
Maison >Périphériques technologiques >IA >Les grands modèles sont également très puissants pour la prédiction de séries chronologiques ! L'équipe chinoise active les nouvelles capacités de LLM et surpasse les modèles traditionnels pour atteindre SOTA
Les grands modèles sont également très puissants pour la prédiction de séries chronologiques ! L'équipe chinoise active les nouvelles capacités de LLM et surpasse les modèles traditionnels pour atteindre SOTA

- PHPzavant
- 2024-04-11 09:43:20829parcourir
Le potentiel des grands modèles de langage est stimulé -
Une prédiction de séries chronologiques de haute précision peut être obtenue sans entraîner de grands modèles de langage, surpassant ainsi tous les modèles de séries chronologiques traditionnels.
L'Université Monash, Ant et IBM Research ont développé conjointement un cadre général qui a réussi à promouvoir la capacité des grands modèles de langage à traiter les données de séquence selon différentes modalités. Le cadre est devenu une innovation technologique importante.

La prédiction de séries chronologiques est bénéfique à la prise de décision dans des systèmes complexes typiques tels que les villes, l'énergie, les transports, la télédétection, etc.
Depuis, les grands modèles devraient révolutionner les méthodes d’exploration de données spatiotemporelles et de séries temporelles.
Cadre général de reprogrammation de grands modèles de langage
L'équipe de recherche a proposé un cadre général pour utiliser facilement de grands modèles de langage pour la prédiction générale de séries chronologiques sans aucune formation.
Propose principalement deux technologies clés : la reprogrammation des entrées de synchronisation ;
Time-LLM utilise d'abord des prototypes de texte (Text Prototypes) pour reprogrammer les données temporelles d'entrée, et utilise une représentation en langage naturel pour représenter les informations sémantiques des données temporelles, alignant ainsi deux modalités de données différentes, de sorte que les grands modèles de langage n'aient pas besoin Toute modification pour comprendre les informations derrière une autre modalité de données. Dans le même temps, le grand modèle de langage ne nécessite aucun ensemble de données de formation spécifique pour comprendre les informations derrière les différentes modalités de données. Cette méthode améliore non seulement la précision du modèle, mais simplifie également le processus de prétraitement des données.
Afin de mieux gérer les données de séries chronologiques d'entrée et l'analyse des tâches correspondantes, l'auteur a proposé le paradigme Prompt-as-Prefix (PaP). Ce paradigme active pleinement les capacités de traitement de LLM sur les tâches temporelles en ajoutant des informations contextuelles supplémentaires et des instructions de tâches avant la représentation des données temporelles. Cette méthode permet d'obtenir une analyse plus raffinée des tâches de synchronisation et d'activer pleinement les capacités de traitement de LLM sur les tâches de synchronisation en ajoutant des informations contextuelles supplémentaires et des instructions de tâche devant le tableau de données de synchronisation.
Les principales contributions incluent :
- Proposition d'un nouveau concept de reprogrammation de grands modèles de langage pour l'analyse temporelle sans aucune modification du modèle de langage de base.
- Propose Time-LLM, un cadre de reprogrammation de modèle de langage général, qui implique la reprogrammation des données temporelles d'entrée dans une représentation prototype de texte plus naturelle et l'amélioration du contexte d'entrée avec des indices déclaratifs (tels que les connaissances d'experts du domaine et les descriptions de tâches) , pour guider le LLM pour un raisonnement inter-domaines efficace.

- Les performances des tâches de prédiction traditionnelles dépassent systématiquement les performances des meilleurs modèles existants, en particulier dans les scénarios à quelques échantillons et à zéro échantillon. De plus, Time-LLM est capable d'atteindre des performances plus élevées tout en conservant une excellente efficacité de reprogrammation du modèle. Libérez considérablement le potentiel inexploité du LLM pour les séries chronologiques et autres données séquentielles.
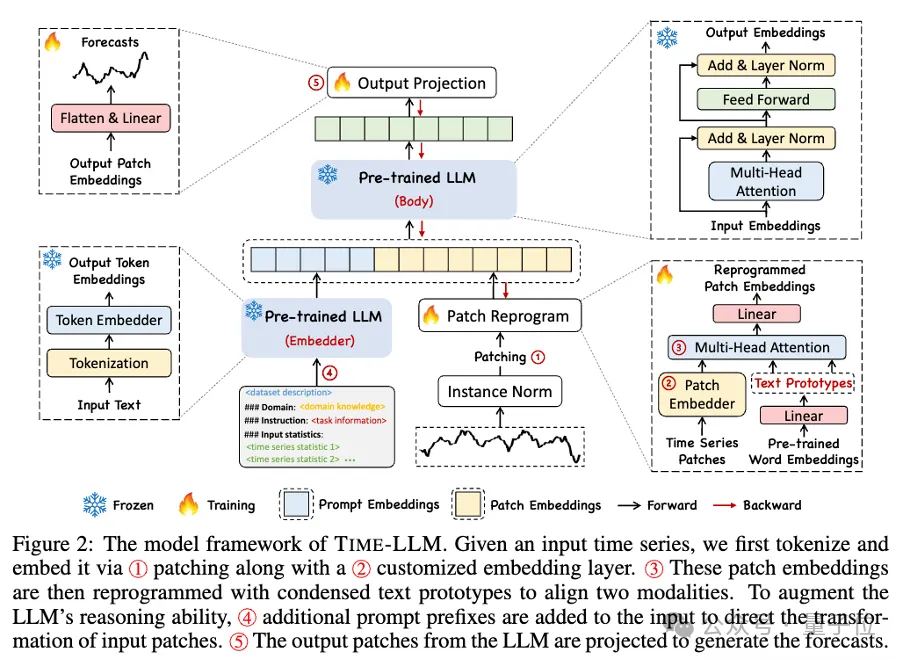
En regardant ce cadre plus spécifiquement, d'abord, les données de séries chronologiques d'entrée sont d'abord normalisées par RevIN, puis divisées en différents correctifs et mappées à l'espace latent.
Il existe des différences significatives dans les méthodes d'expression entre les données de séries chronologiques et les données textuelles, et elles appartiennent à des modalités différentes.
Les séries chronologiques ne peuvent ni être éditées directement ni décrites sans perte en langage naturel. Par conséquent, nous devons aligner les fonctionnalités d’entrée temporelles sur le domaine textuel en langage naturel.

Une manière courante d'aligner différentes modalités est l'attention croisée, mais le vocabulaire inhérent du LLM est très vaste, il est donc impossible d'aligner efficacement et directement les caractéristiques temporelles sur tous les mots, et tous les mots ne sont pas liés au temps. Les séquences ont des relations sémantiques alignées.
Afin de résoudre ce problème, ce travail effectue une combinaison linéaire de vocabulaires pour obtenir des prototypes de texte. Le nombre de prototypes de texte est beaucoup plus petit que le vocabulaire original, et la combinaison peut être utilisée pour représenter les caractéristiques changeantes des données de séries chronologiques. .
Afin d'activer pleinement la capacité du LLM sur des tâches de timing spécifiées, ce travail propose un paradigme de préfixage rapide.
Pour faire simple, certaines informations préalables de l'ensemble de données de séries chronologiques sont transmises à LLM sous forme de langage naturel en tant qu'invite de préfixe, et les caractéristiques de séries chronologiques alignées sont associées à LLM. Cela peut-il améliorer l'effet de prédiction. ?
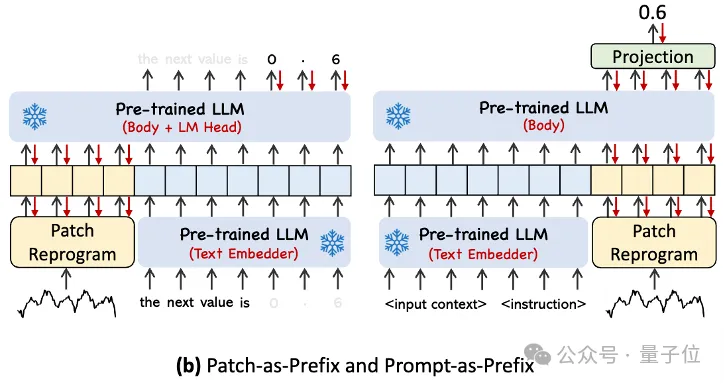
En pratique, les auteurs ont identifié trois éléments clés pour créer des invites efficaces :
le contexte de l'ensemble de données ; (2) les instructions de tâche, permettant à LLM de s'adapter aux différentes tâches en aval, (3) les descriptions statistiques, telles que les tendances et les délais ; , etc., permettant à LLM de mieux comprendre les caractéristiques des données de séries chronologiques.

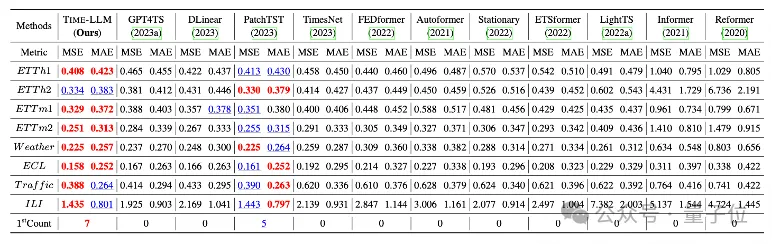
L'équipe a mené des tests complets sur 8 ensembles de données publiques classiques pour des prédictions à long terme.
Le résultat est que Time-LLM dépasse largement les meilleurs résultats précédents dans le domaine dans la comparaison de référence. Par exemple, par rapport à GPT4TS qui utilise directement GPT-2, Time-LLM présente une amélioration significative, indiquant l'efficacité de cette méthode. .
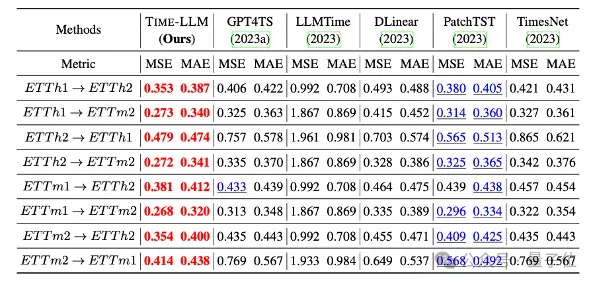
De plus, il montre également une forte capacité de prédiction dans des scénarios sans tir.
Ce projet est soutenu par NextEvo, le département R&D d'innovation en IA de la division Intelligent Engine d'Ant Group.
Les amis intéressés peuvent cliquer sur le lien ci-dessous pour en savoir plus sur le papier~
Lien papierhttps://arxiv.org/abs/2310.01728.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce que l'algorithme d'intelligence artificielle
- Quelles sont les tendances de développement de l'intelligence artificielle ?
- Le langage C ne trouve pas d'identifiant lors de l'appel de la fonction dans main
- L'impact de l'intelligence artificielle sur nos vies
- Analyse comparative de Bing Chat : fonction de « conversation » bêta publique à petite échelle de Baidu Search, basée sur le modèle linguistique Wenxin Yiyan