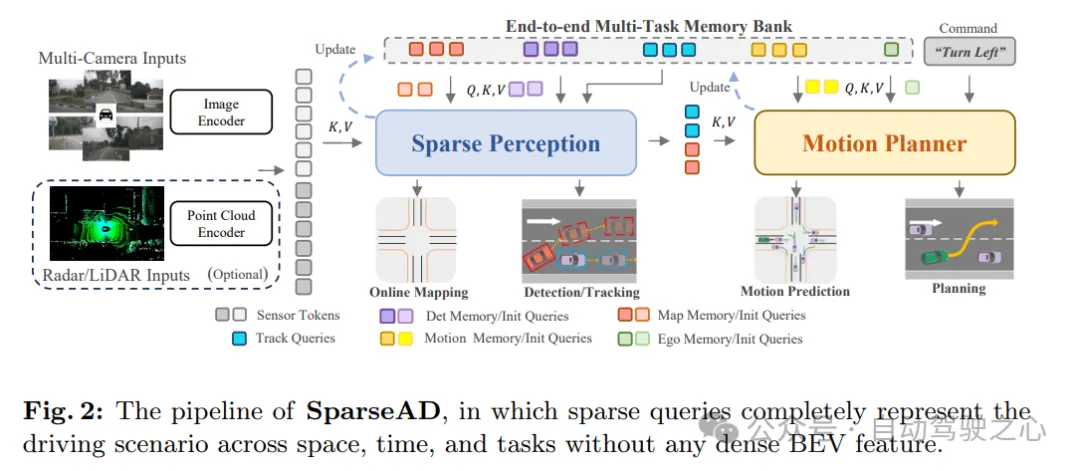
D'après le schéma architectural, SparseAD se compose principalement de trois parties, dont l'encodeur de capteur, la perception clairsemée et le planificateur de mouvement. Plus précisément, l'encodeur de capteur prend en entrée des images de caméra multi-vues, des points radar ou lidar et les code en caractéristiques de grande dimension. Ces caractéristiques sont ensuite entrées dans le module de détection clairsemée sous forme de jetons de capteur ainsi que d'intégrations de position (PE). Dans le module de détection clairsemée, les données brutes des capteurs seront regroupées dans une variété de requêtes de détection clairsemées, telles que des requêtes de détection, des requêtes de suivi et des requêtes cartographiques, qui représentent respectivement différents éléments de la scène de conduite et seront ensuite propagées en aval. Tâches. Dans le planificateur de mouvement, la requête de perception est traitée comme une représentation clairsemée de la scène de conduite et est pleinement exploitée pour tous les agents environnants et le véhicule autonome. Dans le même temps, plusieurs contraintes de conduite sont prises en compte pour générer un plan final à la fois sûr et dynamique.
De plus, une bibliothèque de mémoire multitâche de bout en bout est introduite dans l'architecture pour stocker uniformément les informations de synchronisation de l'ensemble de la scène de conduite, ce qui permet au système de bénéficier de l'agrégation d'informations historiques à long terme pour compléter tâches de conduite complètes.
Comme le montre la figure 3, le module de perception clairsemée de SparseAD unifie plusieurs tâches de perception de manière clairsemée, notamment la détection, le suivi et la cartographie en ligne. Plus précisément, il existe deux décodeurs temporels structurellement identiques qui exploitent les informations historiques à long terme provenant de la banque de mémoire. L’un des décodeurs est utilisé pour la détection d’obstacles et l’autre pour la cartographie en ligne.
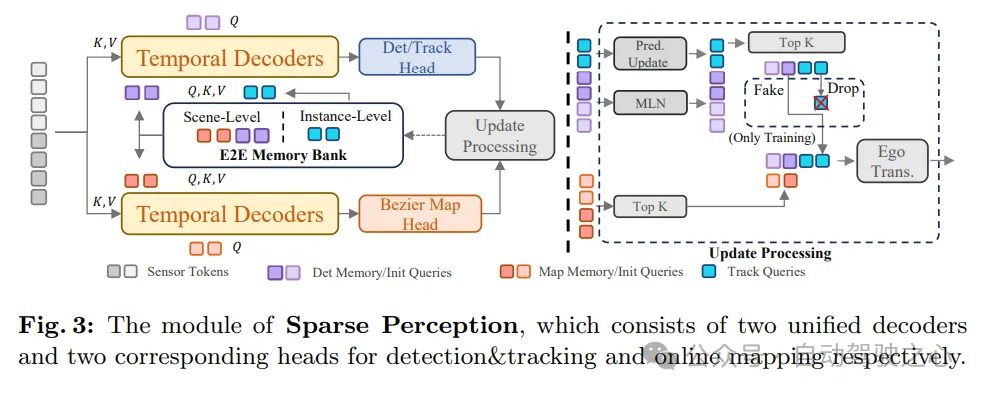
Après l'agrégation des informations via des requêtes de perception correspondant à différentes tâches, les têtes de détection et de suivi et la partie cartographique sont utilisées pour décoder et sortir respectivement les obstacles et les éléments cartographiques. Après cela, un processus de mise à jour est effectué, qui filtre et enregistre la requête de détection à haute confiance de la trame actuelle et met à jour la banque de mémoire en conséquence, ce qui profitera au processus de détection de la trame suivante.
De cette façon, le module de perception clairsemée de SparseAD permet une perception efficace et précise de la scène de conduite, fournissant une base d'informations importante pour la planification ultérieure des mouvements. Dans le même temps, en utilisant les informations historiques de la banque de mémoire, le module peut encore améliorer la précision et la stabilité de la perception et garantir le fonctionnement fiable du système de conduite autonome.
Perception clairsemée
En termes de perception des obstacles, la détection et le suivi des articulations sont adoptés au sein d'un décodeur unifié sans aucun post-traitement manuel supplémentaire. Il existe un déséquilibre important entre les requêtes de détection et de suivi, ce qui peut entraîner une dégradation significative des performances de détection. Afin d'atténuer les problèmes ci-dessus, les performances de détection d'obstacles ont été améliorées sous plusieurs angles. Premièrement, un mécanisme de mémoire à deux niveaux est introduit pour propager les informations temporelles à travers les trames. Parmi eux, la mémoire au niveau de la scène conserve les informations de requête sans corrélation entre images, tandis que la mémoire au niveau de l'instance maintient la correspondance entre les images adjacentes des obstacles de suivi. Deuxièmement, compte tenu des origines et des tâches différentes des deux, différentes stratégies de mise à jour sont adoptées pour les mémoires au niveau de la scène et au niveau de l'instance. Plus précisément, la mémoire au niveau de la scène est mise à jour via MLN, tandis que la mémoire au niveau de l'instance est mise à jour avec les prédictions futures pour chaque obstacle. De plus, pendant le processus de formation, une stratégie d'amélioration est également adoptée pour la requête de suivi afin d'équilibrer la supervision entre les deux niveaux de mémoire, améliorant ainsi les performances de détection et de suivi. Ensuite, en détectant et en suivant la tête, une boîte englobante 3D avec des attributs et un identifiant unique peut être décodée à partir de la requête de détection ou de suivi, puis utilisée dans des tâches en aval.
La construction de cartes en ligne est une tâche complexe et importante. Selon les connaissances actuelles, les méthodes de construction de cartes en ligne existantes reposent principalement sur des caractéristiques denses de vue à vol d'oiseau (BEV) pour représenter l'environnement de conduite. Cette approche a des difficultés à étendre la portée de détection ou à exploiter les informations historiques car elle nécessite de grandes quantités de mémoire et de ressources informatiques. Nous croyons fermement que tous les éléments cartographiques peuvent être représentés de manière clairsemée. C'est pourquoi nous essayons de réaliser la construction de cartes en ligne selon le paradigme clairsemé. Plus précisément, la même structure de décodeur temporel que dans la tâche de perception d'obstacles est adoptée. Initialement, les requêtes cartographiques avec des catégories antérieures sont initialisées pour être uniformément réparties sur le plan de conduite. Dans le décodeur temporel, les requêtes cartographiques interagissent avec les marqueurs de capteurs et les marqueurs de mémoire historique. Ces marqueurs de mémoire historique sont en réalité composés de requêtes cartographiques hautement fiables provenant d’images précédentes. La requête de carte mise à jour transporte ensuite des informations valides sur les éléments de carte de la trame actuelle et peut être poussée vers la banque de mémoire pour être utilisée dans des trames futures ou des tâches en aval.
Évidemment, le processus de construction d'une carte en ligne est à peu près le même que celui de la perception des obstacles. Autrement dit, les tâches de détection, notamment la détection, le suivi et la construction de cartes en ligne, sont unifiées dans une approche commune clairsemée qui est plus efficace lors d'une mise à l'échelle vers des portées plus grandes (par exemple, 100 m × 100 m) ou une fusion à long terme, et ne nécessite aucune opération complexe. (comme l'attention déformable ou l'attention multipoint). À notre connaissance, il s’agit du premier à implémenter de manière clairsemée la construction de cartes en ligne dans une architecture de détection unifiée. Par la suite, la tête de carte de Bézier par morceaux est utilisée pour renvoyer les points de contrôle de Bézier par morceaux de chaque élément de carte clairsemé, et ces points de contrôle peuvent être facilement transformés pour répondre aux exigences des tâches en aval.
Motion Planner
Nous avons réexaminé le problème de la prédiction et de la planification des mouvements dans les systèmes de conduite autonome et avons constaté que de nombreuses méthodes précédentes ignoraient la dynamique de l'ego-véhicule lors de la prévision du mouvement des véhicules environnants. Bien que cela ne soit pas évident dans la plupart des situations, cela peut constituer un risque potentiel dans des scénarios tels que les intersections où il existe une interaction étroite entre les véhicules à proximité et le véhicule hôte. Inspiré par cela, un cadre de planification de mouvement plus raisonnable a été conçu. Dans ce cadre, le prédicteur de mouvement prédit simultanément le mouvement des véhicules environnants et de votre propre véhicule. Ensuite, les résultats de prédiction du propre véhicule sont utilisés comme a priori de mouvement dans les optimiseurs de planification ultérieurs. Au cours du processus de planification, nous prenons en compte différents aspects des contraintes pour produire un résultat de planification final qui répond à la fois aux exigences de sécurité et de dynamique.
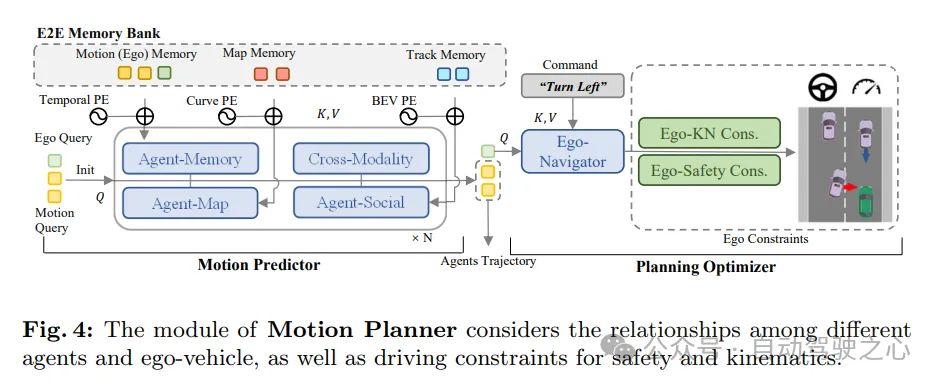
Comme le montre la figure 4, le planificateur de mouvement de SparseAD traite les requêtes de perception (y compris les requêtes de trajectoire et les requêtes de carte) comme une représentation clairsemée de la scène de conduite actuelle. Les requêtes de mouvement multimodales sont utilisées comme moyen pour permettre la compréhension des scénarios de conduite, la perception des interactions entre tous les véhicules (y compris le propre véhicule) et le jeu de différentes possibilités futures. La requête de mouvement multimodal du véhicule est ensuite introduite dans un optimiseur de planification, qui prend en compte les contraintes de conduite, notamment les instructions de haut niveau, la sécurité et la dynamique.
Prédicteur de mouvement. Suivant les méthodes précédentes, la perception et l'intégration entre les requêtes de mouvement et les représentations de scènes de conduite actuelles (y compris les requêtes de trajectoire et les requêtes de carte) sont réalisées via des couches de transformateur standard. De plus, l'agent auto-véhiculaire et l'interaction intermodale sont appliqués pour modéliser conjointement l'interaction entre les agents environnants et l'auto-véhicule dans les futures scènes spatio-temporelles. Grâce à la synergie des modules au sein et entre les structures d'empilement multicouches, les requêtes de mouvement sont capables de regrouper de riches informations sémantiques provenant d'environnements statiques et dynamiques.
En plus de ce qui précède, deux stratégies sont également introduites pour améliorer encore les performances du prédicteur de mouvement. Premièrement, une prédiction simple et directe est réalisée à l’aide de la mémoire temporelle au niveau de l’instance de la requête de trajectoire dans le cadre de l’initialisation de la requête de mouvement de l’agent environnant. De cette manière, le prédicteur de mouvement peut bénéficier des connaissances préalables acquises lors des tâches en amont. Deuxièmement, grâce à la bibliothèque de mémoire de bout en bout, les informations utiles peuvent être assimilées à partir des requêtes de mouvement historiques enregistrées en continu via l'agrégateur de mémoire de l'agent à un coût presque négligeable.
Il est à noter que la requête de mouvement multimodale de cette voiture est mise à jour en même temps. De cette manière, le mouvement préalable du propre véhicule peut être obtenu, ce qui peut faciliter davantage le processus d'apprentissage de la planification.
Optimiseur de planification. Grâce au mouvement préalable fourni par le prédicteur de mouvement, une meilleure initialisation est obtenue, ce qui entraîne moins de détours pendant l'entraînement. En tant qu'élément clé du planificateur de mouvement, la conception de la fonction de coût est cruciale car elle affectera grandement, voire déterminera la qualité de la performance finale. Dans le planificateur de mouvement SparseAD proposé, les contraintes de sécurité et de dynamique sont principalement prises en compte, dans le but de générer des résultats de planification satisfaisants. Plus précisément, en plus des contraintes déterminées dans VAD, il se concentre également sur la relation de sécurité dynamique entre le véhicule et les agents à proximité, et considère leurs positions relatives dans les instants futurs. Par exemple, si l'agent i continue de rester dans la zone avant gauche par rapport au véhicule, empêchant ainsi le véhicule de changer de voie vers la gauche, alors l'agent i obtiendra une étiquette gauche, indiquant que l'agent i impose une contrainte vers la gauche au véhicule. . Les contraintes sont donc classées comme étant avant, arrière ou aucune dans le sens longitudinal, et comme gauche, droite ou aucune dans le sens transversal. Dans le planificateur, nous décodons la relation entre les autres agents et le véhicule dans les directions horizontale et verticale à partir de la requête correspondante. Ce processus implique de déterminer les probabilités de toutes les contraintes entre les autres agents et le propre véhicule dans ces directions. Ensuite, nous utilisons la perte focale comme fonction de coût de la relation Ego-Agent (EAR) pour capturer efficacement les risques potentiels apportés par les agents proches :
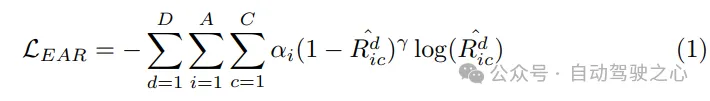
Étant donné que la trajectoire planifiée doit suivre les lois dynamiques de l'exécution du système de contrôle, dans la planification du mouvement Des tâches auxiliaires sont intégrées dans la machine pour favoriser l'apprentissage de l'état dynamique du véhicule. Décodez les états tels que la vitesse, l'accélération et l'angle de lacet à partir de la requête de votre propre véhicule Qego et supervisez ces états à l'aide des pertes dynamiques :
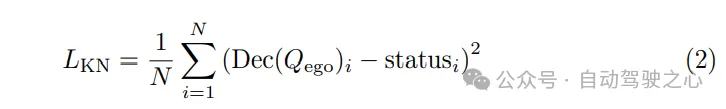
Résultats expérimentaux
Des expériences approfondies ont été menées sur l'ensemble de données nuScenes pour prouver l'efficacité et supériorité de la méthode. Pour être juste, la performance de chaque tâche complète sera évaluée et comparée aux méthodes précédentes. Les expériences de cette section utilisent trois configurations différentes de SparseAD, à savoir SparseAD-B et SparseAD-L, qui utilisent uniquement l'entrée d'image, et SparseAD-BR, qui utilise un nuage de points radar et une entrée multimodale d'image. SparseAD-B et SparseAD-BR utilisent tous deux V2-99 comme réseau fédérateur d'image et la résolution de l'image d'entrée est de 1 600 × 640. SparseAD-L utilise en outre ViTLarge comme réseau fédérateur d'image et la résolution de l'image d'entrée est de 1 600 × 800.
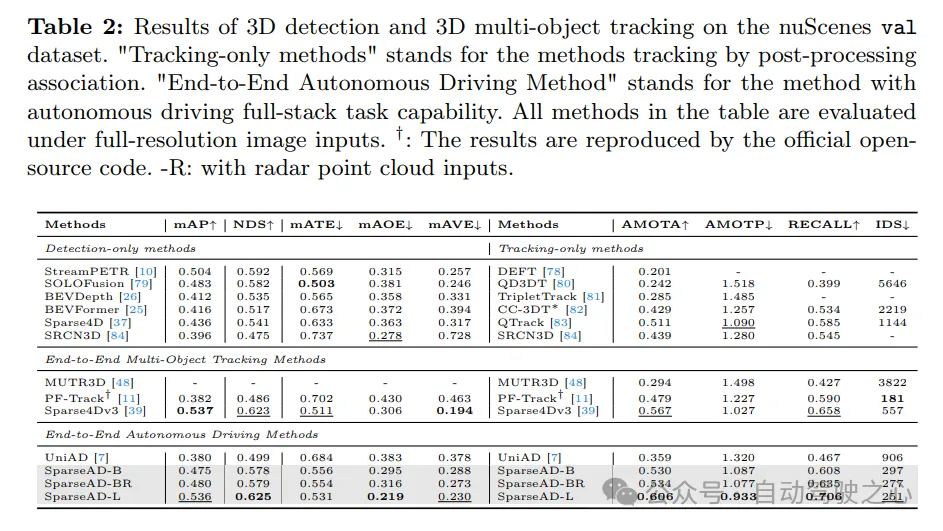
Les résultats de la détection 3D et du suivi multi-cibles 3D sur l'ensemble de données de validation nuScenes sont les suivants. Les « méthodes de suivi uniquement » font référence aux méthodes qui sont suivies via une corrélation de post-traitement. « Méthode de conduite autonome de bout en bout » fait référence à une méthode capable d'effectuer des tâches de conduite autonome complètes. Toutes les méthodes du tableau sont évaluées avec une entrée d’image en pleine résolution. † : Les résultats sont reproduits via le code open source officiel. -R : indique que l'entrée du nuage de points radar est utilisée.
La comparaison des performances avec la méthode de cartographie en ligne est la suivante, les résultats sont évalués au seuil de [1.0m, 1.5m, 2.0m]. ‡ : Résultat reproduit via le code open source officiel. † : Sur la base des besoins du module de planification de SparseAD, nous avons subdivisé la limite en segments de route et voies et les avons évalués séparément. * : Coût du réseau fédérateur et du module de détection clairsemé. -R : indique que l'entrée du nuage de points radar est utilisée.

Résultats multi-tâches
Conscience des obstacles. Les performances de détection et de suivi de SparseAD sont comparées à d'autres méthodes sur l'ensemble de validation nuScenes dans l'onglet 2. De toute évidence, SparseAD-B fonctionne bien dans les méthodes de détection uniquement, de suivi uniquement et de suivi multi-objets de bout en bout les plus populaires, tout en fonctionnant de manière comparable aux méthodes SOTA telles que StreamPETR et QTrack sur les tâches correspondantes. En évoluant avec un réseau fédérateur plus avancé, SparseAD-Large atteint des performances globalement meilleures, avec mAP de 53,6 %, NDS de 62,5 % et AMOTA de 60,6 %, ce qui est globalement meilleur que la meilleure méthode précédente Sparse4Dv3.
Cartographie en ligne. L'onglet 3 montre les résultats de la comparaison des performances de cartographie en ligne entre SparseAD et d'autres méthodes précédentes sur l'ensemble de validation nuScenes. Il convient de noter qu'en fonction des besoins de planification, nous avons subdivisé la limite en segments de route et en voies et les avons évalués séparément, tout en étendant la portée des 60 m × 30 m habituels à 102,4 m × 102,4 m pour être cohérente avec la perception des obstacles. Sans perdre en équité, SparseAD atteint 34,2 % de mAP de bout en bout sans aucune représentation BEV dense, ce qui est meilleur que la plupart des méthodes précédemment populaires, telles que HDMapNet, VectorMapNet et MapTR, en termes de performances. termes de coût et de coût de la formation. Bien que les performances soient légèrement inférieures à celles de StreamMapNet, notre méthode prouve que la cartographie en ligne peut être réalisée de manière uniforme et clairsemée sans aucune représentation BEV dense, ce qui a des implications pour le déploiement pratique de la conduite autonome de bout en bout à un coût nettement inférieur. Certes, la manière d’utiliser efficacement les informations utiles provenant d’autres modalités (telles que le radar) reste une tâche qui mérite d’être approfondie. Nous pensons qu’il reste encore beaucoup de place à l’exploration, mais de manière éparse.
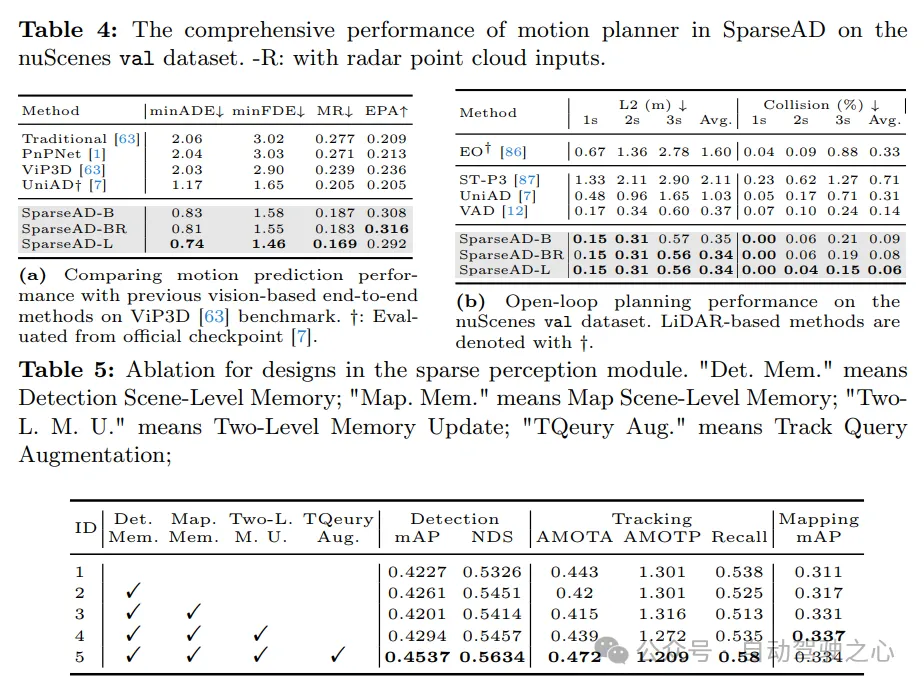
Prédictions sportives. Les résultats de la comparaison de la prédiction de mouvement sont présentés dans le Tab. 4a, où les indicateurs sont cohérents avec VIP3D. SparseAD atteint les meilleures performances parmi toutes les méthodes de bout en bout, avec le minADE le plus bas de 0,83 m, le minFDE de 1,58 m, un taux d'échec de 18,7 % et le plus élevé de 0,308 EPA, ce qui constitue un énorme avantage. De plus, grâce à l'efficacité et à l'évolutivité du paradigme du centre de requêtes clairsemées, SparseAD peut s'étendre efficacement à davantage de modalités et bénéficier du réseau fédérateur avancé pour améliorer encore considérablement les performances de prédiction.
Planification. Les résultats de la planification sont présentés dans le Tab. 4b. Grâce à la conception supérieure du module de perception en amont et du planificateur de mouvement, toutes les versions de SparseAD atteignent des performances de pointe sur l'ensemble de données de validation nuScenes. Plus précisément, SparseAD-B atteint le taux d'erreur L2 et de collision moyen le plus bas par rapport à toutes les autres méthodes, y compris UniAD et VAD, ce qui démontre la supériorité de notre approche et de notre architecture. Semblable aux tâches en amont, notamment la perception des obstacles et la prédiction de mouvement, SparseAD améliore encore les performances avec un radar ou un réseau fédérateur plus puissant.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Huawei Cloud et un certain nombre d'entreprises ont lancé une initiative d'action : construire conjointement un écosystème industriel ouvert pour la conduite autonome
- Développement Laravel : Comment utiliser Laravel Dusk pour les tests de bout en bout du navigateur ?
- Que faire si l'utilisation de la mémoire du système Windows 10 est trop élevée
- Comparaison de l'utilisation de la mémoire entre Win10 et Win7
- L'état du véhicule autonome est-il tout ce dont vous avez besoin pour une conduite autonome de bout en bout en boucle ouverte ?