
Maison >Périphériques technologiques >IA >Série de prédiction de trajectoire | De quoi parle la version évoluée de HiVT QCNet ?
Série de prédiction de trajectoire | De quoi parle la version évoluée de HiVT QCNet ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-12 18:28:21864parcourir
La version évoluée de HiVT (vous pouvez lire cet article directement sans lire HiVT au préalable), avec des performances et une efficacité grandement améliorées.
L'article est également facile à lire.
[Série de prédiction de trajectoire] [Notes] HiVT : Transformateur vectoriel hiérarchique pour la prédiction de mouvement multi-agents - Zhihu (zhihu.com)
Lien original :
https://openaccess.thecvf.com/content/CVPR2023/ papers /Zhou_Query-Centric_Trajectory_Prediction_CVPR_2023_paper.pdf
Abstract
Il y a un problème dans le modèle où l'agent est utilisé comme centre de prédiction. Lorsque la fenêtre se déplace, elle doit être répétée plusieurs fois pour se normaliser avec le centre de l'agent et. puis répétez le processus d'encodage. Il n'est pas adapté à une utilisation à bord. Par conséquent, nous utilisons un cadre centré sur les requêtes pour le codage de scènes, qui peut réutiliser les résultats calculés et ne repose pas sur le système de coordonnées temporelles global. Dans le même temps, étant donné que différents agents partagent des caractéristiques de scène, le processus de décodage de la trajectoire de l'agent peut être traité de manière plus parallèle.
La scène est encodée de manière complexe et la méthode de décodage actuelle est encore difficile à capturer les informations de mode, en particulier pour les prédictions à long terme. Afin de résoudre ce problème, nous utilisons d'abord la requête sans ancre pour générer une proposition de trajectoire (une méthode d'extraction de caractéristiques étape par étape), afin que le modèle puisse mieux utiliser les caractéristiques de la scène à différents moments. Ensuite, il y a le module d'ajustement, qui utilise la proposition obtenue à l'étape précédente pour optimiser la trajectoire (basée sur une ancre dynamique). Grâce à ces ancres de haute qualité, notre décodeur basé sur des requêtes peut mieux gérer les caractéristiques du mode.
Classé avec succès. Cette conception implémente également des pipelines de codage de fonctionnalités de scénario et de décodage multi-agents parallèles.
Introduction
Le document de prédiction de trajectoire actuel présente les problèmes suivants :
- Pour une variété d'informations sur les scènes hétérogènes, l'efficacité du traitement est faible. Dans les tâches de conduite sans pilote, les données sont transmises au modèle image par image, notamment des cartes vectorisées de haute précision et des trajectoires historiques des agents environnants. La récente méthode d’attention factorisée (attention séparée dans l’espace et dans le temps) a élevé le traitement de ces informations à un nouveau niveau. Mais cela nécessite une attention particulière pour chaque élément de la scène. Si la scène est très complexe, le coût reste très élevé. À mesure que le temps de prévision augmente, l'
- incertitude de la prévision explose également. Par exemple, une voiture à une intersection peut aller tout droit ou tourner. Afin d'éviter de rater des possibilités potentielles, le modèle doit obtenir la distribution de plusieurs modes au lieu de simplement prédire le mode ayant la fréquence la plus élevée. Mais il n’existe qu’un seul gt, et il est impossible de réaliser un meilleur apprentissage sur de multiples possibilités. Certains articles proposent la méthode d'utilisation de plusieurs ancres portatives pour la supervision. Cet effet dépend entièrement de la qualité des ancres. Cette approche est très mauvaise lorsque l'ancre ne peut pas couvrir avec précision le GT. Il existe également d'autres approches pour prédire directement plusieurs modes, en ignorant les problèmes d'effondrement des modes et d'instabilité de la formation.
réutiliser ces fonctionnalités. Cependant, la méthode centrée sur l'agent doit être transférée vers le système de coordonnées de l'agent, elle doit donc ré-encoder la scène. Afin de résoudre ce problème, nous utilisons la méthode query-centric : les éléments de la scène extraient des caractéristiques dans leur propre système de coordonnées spatio-temporelles, quel que soit le système de coordonnées global (peu importe où se trouve l'ego). (Des cartes de haute précision peuvent être utilisées car les éléments cartographiques ont des identifiants à long terme. Les cartes de non-haute précision devraient être difficiles à utiliser. Les éléments cartographiques doivent être suivis dans les cadres avant et arrière.)
combinaison de méthodes sans ancre et basées sur ancreexploite pleinement les avantages des deux méthodes pour réaliser des prédictions multimodes et à long terme.
Cette approche est la première à explorer la continuité de la prédiction de trajectoire pour réaliser une inférence à grande vitesse. Parallèlement, la partie décodeur prend également en compte les tâches de prédiction multimodes et à long terme.Approche
Entrée et sortie

Dans le même temps, le module de prédiction peut également obtenir M polygones à partir de la carte de haute précision. Chaque polygone possède plusieurs points et informations sémantiques (passage pour piétons, voie, etc.).
Le module de prédiction utilise l'état de l'agent ci-dessus et les informations cartographiques à T moments pour donner K trajectoires prédites d'une longueur totale de T', ainsi que sa distribution de probabilité.
Encodage du contexte de scène centré sur les requêtes
La première étape est naturellement l'encodage de la scène. L'attention factorisée actuellement populaire (attention dans les dimensions temporelles et spatiales respectivement) se fait de cette manière. Plus précisément, il y a trois étapes :
- attention à la dimension temporelle, complexité temporelle O(A), multiplication matricielle de la dimension temporelle de chaque agent.
- attention croisée de l'agent et de la carte, complexité temporelle O(ATM), à chaque instant, multiplication matricielle des éléments de l'agent et de la carte
- attention entre agent et agent, complexité temporelle O(T), à chaque instant, l'agent et la matrice de l'agent sont multipliées
Par rapport à la méthode précédente consistant à compresser la caractéristique dans la dimension temporelle au moment actuel, puis à interagir entre l'agent et l'agent, l'agent et la carte, cette méthode est pour chaque instant. dans le passé. Pour interagir, vous pouvez obtenir plus d'informations, comme l'évolution de l'interaction entre l'agent et la carte à chaque instant.
Mais l'inconvénient est que la complexité cubique deviendra très grande à mesure que la scène devient plus complexe et que le nombre d'éléments augmente. Notre objectif est de faire bon usage de cette attention factorisée sans laisser la complexité temporelle exploser si facilement.
Une façon simple de réfléchir est d'utiliser les résultats de l'image précédente, car dans la dimension temporelle, il y a en fait des images T-1 qui sont complètement répétées. Mais comme nous devons faire pivoter et traduire ces caractéristiques vers la position et l'orientation du frame actuel de l'agent, nous ne pouvons pas simplement utiliser les résultats obtenus lors de l'opération frame précédente.
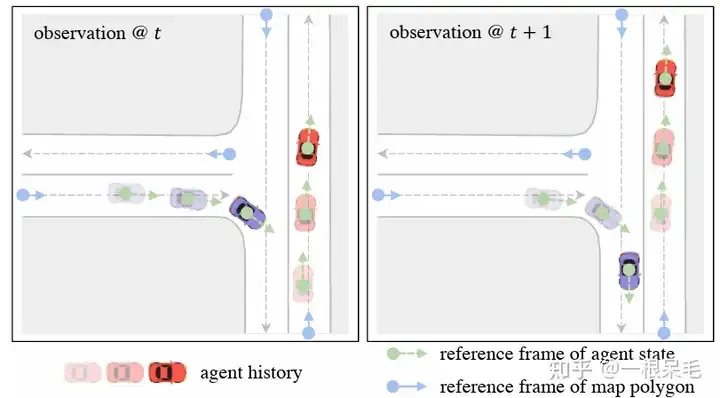
Afin de résoudre le problème du système de coordonnées, une approche centrée sur les requêtes est adoptée pour apprendre les caractéristiques des éléments de la scène sans s'appuyer sur leurs coordonnées globales. Cette approche établit un système de coordonnées spatio-temporelles local pour chaque élément de la scène et extrait les caractéristiques au sein de ce système de coordonnées. Même si l'ego va ailleurs, les caractéristiques extraites localement resteront inchangées. Ce système de coordonnées spatio-temporelles locales a naturellement une position d'origine et une direction. Ces informations de position sont utilisées comme clé, et les caractéristiques extraites sont utilisées comme valeur pour faciliter les opérations d'attention ultérieures. L'ensemble de l'approche est divisé en les étapes suivantes :
Système de coordonnées spatio-temporelles local
Pour la caractéristique de l'agent i à l'instant t, sélectionnez la position et l'orientation à cet instant comme système de référence. Pour les éléments cartographiques, le point de départ de cet élément est utilisé comme cadre de référence. Une telle méthode de sélection du système de référence peut conserver les caractéristiques extraites inchangées après le déplacement de l'ego.
Incorporation d'éléments de scène
Pour d'autres caractéristiques vectorielles au sein de chaque élément, les représentations de coordonnées polaires sont obtenues dans le système de référence ci-dessus. Ils sont ensuite convertis en caractéristiques de Fourier pour obtenir des signaux haute fréquence. Après avoir concassé les fonctionnalités sémantiques, MLP obtient les fonctionnalités. Pour les éléments cartographiques, afin de garantir que l'ordre des points internes n'est pas pertinent, une attention est d'abord effectuée puis une mise en commun est effectuée. Enfin, les caractéristiques de l'agent sont [A, T, D] et les caractéristiques de la carte sont [M, D]. Ce n'est qu'en la gardant cohérente que la multiplication matricielle de l'attention peut être facilitée. Les fonctionnalités extraites de cette manière peuvent rendre l’ego utilisable n’importe où.
Incrustation de Fourier : créez une intégration distribuée normale, correspondant aux poids de différentes fréquences, multipliez la somme d'entrée par 2Π, et enfin prenez cos et sin comme caractéristiques. Une compréhension intuitive devrait consister à traiter l'entrée comme un signal et à décoder le signal en plusieurs signaux de base (signaux de plusieurs fréquences). Cela permet de mieux capturer les signaux haute fréquence. Les signaux haute fréquence sont très importants pour la précision des résultats. Les méthodes générales peuvent facilement perdre des signaux haute fréquence fins. Il convient de noter qu’il n’est pas recommandé d’utiliser des données bruitées car elles capteraient par erreur le mauvais signal haute fréquence. (Cela ressemble un peu à un surajustement, pas trop général mais pas trop précis)

Il convient de noter que les caractéristiques obtenues grâce à la méthode ci-dessus ont une invariance spatio-temporelle, c'est-à-dire que peu importe où va l'ego à tout moment, les caractéristiques ci-dessus restent inchangées car il n'y a pas de translation ou de rotation basée sur les informations de position actuelle. Puisqu'il n'y a qu'une nouvelle trame de données par rapport à la trame précédente, il n'est pas nécessaire de calculer les caractéristiques du moment précédent, donc la complexité de calcul totale est divisée par T.

Décodage de trajectoire basé sur des requêtes
Semblable à la méthode de requête sans ancre de DETR consistant à prêter attention à certaines valeurs clés, cela entraînera un entraînement instable, des problèmes d'effondrement de mode et la prédiction à long terme est également difficile. Peu fiable car l’incertitude explosera plus tard. Par conséquent, ce modèle utilise d'abord une méthode de requête approximative sans ancre, puis affine la méthode de base d'ancrage pour cette sortie.
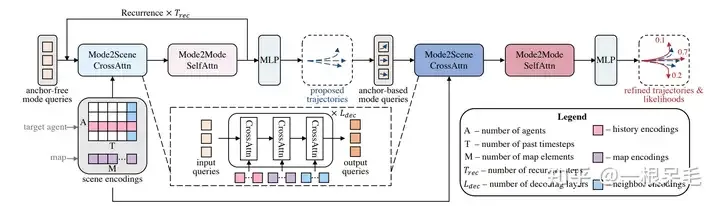 L'ensemble de la structure du réseau
L'ensemble de la structure du réseau
Mode2Scene et Mode2Mode Attention
Mode2Scene adopte la structure DETR dans les deux étapes : la requête est K modes de trajectoire (l'étape de proposition grossière est directement générée de manière aléatoire et l'étape de raffinement est obtenue à partir de la proposition étapes en entrée), puis effectuez plusieurs attentions croisées sur les fonctionnalités de la scène (historique de l'agent, carte, agents environnants).
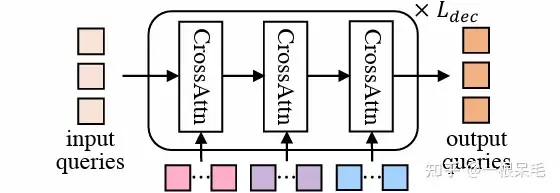 Structure DETR
Structure DETR
Mode2Mode effectue une attention personnelle parmi les modes K, en essayant de réaliser la diversité entre les modes, afin de ne pas les rassembler tous.
Cadres de référence des requêtes de mode
Afin de prédire les trajectoires de plusieurs agents en parallèle, l'encodage de la scène est partagé par plusieurs agents. Étant donné que les fonctionnalités de la scène sont toutes des fonctionnalités relatives à elles-mêmes, vous devez toujours passer à la perspective de l'agent si vous souhaitez les utiliser. Pour la requête de mode, les informations de localisation et d'orientation de l'agent seront ajoutées. Semblable à l'opération précédente de codage de la position relative, les informations de position relative de l'élément de scène et de l'agent seront également intégrées en tant que clé et valeur. (Intuitivement parlant, il s'agit d'une attention pondérée de chaque mode de l'agent sur l'utilisation des informations à proximité)
Proposition de trajectoire sans ancre
La première fois est la méthode sans ancre, utilisant une requête apprenable pour créer des qualité La proposition de trajectoire générera un total de K propositions. Étant donné que l'attention croisée est utilisée pour extraire des caractéristiques des informations de scène, des ancres relativement petites et efficaces peuvent être générées efficacement pour être utilisées dans le deuxième affinement. L’attention personnelle rend chaque proposition globalement plus diversifiée.

Raffinement de la trajectoire basé sur l'ancre
Bien que la méthode sans ancre soit relativement simple, elle présente également le problème d'un entraînement instable et d'un éventuel effondrement du mode. Dans le même temps, le mode généré aléatoirement doit également être capable de fonctionner correctement pour différents agents dans l'ensemble de la scène. Cela est relativement difficile et il est facile de générer des propositions de trajectoire qui ne correspondent pas à la cinématique ou au trafic. Nous avons donc pensé à faire une autre correction basée sur l'ancrage. Un décalage est prédit sur la base de la proposition (ajoutée à la proposition originale pour obtenir la trajectoire révisée), et la probabilité de chaque nouvelle trajectoire est prédite.
Ce module utilise également la forme de DETR. La requête de chaque mode est extraite en utilisant la proposition de l'étape précédente Plus précisément, un petit GRU est utilisé pour intégrer chaque ancre (pas en avant), et il est utilisé jusqu'à la fin. Une fonctionnalité sert à un moment de requête. Ces requêtes basées sur des ancres peuvent fournir certaines informations spatiales, facilitant ainsi la capture d'informations utiles pendant l'attention.
Objectifs de formation
Les mêmes que HiVT (se référer à l'analyse de HiVT), en utilisant la distribution de Laplace. Pour parler franchement, chaque instant dans chaque mode est modélisé comme une distribution de Laplace (se référer à la distribution gaussienne générale, où moyenne et var représentent la position de ce point et son incertitude). Et les moments sont considérés comme indépendants (directement multipliés). Π représente la probabilité du mode correspondant.
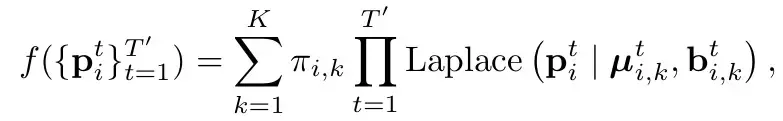
La perte se compose de 3 parties
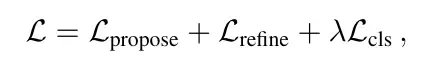
est principalement divisée en deux parties : perte de classification et perte de régression.
La perte de classification fait référence à la perte de probabilité prédite. Ce qu'il convient de noter ici, c'est qu'il est nécessaire d'interrompre le retour du gradient, et le gradient causé par la probabilité ne peut pas être transmis à la prédiction des coordonnées (c'est-à-dire en supposant que la position prévue de chaque mode est dans des conditions raisonnables). L'étiquette la plus proche de gt est 1 et les autres sont 0.
Il y a deux pertes de régression, l'une est la perte de la proposition de première étape et l'autre est la perte du raffinement de la deuxième étape. Une approche gagnant-gagnant est adoptée, c'est-à-dire que seule la perte du mode le plus proche de gt est calculée et les pertes de régression des deux étapes sont calculées. Pour la stabilité de la formation, le retour du gradient est également interrompu dans les deux étapes, de sorte que l'apprentissage des propositions n'apprenne que les propositions et l'affinement n'apprenne qu'à affiner.
ExpériencesArgoverse2 basic SOTA (* indique que la technique d'ensemble est utilisée)
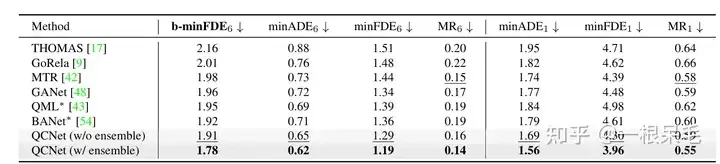 La différence entre b-minFDE et minFDE est qu'il est multiplié par un coefficient supplémentaire lié à sa probabilité. la cible veut que le FDE soit le plus petit. Plus la probabilité de cette trajectoire est élevée, mieux c'est.
La différence entre b-minFDE et minFDE est qu'il est multiplié par un coefficient supplémentaire lié à sa probabilité. la cible veut que le FDE soit le plus petit. Plus la probabilité de cette trajectoire est élevée, mieux c'est.
Concernant la technique d'ensemble, je trouve que c'est un peu tricher : vous pouvez vous référer à l'introduction dans BANet, qui est brièvement présentée ci-dessous.
La dernière étape de génération de la trajectoire consiste à connecter plusieurs sous-modèles (décodeur) avec la même structure en même temps, ce qui donnera plusieurs ensembles de prédictions. Par exemple, il y a 7 sous-modèles, chacun avec 6 prédictions, 42 au total. . Utilisez ensuite kmeans pour effectuer le clustering (en utilisant le dernier point de coordonnées comme norme de clustering). L'objectif est de 6 groupes, 7 éléments dans chaque groupe, puis effectuez une moyenne pondérée dans chaque groupe pour obtenir une nouvelle trajectoire.
La méthode de pondération est la suivante. C'est le b-minFDE de la trajectoire actuelle et gt, et c est la probabilité de la trajectoire actuelle. Le poids est calculé dans chaque groupe, puis les coordonnées de la trajectoire sont pondérées et additionnées. obtenir une nouvelle trajectoire. (Cela semble un peu délicat, car c est en fait la probabilité de cette trajectoire dans la sortie du sous-modèle, ce qui est un peu incompatible avec les attentes lorsqu'elle est utilisée en clustering)
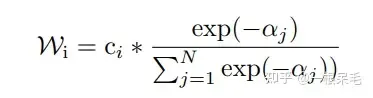 Et la probabilité de la nouvelle trajectoire après cette opération est également difficile à calculer avec précision, la méthode ci-dessus ne peut pas être utilisée, sinon la somme totale des probabilités ne sera pas nécessairement 1. Il semble que nous ne puissions calculer les probabilités que dans des grappes de poids égaux.
Et la probabilité de la nouvelle trajectoire après cette opération est également difficile à calculer avec précision, la méthode ci-dessus ne peut pas être utilisée, sinon la somme totale des probabilités ne sera pas nécessairement 1. Il semble que nous ne puissions calculer les probabilités que dans des grappes de poids égaux.
Argoverse1 est également loin devant
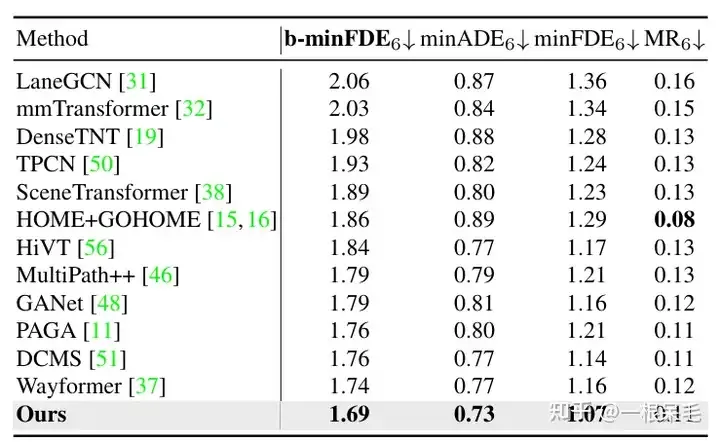 Recherche sur l'encodage de scène : si les résultats d'encodage de scène précédents sont réutilisés, le temps d'inférence peut être considérablement réduit. Le nombre d'interactions d'attention factorisées entre l'agent et les informations de la scène augmente, et l'effet de prédiction deviendra également meilleur, mais la latence augmente également fortement, ce qui doit être pris en compte.
Recherche sur l'encodage de scène : si les résultats d'encodage de scène précédents sont réutilisés, le temps d'inférence peut être considérablement réduit. Le nombre d'interactions d'attention factorisées entre l'agent et les informations de la scène augmente, et l'effet de prédiction deviendra également meilleur, mais la latence augmente également fortement, ce qui doit être pris en compte.
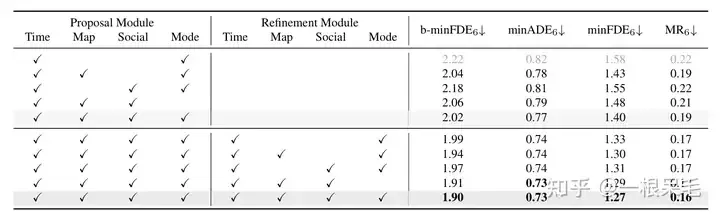
 Recherche sur diverses opérations : Prouver l'importance du raffinement et l'importance de l'attention factorisée dans diverses interactions, les deux sont indispensables.
Recherche sur diverses opérations : Prouver l'importance du raffinement et l'importance de l'attention factorisée dans diverses interactions, les deux sont indispensables.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Accéder aux types de données
- Qu'est-ce qui est utilisé pour représenter les entités dans la base de données Access
- Quel logiciel est l'accès Dolby ?
- Discutez de l'état actuel et des tendances de développement de la technologie de prédiction de trajectoire de conduite autonome
- Quelle est la méthode pour écrire du code en Java pour tracer des trajectoires sur la carte via l'API Baidu Map ?