
Maison >Périphériques technologiques >IA >L'IA aide la recherche sur l'interface cerveau-ordinateur, la technologie révolutionnaire de décodage neuronal de la parole de l'Université de New York, publiée dans la sous-journal Nature
L'IA aide la recherche sur l'interface cerveau-ordinateur, la technologie révolutionnaire de décodage neuronal de la parole de l'Université de New York, publiée dans la sous-journal Nature

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-17 08:40:051432parcourir

Auteur | Chen Xupeng
L'aphasie due à des anomalies du système nerveux peut entraîner de graves handicaps dans la vie et limiter la vie professionnelle et sociale des personnes.
Ces dernières années, le développement rapide de la technologie d’apprentissage profond et d’interface cerveau-ordinateur (BCI) a rendu possible le développement de prothèses neurovocales pouvant aider les personnes aphasiques à communiquer. Cependant, le décodage vocal des signaux neuronaux est confronté à des défis.
Récemment, des chercheurs de VideoLab et Flinker Lab de l'Université de Jordanie ont développé un nouveau type de synthétiseur vocal différenciable qui peut utiliser un réseau neuronal convolutif léger pour coder la parole en une série de paramètres vocaux interprétables (tels que la hauteur, le volume, le formant). fréquence, etc.), et ces paramètres sont synthétisés en parole via un réseau neuronal différenciable. Ce synthétiseur peut également analyser les paramètres de la parole (tels que la hauteur, le volume, les fréquences des formants, etc.) via un réseau neuronal convolutionnel léger, et resynthétiser la parole via un synthétiseur vocal différenciable.
Les chercheurs ont établi un système de décodage des signaux neuronaux hautement interprétable et applicable à des situations avec de petits volumes de données, en mappant les signaux neuronaux à ces paramètres vocaux sans changer la signification du contenu original.
La recherche s'intitulait « Un cadre de décodage neuronal de la parole exploitant l'apprentissage profond et la synthèse vocale » et a été publiée dans le magazine « Nature Machine Intelligence » le 8 avril 2024.

Lien papier : https://www.nature.com/articles/s42256-024-00824-8
Contexte de recherche
La plupart des tentatives de développement de décodeurs de parole neuronale reposent sur un A spécial type de données : données obtenues auprès de patients subissant une chirurgie de l'épilepsie via des enregistrements d'électrocorticographie (ECoG). En utilisant des électrodes implantées chez des patients épileptiques pour collecter des données sur le cortex cérébral lors de la production de la parole, ces données ont une résolution spatio-temporelle élevée et ont aidé les chercheurs à obtenir une série de résultats remarquables dans le domaine du décodage de la parole, contribuant ainsi à promouvoir le développement des interfaces cerveau-ordinateur. champ.
Le décodage vocal des signaux neuronaux est confronté à deux défis majeurs.
Tout d'abord, les données utilisées pour entraîner des modèles personnalisés de décodage neuronal à la parole sont très limitées dans le temps, généralement seulement une dizaine de minutes, tandis que les modèles d'apprentissage en profondeur nécessitent souvent une grande quantité de données d'entraînement pour être pilotés.
Deuxièmement, la prononciation humaine est très diversifiée. Même si la même personne prononce le même mot à plusieurs reprises, la vitesse, l'intonation et la hauteur de la parole changeront, ce qui ajoute de la complexité à l'espace de représentation construit par le modèle.
Les premières tentatives de décodage des signaux neuronaux en parole reposaient principalement sur des modèles linéaires. Les modèles ne nécessitaient généralement pas d'énormes ensembles de données d'entraînement et étaient hautement interprétables, mais la précision était très faible.
Les recherches récentes basées sur les réseaux de neurones profonds, notamment l'utilisation d'architectures de réseaux de neurones convolutifs et récurrents, se développent dans deux dimensions clés : la représentation latente intermédiaire de la parole simulée et la qualité de la parole synthétisée. Par exemple, certaines études décodent l'activité du cortex cérébral en espace de mouvement de la bouche, puis la convertissent en parole. Bien que les performances de décodage soient puissantes, la voix reconstruite ne semble pas naturelle.
D'un autre côté, certaines méthodes réussissent à reconstruire une parole naturelle en utilisant le vocodeur wavenet, le réseau contradictoire génératif (GAN), etc., mais leur précision est limitée. Récemment, dans une étude portant sur des patients porteurs de dispositifs implantés, des formes d'onde vocales à la fois précises et naturelles ont été obtenues en utilisant des caractéristiques HuBERT quantifiées comme espace de représentation intermédiaire et un synthétiseur vocal pré-entraîné pour convertir ces caractéristiques en parole.
Cependant, les fonctionnalités HuBERT ne peuvent pas représenter des informations acoustiques spécifiques au locuteur et peuvent uniquement générer des sons de haut-parleur fixes et unifiés. Des modèles supplémentaires sont donc nécessaires pour convertir ce son universel en la voix d'un patient spécifique. De plus, cette étude et la plupart des tentatives précédentes ont adopté une architecture non causale, ce qui peut limiter son utilisation dans les applications pratiques des interfaces cerveau-ordinateur nécessitant des opérations causales temporelles.
Cadre du modèle principal
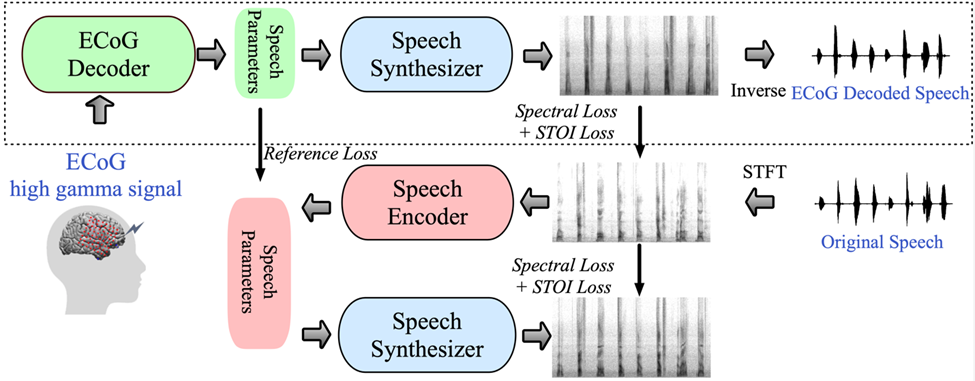
Pour relever ces défis, les chercheurs introduisent un nouveau cadre de décodage des signaux d'électroencéphalogramme (ECoG) à la parole dans cet article. Les chercheurs construisent une représentation intermédiaire de basse dimension (représentation latente de basse dimension), qui est générée par. un modèle de codage et de décodage de la parole utilisant uniquement le signal de parole (Figure 1).
Le cadre proposé par la recherche se compose de deux parties : l'une est le décodeur ECoG, qui convertit le signal ECoG en paramètres de parole acoustique que nous pouvons comprendre (tels que la hauteur, s'il est prononcé, le volume et la fréquence des formants, etc. ); l'autre partie est un synthétiseur vocal qui convertit ces paramètres vocaux en spectrogramme.
Les chercheurs ont construit un synthétiseur vocal différenciable, qui permet au synthétiseur vocal de participer à la formation lors de la formation du décodeur ECoG et d'optimiser conjointement pour réduire l'erreur de reconstruction du spectrogramme. Cet espace latent de faible dimension présente une forte interprétabilité, associé à un encodeur vocal léger pré-entraîné pour générer des paramètres vocaux de référence, aidant ainsi les chercheurs à créer un cadre de décodage neuronal efficace de la parole et à surmonter le problème de la rareté des données.
Ce cadre peut générer une parole naturelle très proche de la voix du locuteur, et la partie décodeur ECoG peut être connectée à différentes architectures de modèles d'apprentissage en profondeur et prend également en charge les opérations causales. Les chercheurs ont collecté et traité les données ECoG de 48 patients en neurochirurgie, en utilisant plusieurs architectures d'apprentissage profond (y compris la convolution, le réseau neuronal récurrent et le transformateur) comme décodeurs ECoG.
Le framework a démontré une grande précision sur divers modèles, parmi lesquels l'architecture convolutive (ResNet) a obtenu les meilleures performances, le coefficient de corrélation de Pearson (PCC) entre le spectrogramme original et décodé atteignant 0,806. Le cadre proposé par les chercheurs ne peut atteindre une grande précision que grâce à des opérations causales et un taux d'échantillonnage relativement faible (faible densité, espacement de 10 mm).
Les chercheurs ont également démontré qu’un décodage efficace de la parole peut être effectué à partir des hémisphères gauche et droit du cerveau, étendant ainsi l’application du décodage neuronal de la parole au cerveau droit.
Code open source lié à la recherche : https://github.com/flinkerlab/neural_speech_decoding
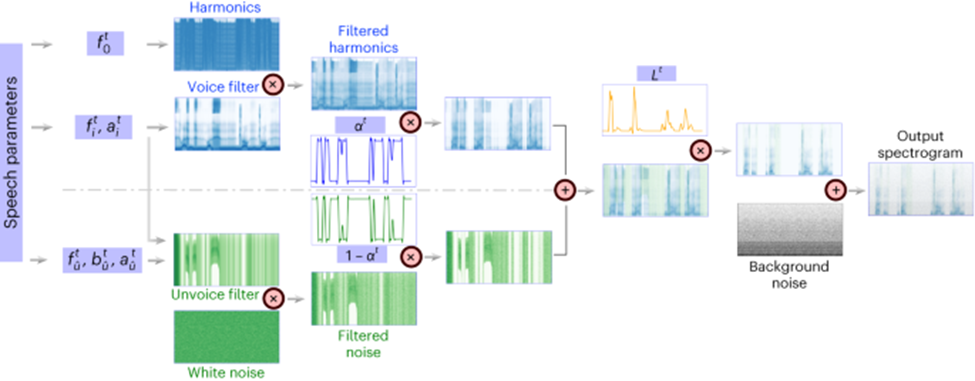
L'innovation importante de cette recherche est de proposer un synthétiseur vocal différentiable (synthétiseur vocal), qui rend la tâche de re-synthèse vocale très efficace et peut synthétiser des autocollants haute fidélité avec une très petite parole Audio adapté au son .
Le principe du synthétiseur vocal différenciable s'inspire du principe du système génératif humain et divise la parole en deux parties : la voix (utilisée pour modéliser les voyelles) et la non-voix (utilisée pour modéliser les consonnes) :
La partie vocale peut être utilisée en premier. le signal de fréquence génère des harmoniques, et le filtre composé des pics formants de F1-F6 est filtré pour obtenir les caractéristiques spectrales de la partie voyelle pour la partie Unvoice, le chercheur filtre le bruit blanc avec le filtre correspondant pour obtenir le spectre correspondant, qui peut être Les paramètres appris peuvent contrôler le rapport de mélange des deux parties à chaque instant ; après cela, le signal d'intensité sonore est amplifié et un bruit de fond est ajouté pour obtenir le spectre vocal final. Sur la base de ce synthétiseur vocal, cet article conçoit un cadre efficace de resynthèse vocale et un cadre de décodage neuronal de la parole.
Résultats de recherche
Résultats du décodage de la parole avec causalité temporelle
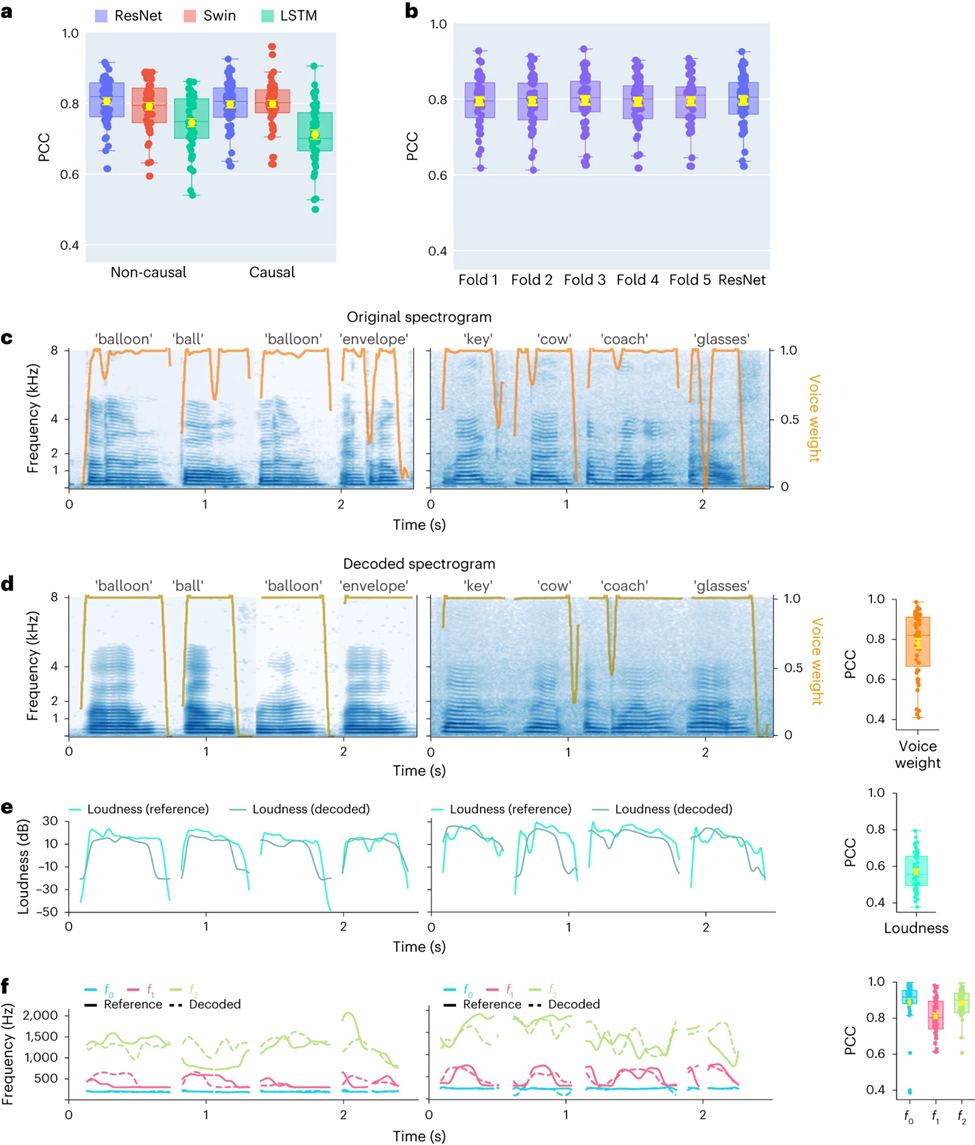
Tout d'abord, les chercheurs ont comparé directement les différences de performances de décodage vocal de différentes architectures de modèles (Convolution (ResNet), Recurrent (LSTM) et Transformer (3D Swin). Il convient de noter que ces modèles peuvent effectuer non -opérations causales ou causales dans le temps
Les résultats montrent que le modèle ResNet a obtenu les meilleurs résultats parmi tous les modèles, atteignant le coefficient de corrélation de Pearson (PCC) le plus élevé parmi 48 participants. Le PCC moyen pour causal et causal est respectivement de 0,806 et 0,797. , suivi du modèle Swin (le PCC moyen pour les cas non causals et causals est respectivement de 0,792 et 0,798) (Figure 2a)
Un résultat similaire a été obtenu par l'évaluation de l'indicateur STOI+ Les résultats La nature causale des modèles de décodage. a des implications significatives pour les applications d'interface cerveau-ordinateur (BCI) : les modèles causals utilisent uniquement les signaux neuronaux passés et actuels pour générer la parole, tandis que les modèles acausaux utilisent également les signaux neuronaux futurs. En utilisant un modèle non causal, cela n'est pas réalisable en temps réel. Par conséquent, les chercheurs se sont concentrés sur la comparaison des performances du même modèle lors de l'exécution d'opérations non causales et causales.
L'étude a révélé que même la version causale du modèle ResNet fonctionnait mieux que la version non causale. , et il n'y a pas de différence significative entre eux. De même, les performances des versions causales et non causales du modèle Swin sont similaires, mais les performances de la version causale du modèle LSTM sont nettement inférieures à celles de la version non causale. version, les chercheurs se concentreront donc sur les modèles ResNet et Swin à l'avenir.
Pour garantir que le cadre proposé dans cet article peut bien se généraliser à des mots invisibles, les chercheurs ont effectué une validation croisée plus stricte au niveau des mots, ce qui signifie que différents les essais du même mot n'apparaîtront pas dans l'ensemble d'entraînement et les tests en même temps Comme le montre la figure 2b, les performances sur les mots invisibles sont comparables à la méthode expérimentale standard de l'article, indiquant que le modèle peut. décoder bien même s'il n'a pas été vu pendant la formation, ce qui est principalement dû à cet article. Le modèle construit effectue un décodage de phonème ou de parole de niveau similaire.
En outre, les chercheurs démontrent les performances du décodeur causal ResNet au niveau d'un seul mot, en montrant les données de deux participants (taux d'échantillonnage à faible densité ECoG). Le spectrogramme décodé conserve avec précision la structure spectrale-temporelle du discours original (Figure 2c, d).
Les chercheurs ont également comparé les paramètres de parole prédits par le décodeur neuronal avec les paramètres codés par l'encodeur de parole (comme valeurs de référence). Les chercheurs ont montré la valeur PCC moyenne (N=48) de plusieurs paramètres de parole clés, y compris le poids sonore (). Utilisé pour distinguer les voyelles et les consonnes), le volume, la hauteur f0, le premier formant f1 et le deuxième formant f2. Une reconstruction précise de ces paramètres vocaux, en particulier la hauteur, le poids du son et les deux premiers formants, est essentielle pour obtenir un décodage et une reconstruction précis de la parole qui imite naturellement la voix du participant.
Les résultats de la recherche montrent que les modèles non causals et causals peuvent obtenir des résultats de décodage raisonnables, ce qui fournit des orientations positives pour les recherches et applications futures.
Étude sur le décodage vocal des signaux neuronaux du cerveau gauche et droit et le taux d'échantillonnage spatial
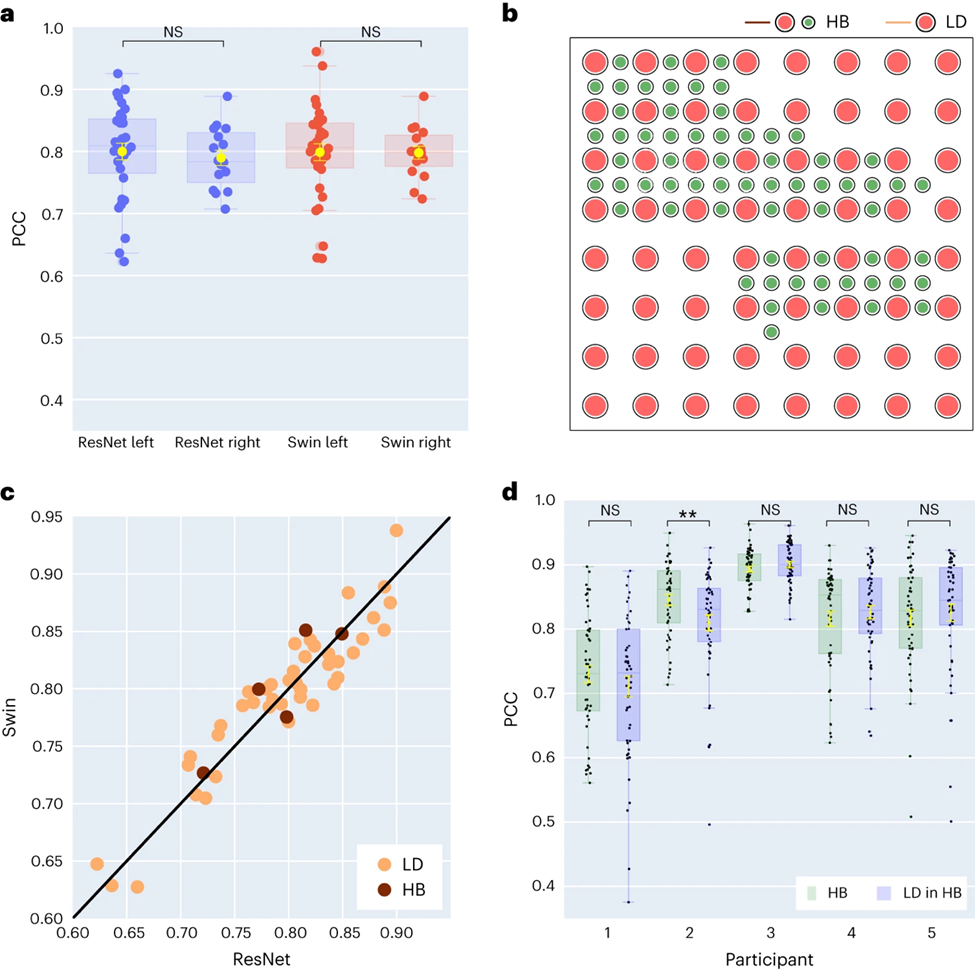
Les chercheurs ont ensuite comparé les résultats du décodage de la parole des hémisphères cérébraux gauche et droit. La plupart des études se concentrent sur l’hémisphère gauche du cerveau, responsable des fonctions de la parole et du langage. Cependant, on sait peu de choses sur la façon dont les informations linguistiques sont décodées à partir de l’hémisphère droit du cerveau. En réponse à cela, les chercheurs ont comparé les performances de décodage des hémisphères cérébraux gauche et droit des participants afin de vérifier la possibilité d'utiliser l'hémisphère cérébral droit pour la récupération de la parole.
Parmi les 48 sujets collectés dans l'étude, les signaux ECoG de 16 sujets ont été collectés à partir du cerveau droit. En comparant les performances des décodeurs ResNet et Swin, les chercheurs ont découvert que l'hémisphère droit peut également décoder la parole de manière stable (la valeur PCC de ResNet est de 0,790, la valeur PCC de Swin est de 0,798), ce qui est moins différent de l'effet de décodage de l'hémisphère gauche (comme illustré à la figure 3a).
Ce constat s’applique également à l’évaluation de STOI+. Cela signifie que pour les patients présentant des lésions de l’hémisphère gauche et une perte de capacité de langage, l’utilisation de signaux neuronaux de l’hémisphère droit pour restaurer le langage peut être une solution réalisable.
Ensuite, les chercheurs ont exploré l’impact de la densité d’échantillonnage des électrodes sur l’effet de décodage de la parole. Les études antérieures utilisaient principalement des grilles d'électrodes de densité plus élevée (0,4 mm), tandis que la densité des grilles d'électrodes couramment utilisées en pratique clinique est plus faible (DL 1 cm).
Cinq participants ont utilisé des grilles d'électrodes de type hybride (HB) (voir Figure 3b), qui sont principalement des échantillonnages à faible densité mais avec des électrodes supplémentaires incorporées. Les quarante-trois participants restants ont été échantillonnés à faible densité. Les performances de décodage de ces échantillons hybrides (HB) sont similaires à celles des échantillons traditionnels à faible densité (LD), mais fonctionnent légèrement mieux sur STOI+.
Les chercheurs ont comparé l'effet de l'utilisation d'électrodes de faible densité uniquement avec l'utilisation de toutes les électrodes mixtes pour le décodage et ont constaté que la différence entre les deux n'était pas significative (voir Figure 3d), ce qui indique que le modèle est capable d'échantillonner le cortex cérébral de différentes densités spatiales. Les informations vocales sont apprises, ce qui implique également que la densité d'échantillonnage couramment utilisée dans la pratique clinique pourrait être suffisante pour les futures applications d'interface cerveau-ordinateur.
Recherche sur la contribution des différentes zones cérébrales du cerveau gauche et droit au décodage de la parole
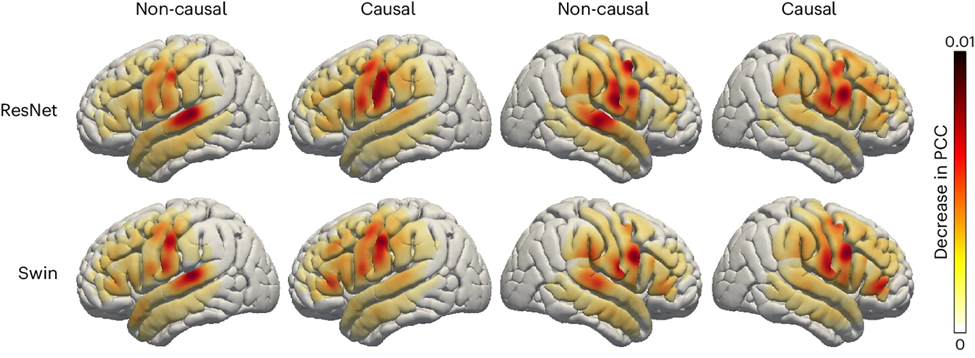
Enfin, les chercheurs ont examiné la contribution des zones du cerveau liées à la parole dans le processus de décodage de la parole, ce qui constitue une référence importante pour l'implantation future de dispositifs de récupération de la parole dans les hémisphères gauche et droit du cerveau. Les chercheurs ont utilisé l’analyse d’occlusion pour évaluer la contribution de différentes régions du cerveau au décodage de la parole.
En bref, si une certaine zone est critique pour le décodage, alors bloquer le signal de l'électrode dans cette zone (c'est-à-dire mettre le signal à zéro) réduira la précision de la parole reconstruite (valeur PCC).
Avec cette méthode, les chercheurs ont mesuré la réduction de la valeur du PCC lorsque chaque zone était obstruée. En comparant les modèles causals et non causals des décodeurs ResNet et Swin, on constate que le cortex auditif contribue davantage au modèle non causal ; cela souligne que dans les applications de décodage de la parole en temps réel, des modèles causals doivent être utilisés car ; décodage de la parole en temps réel, nous ne pouvons pas exploiter les signaux de neurofeedback.
De plus, l'apport du cortex sensorimoteur, notamment de la zone abdominale, est similaire que ce soit dans l'hémisphère droit ou gauche, ce qui laisse penser qu'il pourrait être envisageable d'implanter des prothèses neurales dans l'hémisphère droit.
Conclusions et perspectives inspirantes
Les chercheurs ont développé un nouveau type de synthétiseur vocal différenciable qui peut utiliser un réseau neuronal convolutionnel léger pour coder la parole dans une série de paramètres vocaux interprétables (tels que la hauteur, le volume, les fréquences des formants, etc. ) et resynthétiser la parole via un synthétiseur vocal différentiable.
En mappant les signaux neuronaux sur ces paramètres de parole, les chercheurs ont construit un système de décodage de la parole neuronale hautement interprétable et applicable à des situations de petits volumes de données, et capable de générer une parole à consonance naturelle. Cette méthode est hautement reproductible entre les participants (48 personnes au total) et les chercheurs ont démontré avec succès l’efficacité du décodage causal à l’aide des architectures de convolution et de transformateur (3D Swin), toutes deux supérieures aux architectures récurrentes (LSTM).
Ce cadre peut gérer des densités d'échantillonnage spatial élevées et faibles et peut traiter les signaux EEG des hémisphères gauche et droit, montrant un fort potentiel de décodage de la parole.
La plupart des études précédentes n'ont pas pris en compte la causalité temporelle des opérations de décodage dans les applications d'interface cerveau-ordinateur en temps réel. De nombreux modèles non causals reposent sur des signaux de rétroaction sensorielle auditive. L'analyse des chercheurs a montré que le modèle non causal reposait principalement sur la contribution du gyrus temporal supérieur, alors que le modèle causal l'éliminait essentiellement. Les chercheurs pensent que la polyvalence des modèles non causals dans les applications BCI en temps réel est limitée en raison d’une dépendance excessive aux signaux de rétroaction.
Certaines méthodes tentent d'éviter le feedback lors de l'entraînement, comme par exemple le décodage du discours imaginé du sujet. Malgré cela, la plupart des études adoptent toujours des modèles causals et ne peuvent exclure les effets de rétroaction lors de la formation et de l'inférence. De plus, les réseaux de neurones récurrents largement utilisés dans la littérature sont généralement bidirectionnels, ce qui entraîne des comportements non causals et des retards de prédiction, tandis que nos expériences montrent que les réseaux récurrents formés de manière unidirectionnelle sont les plus performants.
Bien que l'étude n'ait pas testé le décodage en temps réel, les chercheurs ont atteint une latence inférieure à 50 millisecondes dans la synthèse de la parole à partir de signaux neuronaux, avec peu d'impact sur le retard auditif et permettant une production normale de la parole.
L'étude a examiné si une couverture à densité plus élevée pouvait améliorer les performances de décodage. Les chercheurs ont découvert que la couverture de grille à faible et haute densité permettait d'obtenir des performances de décodage élevées (voir Figure 3c). De plus, les chercheurs ont constaté que les performances de décodage utilisant toutes les électrodes n’étaient pas significativement différentes des performances utilisant uniquement des électrodes de faible densité (Figure 3d).
Cela prouve que tant que la couverture péritemporelle est suffisante, même chez les participants à faible densité, le décodeur ECoG proposé par les chercheurs peut extraire les paramètres de parole à partir de signaux neuronaux pour reconstruire la parole. Une autre découverte notable concerne la structure corticale de l’hémisphère droit et la contribution du cortex péritemporal droit au décodage de la parole. Bien que certaines études antérieures aient démontré une contribution possible de l'hémisphère droit au décodage des voyelles et des phrases, nos résultats fournissent la preuve d'une représentation phonologique robuste dans l'hémisphère droit.
Les chercheurs ont également mentionné certaines limites du modèle actuel, telles que le processus de décodage nécessitant des données d'entraînement à la parole associées à des enregistrements ECoG, qui pourraient ne pas être applicables aux patients aphasiques. À l’avenir, les chercheurs espèrent également développer des architectures modèles capables de gérer des données hors grille et de mieux utiliser les données EEG multi-patients et multimodales.
Le premier auteur de cet article : Xupeng Chen, Ran Wang, auteur correspondant : Adeen Flinker.
Soutien financier : National Science Foundation sous la subvention n° IIS-1912286, 2309057 (Y.W., A.F.) et National Institute of Health R01NS109367, R01NS115929, R01DC018805 (A.F.).
Pour plus de discussions sur la causalité dans le décodage neuronal de la parole, vous pouvez vous référer à un autre article des auteurs « Le traitement cortical de rétroaction et de rétroaction distribués prend en charge la production de la parole humaine » : https://www.pnas.org/doi /10.1073 /pnas.2300255120
Source : Communauté d'interface cerveau-ordinateur
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!