La combinaison de grands modèles et de bases de données d'IA est devenue une formule gagnante pour réduire les coûts et augmenter l'efficacité des grands modèles et rendre le Big Data véritablement intelligent.

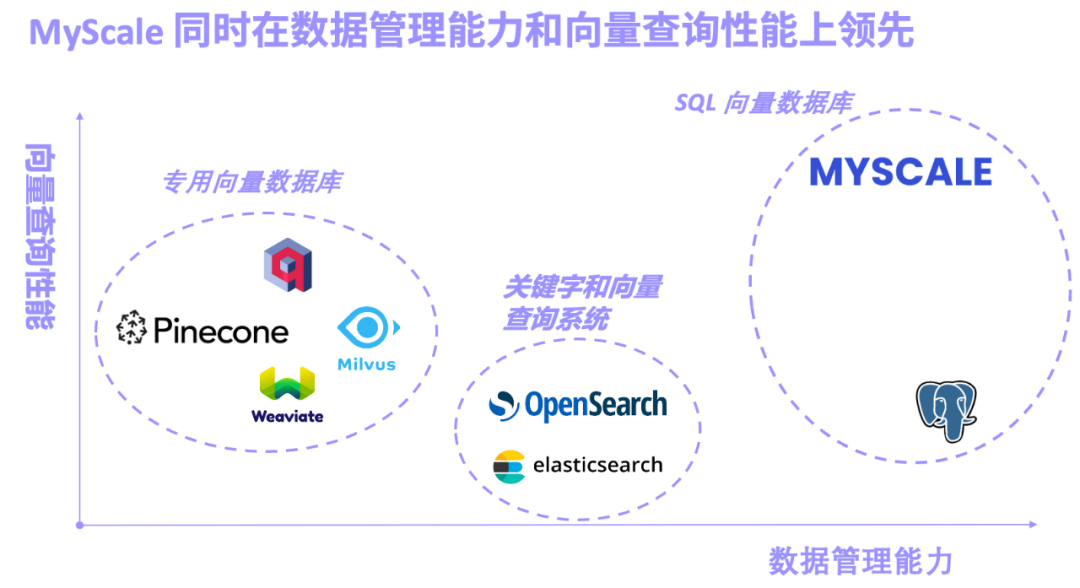
La vague des Grands Modèles (LLM) déferle depuis plus d'un an, notamment les modèles représentés par GPT-4, Gemini-1.5, Claude-3, etc. Sur la piste LLM, certaines recherches se concentrent sur l'augmentation des paramètres du modèle, et certaines sont folles de multimodalité... Parmi elles, la capacité de LLM à traiter la longueur du contexte est devenue un indicateur important pour évaluer les modèles. Un contexte plus fort signifie que le modèle a. performances de récupération plus élevées. Par exemple, la capacité de certains modèles à traiter jusqu'à 1 million de tokens en une seule fois a amené de nombreux chercheurs à se demander si la méthode RAG (Retrieval-Augmented Generation) est toujours nécessaire ? Certaines personnes pensent que RAG sera tué par le modèle de contexte long, mais ce point de vue a été réfuté par de nombreux chercheurs et architectes. Ils pensent que d’une part, les structures de données sont complexes, changent régulièrement et que de nombreuses données ont des dimensions temporelles importantes, qui peuvent être trop complexes pour le LLM. D’un autre côté, il n’est pas réaliste de placer toutes les données hétérogènes massives des entreprises et des industries dans une fenêtre contextuelle. La combinaison de grands modèles et de bases de données d'IA injecte des informations professionnelles, précises et en temps réel dans le système d'IA générative, réduisant considérablement les illusions et améliorant la praticité du système. Dans le même temps, la méthode LLM centrée sur les données peut également tirer parti des capacités massives de gestion des données et de requêtes des bases de données d'IA pour réduire considérablement le coût de la formation et du réglage fin des grands modèles, et prendre en charge le réglage de petits échantillons dans différents scénarios du système. En résumé, La combinaison de grands modèles et de bases de données d'IA réduit non seulement les coûts et augmente l'efficacité des grands modèles, mais rend également le Big Data vraiment intelligent. Après plusieurs années de développement et d'itération, MyScaleDB est enfin open source RAG permet à LLM d'extraire avec précision des informations à partir de bases de connaissances à grande échelle et de générer une réponse en temps réel, professionnelle et perspicace. Parallèlement à cela, la base de données vectorielles, fonction principale du système RAG, s'est également développée rapidement. Selon le concept de conception de la base de données vectorielles, nous pouvons la diviser grossièrement en trois catégories : base de données vectorielles dédiée, système de récupération combinant des mots-clés et des vecteurs. et base de données vectorielles SQL.
- Les bases de données vectorielles spécialisées représentées par Pinecone/Weaviate/Milvus sont conçues et construites pour la récupération de vecteurs dès le début. Les performances de récupération de vecteurs sont excellentes, mais la fonction générale de gestion des données est faible.
- Les systèmes de récupération de mots-clés et de vecteurs représentés par Elasticsearch/OpenSearch sont largement utilisés en production en raison de leurs fonctions complètes de récupération de mots-clés. Cependant, ils occupent beaucoup de ressources système et la précision des requêtes conjointes et les performances des mots-clés et des vecteurs ne sont pas satisfaisantes. . Les gens obtiennent ce qu’ils veulent.
- Les bases de données vectorielles SQL représentées par pgvector (plug-in de recherche vectorielle pour PostgreSQL) et la base de données MyScale AI sont basées sur SQL et disposent de puissantes fonctions de gestion de données. Cependant, en raison des inconvénients du stockage de lignes PostgreSQL et des limitations des algorithmes vectoriels, pgvector a une faible précision dans les requêtes vectorielles complexes.
La base de données MyScale AI (MyScaleDB) est construite sur la base d'une base de données de stockage de colonnes SQL hautes performances, d'un algorithme d'index vectoriel hautes performances et haute densité de données auto-développé et d'une requête conjointe de SQL et de vecteurs. pour la récupération et le stockage Le moteur a fait l'objet d'une recherche, d'un développement et d'une optimisation approfondis. Il s'agit du premier produit de base de données vectorielle SQL au monde dont les performances globales et la rentabilité dépassent largement celles d'une base de données vectorielle dédiée.
Grâce au perfectionnement à long terme de la base de données SQL dans des scénarios de données structurées massives, MyScaleDB prend en charge à la fois les données vectorielles et structurées massives
, y compris le stockage efficace et le stockage de plusieurs types de données tels que les chaînes, JSON, l'espace et des séries chronologiques, et lancera prochainement de puissantes fonctions de recherche par table inversée et par mot-clé pour améliorer encore la précision du système RAG et remplacer des systèmes tels qu'Elasticsearch.
Après près de 6 ans de développement et plusieurs itérations de versions, MyScaleDB est récemment devenu open source. Tous les développeurs et utilisateurs d'entreprise sont invités à jouer sur GitHub et à ouvrir une nouvelle façon d'utiliser SQL pour créer des applications d'IA de niveau production ! Adresse du projet : https://github.com/myscale/myscaledbEntièrement compatible avec SQL, améliorant la précision et réduisant les coûtsAvec l'aide de capacités complètes de gestion des données SQL, puissante et efficace Avec des capacités de stockage et de requête de données structurées, vectorielles et hétérogènes, MyScaleDB devrait devenir la première Base de données IA véritablement orientée vers les grands modèles et le big data. Compatibilité native du SQL et des vecteursDepuis la naissance du SQL il y a un demi-siècle, malgré les vagues du NoSQL, du big data, etc., la base de données SQL en constante évolution occupe toujours la majorité du marché de la gestion des données Share, voire des systèmes de récupération et de big data comme Elasticsearch et Spark ont successivement supporté les interfaces SQL. Bien que les bases de données vectorielles dédiées aient été optimisées et le système conçu pour les vecteurs, leurs interfaces de requête manquent généralement de standardisation et ne disposent pas de langages de requête avancés. Cela se traduit par de faibles capacités de généralisation de l’interface. Par exemple, l’interface de requête de Pinecone n’inclut même pas la spécification des champs à récupérer, sans parler des fonctions courantes de base de données telles que la pagination et l’agrégation. La faible capacité de généralisation de l'interface fait qu'elle change fréquemment, ce qui augmente le coût d'apprentissage. L'équipe MyScale estime que le système SQL et vectoriel systématiquement optimisé peut maintenir une prise en charge complète de SQL tout en garantissant des performances élevées en matière de récupération de vecteurs, et les résultats de leur évaluation open source l'ont pleinement démontré.
Dans les scénarios d'application d'IA complexes réels, la combinaison de SQL et de vecteurs peut considérablement augmenter la flexibilité de la modélisation des données et simplifier le processus de développement. Par exemple, dans le projet Science Navigator coopérant entre l'équipe MyScale et l'Institut d'intelligence scientifique de Pékin, MyScaleDB est utilisé pour récupérer des données massives de la littérature scientifique et effectuer des réponses intelligentes aux questions. Il existe plus de 10 structures de tables SQL principales, dont beaucoup établissent. vecteurs.Et index de table inversé, et utilisez la clé primaire et la clé étrangère pour faire l'association. Dans les requêtes réelles, le système impliquera également des requêtes conjointes de données structurées, vectorielles et par mots-clés, ainsi que des requêtes associées sur plusieurs tables. Ces modélisations et corrélations sont difficiles à réaliser dans une base de données vectorielles dédiée, ce qui entraînera également une itération lente du système final, des requêtes inefficaces et une maintenance difficile.
Diagramme schématique de la structure de la table principale de NScience Navigator (les colonnes de corps en gras établissent des index vectoriels ou des index inversés) prend en charge les requêtes structurées, vectorielles et par mots-clés et autres requêtes conjointes de données Dans le système RAG actuel, le la précision et l’effet de la récupération sont les principaux goulots d’étranglement limitant sa mise en œuvre. Cela nécessite que la base de données d'IA prenne en charge efficacement les requêtes conjointes de données structurées, vectorielles et par mots clés afin d'améliorer considérablement la précision de la récupération.
Par exemple, dans un scénario financier, les utilisateurs doivent interroger la bibliothèque de documents « Quel est le chiffre d'affaires des différentes activités mondiales d'une certaine entreprise en 2023 ? », « Une certaine entreprise », « 2023 » et d'autres les méta-informations ne peuvent pas être correctement capturées par les vecteurs et peuvent même ne pas être directement reflétées dans le paragraphe correspondant. Effectuer une récupération vectorielle directement sur l’ensemble de la base de données obtiendra une grande quantité d’informations sur le bruit et réduira la précision finale du système. D'un autre côté, le nom de l'entreprise, l'année, etc. peuvent généralement être obtenus comme méta-informations du document. Nous pouvons utiliser WHERE year=2023 AND company ILIKE "%%" comme condition de filtre de la requête vectorielle pour localiser avec précision Des informations pertinentes sont obtenues, ce qui améliore considérablement la fiabilité du système. Dans les domaines de la finance, de la fabrication, de la recherche scientifique et d'autres scénarios, l'équipe MyScale a observé la puissance de la modélisation de données hétérogènes et des requêtes associées. Dans de nombreux scénarios, la précision s'est même améliorée de
60 % à Bien que les produits de bases de données traditionnels aient progressivement pris conscience de l'importance des requêtes vectorielles à l'ère de l'IA et aient commencé à ajouter des capacités vectorielles à la base de données, il existe encore des problèmes importants avec la précision de leurs requêtes conjointes. Par exemple, dans le scénario de filtrage des requêtes, lorsque le taux de filtrage est de 0,1, le QPS d'Elasticsearch chutera à environ 5 seulement, tandis que la précision de récupération de PostgresSQL (à l'aide du plug-in pgvector) n'est que d'environ 50 % lorsque le filtrage Le rapport est de 0,01, ce qui rend la requête instable. Le rapport Précision/performance restreint considérablement ses scénarios d'application. Et MyScale n'utilise que 36 % du coût de pgvector et 12 % du coût d'ElasticSearch, et peut réaliser des requêtes hautes performances et haute précision dans divers scénarios avec différents ratios de filtrage. 场 Dans différentes proportions de filtration, myscale utilise de faibles coûts pour obtenir des requêtes de haute précision et hautes performances
L'équilibre entre performances et coûts dans les scènes réelles En raison de l'importance et de la grande attention accordée aux applications de grands modèles, de plus en plus d'équipes ont investi dans la piste des bases de données vectorielles. L’objectif initial de tout le monde était d’améliorer le QPS dans les scénarios de recherche vectorielle pure, mais la la recherche vectorielle pure est loin d’être suffisante ! Dans les scénarios réels, la modélisation des données, la flexibilité et la précision des requêtes, ainsi que l'équilibre entre la densité des données, les performances et les coûts des requêtes sont des problèmes plus importants.
Dans le scénario RAG, les performances des requêtes vectorielles pures ont un excès de 10x, les vecteurs occupent d'énormes ressources, le manque de fonctions de requête conjointes, les performances et la précision médiocres sont souvent la norme dans les bases de données vectorielles propriétaires actuelles. MyScaleDB s'engage à améliorer les performances globales des bases de données d'IA dans des scénarios réels de données massives Son benchmark de base de données vectorielles MyScale est également le premier du secteur à comparer les performances globales et la rentabilité des systèmes de bases de données vectorielles grand public dans différents scénarios de requêtes. à l'échelle de cinq millions de vecteurs. Système d'évaluation open source, tout le monde est invité à prêter attention et à soulever des problèmes. L'équipe MyScale a déclaré qu'il y avait encore beaucoup de place pour optimiser la base de données IA dans des scénarios d'application réels, et elle espère également continuer à peaufiner le produit et à améliorer le système d'évaluation dans la pratique.
Adresse du projet MyScale Vector Database Benchmark : https://github.com/myscale/vector-db-benchmarkOutlook : Plateforme d'agent grand modèle + big data prise en charge par la base de données IA
Machine learning + big data ont fait le succès d'Internet et de la précédente génération de systèmes d'information A l'ère des big models, l'équipe MyScale s'engage également à proposer une nouvelle génération de solutions big model + big data. Avec une base de données SQL + vectorielle hautes performances comme support solide, MyScaleDB fournit les capacités clés de traitement de données à grande échelle, de requête de connaissances, d'observabilité, d'analyse de données et d'apprentissage de petits échantillons, créant ainsi une boucle fermée d'IA et de données, devenant ainsi next A génération de grands modèles + la base clé de la plateforme big data Agent. L'équipe MyScale a déjà exploré la mise en œuvre de cette solution dans les domaines de la recherche scientifique, de la finance, de l'industrie, du médical et autres. Avec le développement rapide de la technologie, un certain sens de l'intelligence artificielle générale (AGI) devrait apparaître dans les 5 à 10 prochaines années. Concernant cette question, nous ne pouvons nous empêcher de réfléchir : faut-il un grand modèle statique, virtuel et compétitif par rapport aux humains, ou existe-t-il une autre solution plus complète ? Les données constituent sans aucun doute un lien important entre les grands modèles, le monde et les utilisateurs. La vision de l'équipe MyScale est de combiner de manière organique les grands modèles et le big data pour créer un système d'IA plus professionnel, en temps réel et efficace en collaboration, mais aussi. plein de chaleur et de valeur humaines.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!