Je ne sais pas si Gemini 1.5 Pro utilise cette technologie.
Google a fait un autre grand pas et a lancé le modèle Transformer de nouvelle génération, Infini-Transformer.
Infini-Transformer introduit un moyen efficace de faire évoluer les grands modèles de langage (LLM) basés sur Transformer vers des entrées infiniment longues sans augmenter les besoins en mémoire et en calcul. Grâce à cette technologie, les chercheurs ont réussi à augmenter la longueur du contexte d'un modèle 1B à 1 million ; appliqué au modèle 8B, le modèle peut gérer la tâche de résumé de livre de 500 000 octets. L'architecture Transformer domine le domaine de l'intelligence artificielle générative depuis la publication du document de recherche révolutionnaire « L'attention est tout ce dont vous avez besoin » en 2017. La conception optimisée de Transformer par Google a été relativement fréquente récemment. Il y a quelques jours, ils ont mis à jour l'architecture de Transformer et publié Mixture-of-Depths (MoD), qui a modifié le modèle informatique précédent de Transformer. En quelques jours, Google a publié cette nouvelle étude. Les chercheurs qui se concentrent sur le domaine de l'IA comprennent tous l'importance de la mémoire. Elle est la pierre angulaire de l'intelligence et peut fournir un calcul efficace pour le LLM. Cependant, Transformer et LLM basé sur Transformer présentent une complexité quadratique à la fois en termes d'utilisation de la mémoire et de temps de calcul en raison des caractéristiques inhérentes du mécanisme d'attention, c'est-à-dire le mécanisme d'attention dans Transformer. Par exemple, pour un modèle de 500 B avec une taille de lot de 512 et une longueur de contexte de 2 048, l'empreinte mémoire de l'état valeur-clé d'attention (KV) est de 3 To. Mais en fait, l'architecture Transformer standard doit parfois étendre le LLM à des séquences plus longues (telles que 1 million de jetons), ce qui entraîne une énorme surcharge de mémoire, et à mesure que la longueur du contexte augmente, le coût de déploiement augmente également. Sur cette base, Google a introduit une approche efficace, dont l'élément clé est une nouvelle technologie d'attention appelée Infini-attention. Contrairement aux Transformers traditionnels, qui utilisent l'attention locale pour éliminer les anciens fragments et libérer de l'espace mémoire pour les nouveaux fragments. Infini-attention ajoute une mémoire compressée, qui peut stocker les anciens fragments utilisés dans la mémoire compressée. Lors de la sortie, les informations de contexte actuelles et les informations de la mémoire compressée seront agrégées, afin que le modèle puisse récupérer l'historique complet du contexte. Cette méthode permet à Transformer LLM d'évoluer vers des contextes infiniment longs avec une mémoire limitée et de traiter des entrées extrêmement longues pour les calculs en continu. Les expériences montrent que la méthode surpasse la ligne de base sur les benchmarks de modélisation de langage à contexte long tout en réduisant les paramètres de mémoire de plus de 100 fois. Le modèle atteint une meilleure perplexité lorsqu'il est entraîné avec une longueur de séquence de 100 000. En outre, l’étude a révélé que le modèle 1B a été affiné sur des instances clés de longueur de séquence de 5K, résolvant ainsi le problème de longueur de 1M. Enfin, l'article montre que le modèle 8B avec Infini-attention a obtenu de nouveaux résultats SOTA sur la tâche de résumé de livre d'une longueur de 500 000 après une pré-formation continue et un ajustement précis des tâches. Les contributions de cet article sont résumées comme suit :
- Présente un mécanisme d'attention pratique et puissant Infini-attention - avec une mémoire compressée à long terme et une attention causale locale, qui peut être utilisée efficacement pour modéliser les dépendances contextuelles à long terme et à court terme ;
- Infini-attention apporte des modifications minimes à l'attention des produits ponctuels à l'échelle standard et est conçu pour prendre en charge la pré-formation continue plug-and-play et l'auto-apprentissage en contexte long. Adaptation ;
- Cette méthode permet à Transformer LLM de traiter des entrées extrêmement longues via des flux, en s'adaptant à des contextes infiniment longs avec une mémoire et des ressources informatiques limitées. Lien vers l'article H : https://arxiv.org/pdf/2404.07143.pdf
Titre de la thèse : Ne laisser aucun contexte derrière : Transformateurs de contexte infinis efficaces avec Infini-ATENTINTION
- Introduction à la méthode
Infini-attention permet à Transformer LLM de gérer efficacement des entrées infiniment longues avec une empreinte mémoire et un calcul limités. Comme le montre la figure 1 ci-dessous, Infini-attention intègre une mémoire compressée dans le mécanisme d'attention ordinaire et crée des mécanismes d'attention locale masquée et d'attention linéaire à long terme dans un seul bloc Transformer. Cette modification subtile mais critique de la couche d'attention du Transformer peut étendre la fenêtre contextuelle des LLM existants à des longueurs infinies grâce à un pré-entraînement et un réglage fin continus.
Infini-attention prend tous les états de clé, de valeur et de requête des calculs d'attention standard pour la consolidation et la récupération de la mémoire à long terme, et stocke l'ancien état d'attention KV dans la mémoire compressée. Jetez-les comme le mécanisme d'attention standard.Lors du traitement des séquences suivantes, Infini-attention utilise l'état de requête d'attention pour récupérer les valeurs de la mémoire. Pour calculer la sortie de contexte finale, Infini-attention agrège les valeurs de récupération de mémoire à long terme et le contexte d'attention local.
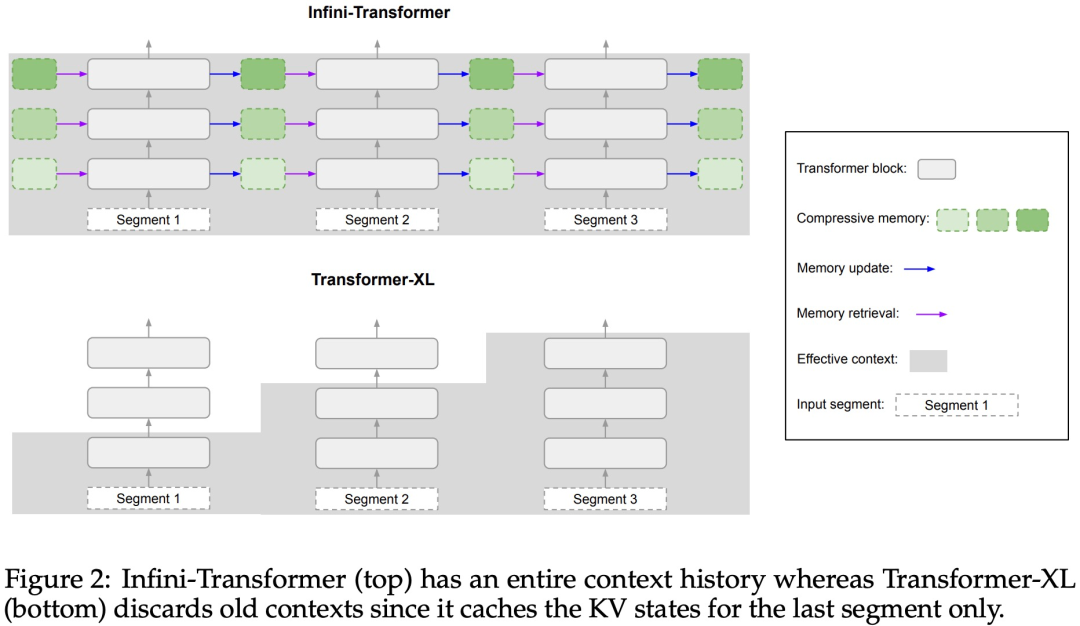
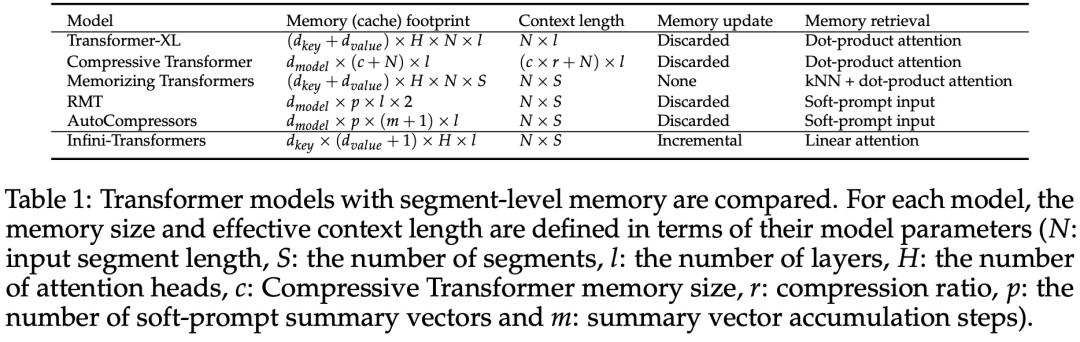
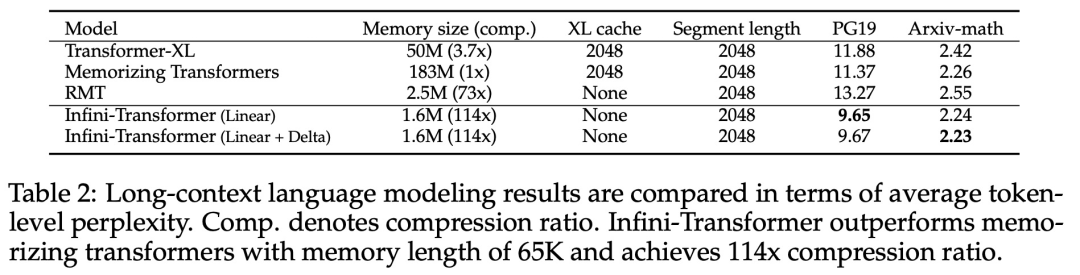
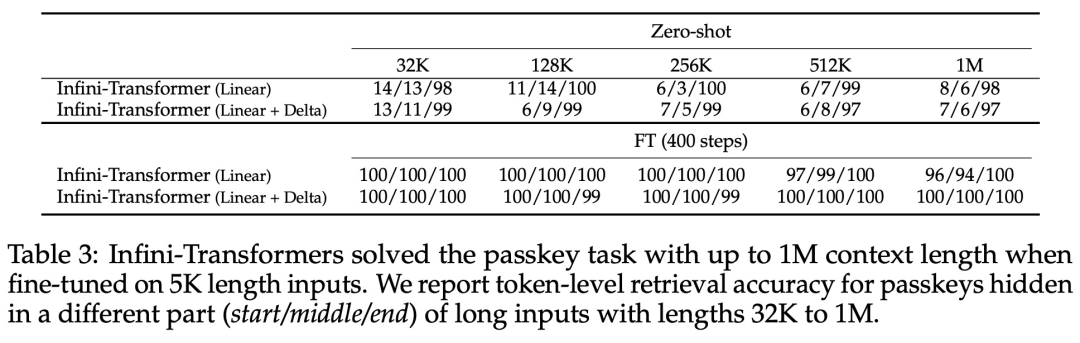
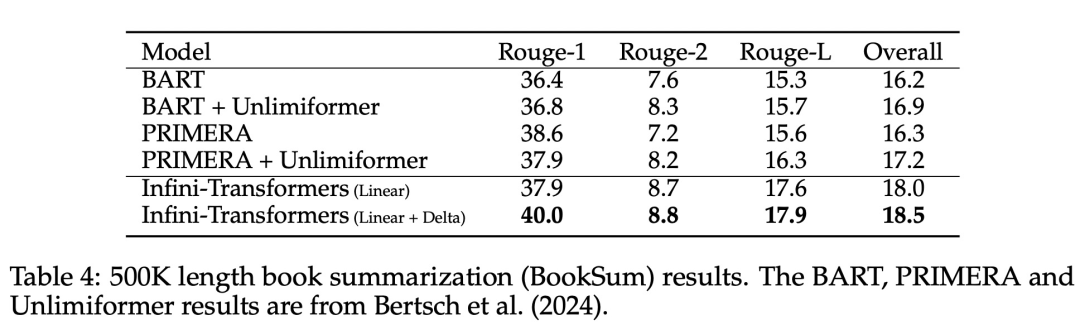
Comme le montre la figure 2 ci-dessous, l'équipe de recherche a comparé Infini-Transformer et Transformer-XL sur la base d'Infini-attention. Semblable à Transformer-XL, Infini-Transformer fonctionne sur une séquence de segments et calcule le contexte d'attention du produit scalaire causal standard dans chaque segment. Par conséquent, le calcul de l’attention du produit scalaire est local dans un certain sens. Cependant, l'attention locale ignore l'état d'attention du segment précédent lors du traitement du segment suivant, mais Infini-Transformer réutilise l'ancien état d'attention KV pour conserver l'intégralité de l'historique du contexte via le stockage compressé. Par conséquent, chaque couche d’attention d’Infini-Transformer a un état compressé global et un état local à granularité fine. Semblable à l'attention multi-têtes (MHA), en plus de l'attention des produits ponctuels, Infini-attention maintient également H mémoires compressées parallèles pour chaque couche d'attention (H est le nombre de têtes d'attention). Le tableau 1 ci-dessous répertorie l'empreinte de la mémoire contextuelle et la longueur effective du contexte définies par plusieurs modèles en fonction des paramètres du modèle et de la longueur du segment d'entrée. Infini-Transformer prend en charge des fenêtres contextuelles infinies avec une empreinte mémoire limitée. L'étude a évalué le modèle Infini-Transformer sur la modélisation de langage à contexte long, la récupération de blocs de contexte clés de 1 million de longueur et les tâches de résumé de livre de 500 000 longueurs, qui ont une séquence d'entrée longue extrêmement élevée. Pour la modélisation du langage, les chercheurs ont choisi de former le modèle à partir de zéro, tandis que pour les tâches clés et de résumé du livre, les chercheurs ont utilisé une pré-formation continue de LLM pour prouver l'adaptabilité plug-and-play d'Infini-attention dans un contexte long. Modélisation du langage à contexte long. Les résultats du tableau 2 montrent qu'Infini-Transformer surpasse les références de Transformer-XL et de Memorizing Transformers et stocke 114 fois moins de paramètres par rapport au modèle Memorizing Transformer. Mission clé. Le tableau 3 montre l'Infini-Transformer affiné sur une entrée de longueur de 5K résolvant la tâche clé jusqu'à une longueur de contexte de 1M. Les jetons d'entrée dans l'expérience variaient de 32 000 à 1 M. Pour chaque sous-ensemble de test, les chercheurs ont contrôlé la position de la clé afin qu'elle soit située près du début, du milieu ou de la fin de la séquence d'entrée. Les expériences rapportent une précision de tir zéro et une précision de réglage fin. Après 400 étapes de réglage fin sur une entrée de longueur 5K, Infini-Transformer résout des tâches jusqu'à 1M de longueur de contexte. Tâches récapitulatives. Le tableau 4 compare Infini-Transformer avec un modèle d'encodeur-décodeur conçu spécifiquement pour la tâche de récapitulation. Les résultats montrent qu'Infini-Transformer surpasse les meilleurs résultats précédents et atteint un nouveau SOTA sur BookSum en traitant l'intégralité du texte du livre. Les chercheurs ont également représenté le score Rouge global de la répartition de validation des données BookSum dans la figure 4. La tendance des polylignes montre que les Infini-Transformers améliorent les mesures de performances récapitulatives à mesure que la longueur d'entrée augmente.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!