
Maison >Périphériques technologiques >IA >L'architecture Llama est-elle inférieure à GPT2 ? Le jeton magique améliore la mémoire 10 fois ?
L'architecture Llama est-elle inférieure à GPT2 ? Le jeton magique améliore la mémoire 10 fois ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-10 15:13:131462parcourir
Quelle quantité de connaissances humaines un modèle de langage à l'échelle 7B peut-il stocker ? Comment quantifier cette valeur ? Comment les différences dans le temps de formation et l’architecture du modèle affecteront-elles cette valeur ? Quel impact la quantification par compression en virgule flottante, le modèle expert mixte MoE et les différences de qualité des données (connaissances encyclopédiques par rapport aux déchets Internet) auront-elles sur la capacité de connaissance du LLM ?
La dernière recherche "Language Model Physics Part 3.3: Scaling Laws of Knowledge" de Zhu Zeyuan (Meta AI) et Li Yuanzhi (MBZUAI) a utilisé des expériences massives (50 000 tâches, un total de 4 200 000 heures GPU) pour résumer 12 lois , qui sont La capacité de connaissance du LLM sous différents fichiers fournit une méthode de mesure plus précise.

L'auteur a d'abord souligné qu'il est irréaliste de mesurer la loi d'échelle du LLM par les performances du modèle open source sur l'ensemble de données de référence (benchmark). Par exemple, LLaMA-70B fonctionne 30 % mieux que LLaMA-7B sur l'ensemble de données de connaissances. Cela ne signifie pas qu'étendre le modèle par 10 ne peut augmenter la capacité que de 30 %. Si un modèle est entraîné à l’aide de données réseau, il sera également difficile d’estimer la quantité totale de connaissances qu’il contient.
Pour un autre exemple, lorsque l'on compare la qualité des modèles Mistral et Llama, la différence est-elle causée par leurs différentes architectures de modèles, ou est-elle causée par la préparation différente de leurs données d'entraînement ?
Sur la base des considérations ci-dessus, l'auteur adopte l'idée centrale de sa série d'articles "Language Model Physics", qui consiste à créer des données artificiellement synthétisées et à contrôler strictement les éléments de connaissance contenus dans les données en contrôlant la quantité et type de connaissances dans les données). Dans le même temps, l'auteur utilise des LLM de différentes tailles et architectures pour s'entraîner sur des données synthétiques, et donne des définitions mathématiques pour calculer avec précision le nombre d'éléments de connaissances que le modèle entraîné a appris à partir des données.

- Adresse de l'article : https://arxiv.org/pdf/2404.05405.pdf
- Titre de l'article : Physique des modèles linguistiques : partie 3.3, Lois de mise à l'échelle des capacités de connaissances
Pour cette étude, certains ont dit que cette orientation semble raisonnable. Nous pouvons analyser la loi d’échelle de manière très scientifique.
Certaines personnes pensent également que cette recherche amène la mise à l'échelle du droit à un niveau différent. Certainement un article incontournable pour les praticiens.
Aperçu de la recherche
Les auteurs ont étudié trois types de données synthétiques : bioS, bioR, bioD. bioS est une biographie écrite à l'aide de modèles anglais, bioR est une biographie écrite à l'aide du modèle LlaMA2 (22 Go au total), bioD est une sorte de données de connaissances virtuelles qui peuvent contrôler davantage les détails (par exemple, la longueur des connaissances et le vocabulaire peut être contrôlé Attendez les détails). L'auteurse concentre sur l'architecture du modèle de langage basée sur GPT2, LlaMA et Mistral, parmi lesquels GPT2 utilise la technologie Rotary Position Embedding (RoPE) mise à jour.
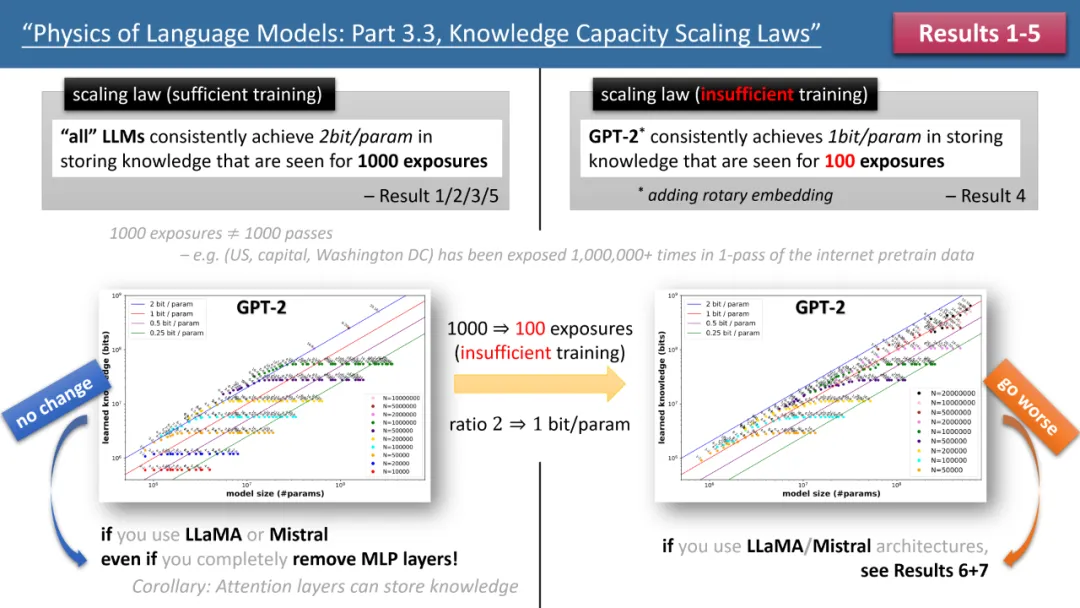
L'image de gauche montre des lois de mise à l'échelle avec un temps de formation suffisant, et l'image de droite montre des lois de mise à l'échelle avec un temps de formation insuffisant
La figure 1 ci-dessus présente brièvement les 5 premières lois proposées par l'auteur , où gauche/droite correspondent respectivement à « formation ». Les deux situations « temps suffisant » et « temps de formation insuffisant » correspondent respectivement à un savoir commun (par exemple, la capitale de la Chine est Pékin) et un savoir moins commun (par exemple, la Le Département de physique de l'Université Tsinghua a été créé en 1926).
Si le temps de formation est suffisant, l'auteur a constaté que quelle que soit l'architecture de modèle utilisée, GPT2 ou LlaMA/Mistral, l'efficacité de stockage du modèle peut atteindre 2 bits/param - c'est-à-dire que chaque paramètre du modèle peut stocker 2 des bribes d'informations en moyenne. Cela n'a rien à voir avec la profondeur du modèle, seulement avec sa taille. En d’autres termes, un modèle 7B, s’il est correctement formé, peut stocker 14 milliards de bits de connaissances, ce qui est plus que les connaissances humaines contenues dans Wikipédia et dans tous les manuels d’anglais réunis !
Ce qui est encore plus surprenant, c'est que bien que la théorie traditionnelle estime que les connaissances du modèle de transformateur sont principalement stockées dans la couche MLP, les recherches de l'auteur réfutent ce point de vue. Ils ont découvert que même si toutes les couches MLP sont supprimées, le modèle peut toujours atteindre. 2 bits/Efficacité de stockage du paramètre.
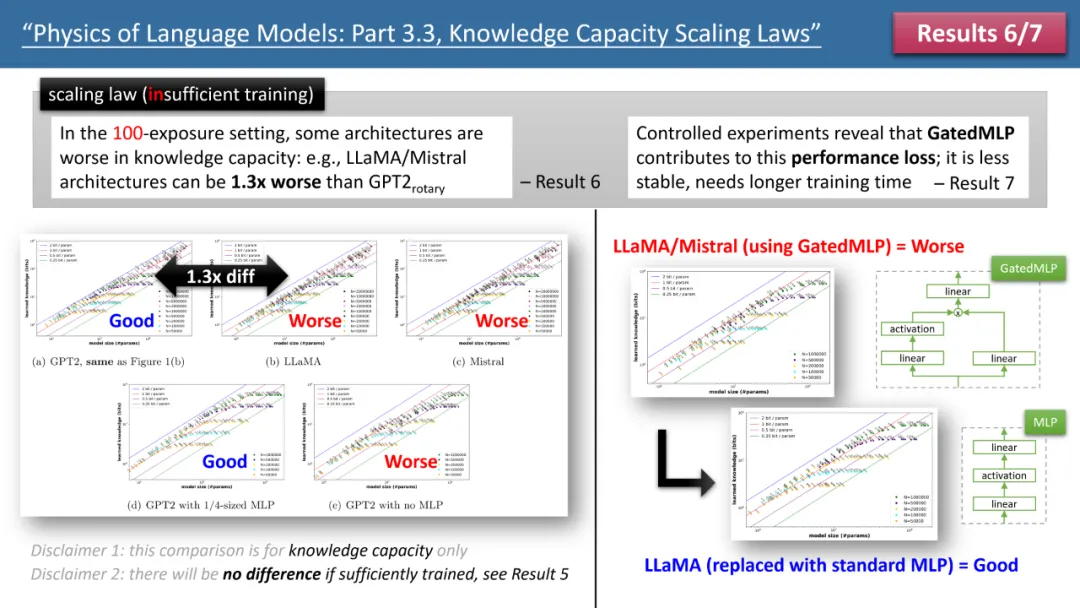
Figure 2 : Lois de mise à l'échelle en cas de temps d'entraînement insuffisant
Cependant, lorsque l'on examine le cas d'un temps d'entraînement insuffisant, les différences entre les modèles deviennent apparentes. Comme le montre la figure 2 ci-dessus, dans ce cas, le modèle GPT2 peut stocker plus de 30 % de connaissances en plus que LlaMA/Mistral, ce qui signifie que le modèle d'il y a quelques années surpasse le modèle actuel à certains égards . Pourquoi cela arrive-t-il? L'auteur a effectué des ajustements architecturaux sur le modèle LlaMA, en ajoutant ou en soustrayant chaque différence entre le modèle et GPT2, et a finalement découvert que GatedMLP était à l'origine de la perte de 30 %.
Pour souligner, GatedMLP n'entraîne pas de modification du taux de stockage "final" du modèle - car la figure 1 nous dit qu'ils ne seront pas différents si l'entraînement est suffisant. Cependant, GatedMLP conduira à une formation instable, donc les mêmes connaissances nécessitent un temps de formation plus long, en d'autres termes, pour les connaissances qui apparaissent rarement dans l'ensemble de formation, l'efficacité de stockage du modèle diminuera ;
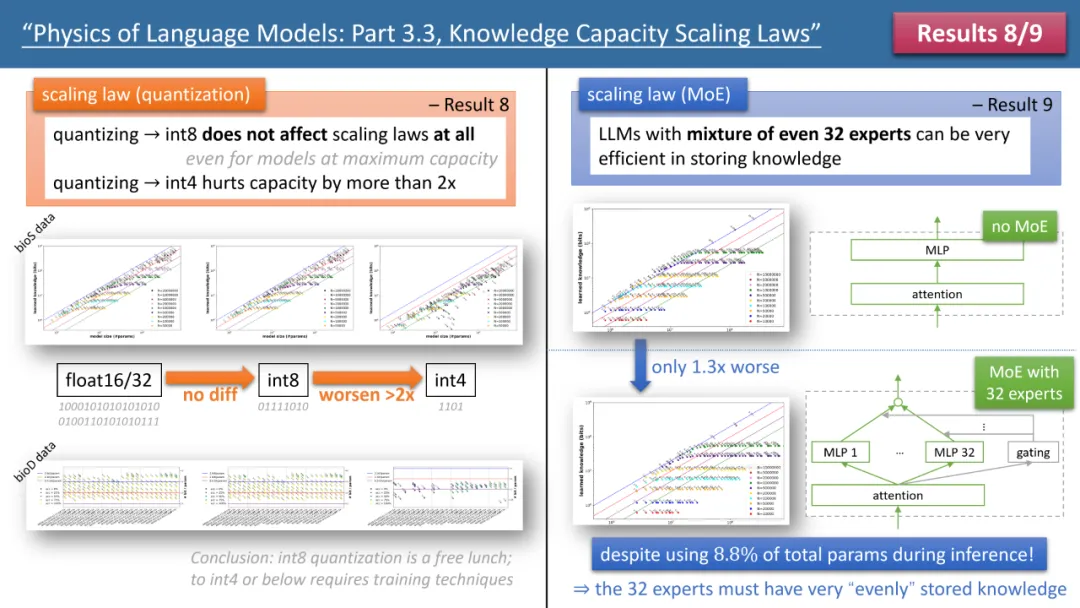
Figure 3 : L'impact de la quantification et du MoE sur les lois de mise à l'échelle du modèle
Les lois 8 et 9 de l'auteur étudient respectivement l'impact de la quantification et du MoE sur les lois de mise à l'échelle du modèle, et la conclusion est présentée dans la figure 3 ci-dessus. L'un des résultats est que la compression du modèle entraîné de float32/16 vers int8 n'a aucun impact sur le stockage des connaissances, même pour les modèles qui ont atteint la limite de stockage de 2 bits/param.
Cela signifie que LLM peut atteindre 1/4 de la "limite de la théorie de l'information" - car le paramètre int8 n'est que de 8 bits, mais en moyenne chaque paramètre peut stocker 2 bits de connaissances. L’auteur souligne qu’il s’agit d’une loi universelle qui n’a rien à voir avec la forme d’expression du savoir.
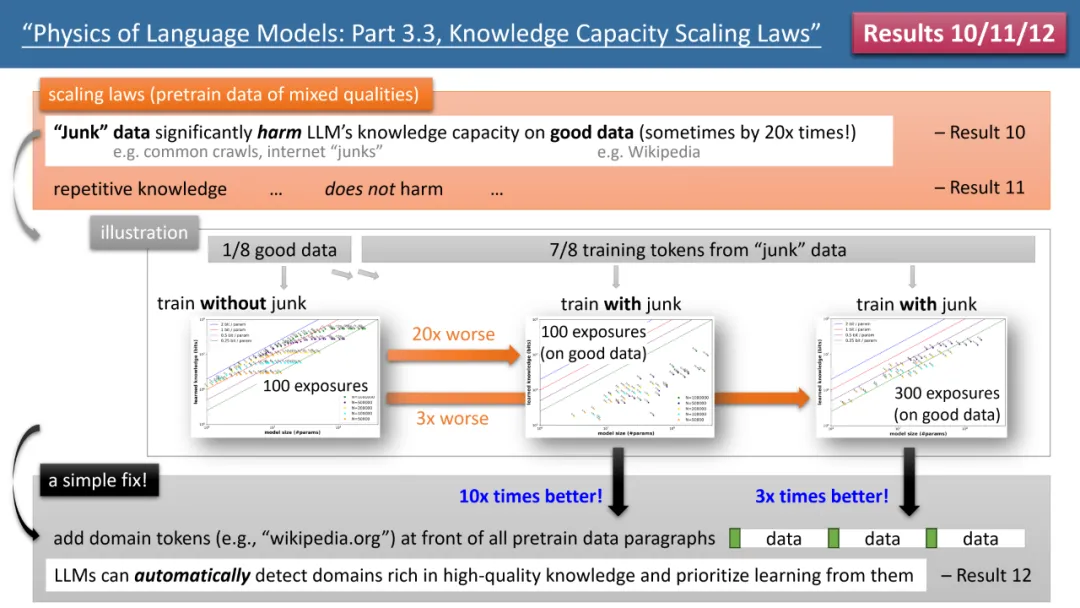
Les résultats les plus frappants proviennent des lois 10 à 12 des auteurs (voir Figure 4). Si nos données de (pré-)formation, 1/8 proviennent de bases de connaissances de haute qualité (telles que l'Encyclopédie Baidu), et 7/8 proviennent de données de mauvaise qualité (telles que des analyses courantes ou des conversations de forum, ou même des déchets complètement aléatoires). données).
Alors, des données de faible qualité affecteront-elles l'absorption par LLM de connaissances de haute qualité ? Les résultats sont surprenants. Même si le temps de formation pour des données de haute qualité reste constant, « l'existence elle-même » de données de mauvaise qualité peut réduire de 20 fois le stockage de connaissances de haute qualité par le modèle ! Même si le temps de formation sur des données de haute qualité est multiplié par 3, la réserve de connaissances sera quand même réduite par 3. C’est comme jeter de l’or dans le sable : des données de haute qualité sont gaspillées.
Y a-t-il un moyen de résoudre ce problème ? L'auteur a proposé une stratégie simple mais extrêmement efficace, qui ajoute simplement votre propre jeton de nom de domaine de site Web à toutes les données de (pré)formation. Par exemple, ajoutez toutes les données Wikipédia à wikipedia.org. Le modèle ne nécessite aucune connaissance préalable pour identifier quels sites Web ont des connaissances « or », mais peut découvrir automatiquement des sites Web avec des connaissances de haute qualité pendant le processus de pré-formation, et automatiquement libérer de l'espace de stockage pour ces connaissances de haute qualité. données .
L'auteur a proposé une expérience simple pour vérifier : si des données de haute qualité sont ajoutées avec un jeton spécial (n'importe quel jeton spécial fera l'affaire, le modèle n'a pas besoin de savoir à l'avance de quel jeton il s'agit), alors la connaissance du modèle le stockage peut immédiatement être multiplié par 10, n'est-ce pas incroyable ? Par conséquent, l'ajout de jetons de nom de domaine aux données de pré-formation est une opération de préparation des données extrêmement importante.
Conclusion
L'auteur estime que grâce aux données synthétiques, le calcul le modèle est formé La méthode des connaissances totales acquises au cours du processus peut fournir un système de notation systématique et précis pour « évaluer l'architecture du modèle, les méthodes de formation et la préparation des données ». Ceci est complètement différent des comparaisons de référence traditionnelles et est plus fiable. Ils espèrent que cela aidera les concepteurs des futurs LLM à prendre des décisions plus éclairées.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment créer et utiliser le modèle de modèle de framework Laravel
- Comprendre le modèle de boîte CSS : Comprendre ce qu'est le modèle de boîte CSS en 5 minutes ?
- Quels sont les modèles de données couramment utilisés ?
- Quelles sont les raisons et les solutions à l'échec de la connexion à la base de données ?
- Quels sont les huit types de données de base ?