La première stratégie d'adaptation de domaine pour le grand modèle "Segment Anything" est là ! Les articles connexes ont été acceptés par CVPR 2024. Le succès des grands modèles de langage (LLM) a inspiré le domaine de la vision par ordinateur à explorer les modèles de base pour la segmentation. Ces modèles de segmentation de base sont généralement utilisés pour la segmentation de zéro/quelques images via Prompt Engineer. Parmi eux, Segment Anything Model (SAM) est le modèle de base le plus avancé pour la segmentation d’images.个 Tu SAM a obtenu de mauvais résultats sur plusieurs tâches en aval. Mais des recherches récentes montrent que SAM n'est pas très puissant et généralisé dans de nombreuses tâches en aval, comme de mauvaises performances dans des domaines tels que les images médicales, les objets camouflés et les images naturelles avec des interférences supplémentaires. Cela peut être dû au grand Domain Shift entre l'ensemble de données d'entraînement et l'ensemble de données de test en aval. Par conséquent, une question très importante est de savoir comment concevoir un schéma d’adaptation de domaine pour rendre SAM plus robuste face au monde réel et aux diverses tâches en aval ?
Adapter SAM pré-entraîné aux tâches en aval se heurte principalement à trois défis :
Premièrement, le paradigme traditionnel d'adaptation de domaine non supervisé nécessite un ensemble de données source
et un ensemble de données cible, en raison de la confidentialité et des coûts de calcul sont moindres. réalisable. 
Deuxièmement, pour l'adaptation du domaine, la mise à jour de tous les poids fonctionne généralement mieux, mais est également limitée par des
coûts de mémoire coûteux. Enfin, SAM peut démontrer diverses capacités de segmentation pour des invites de différents types et granularités, donc
en cas de manque d'informations sur les invites pour les tâches en aval
, l'adaptation non supervisée sera très difficile.大 Figure 1 SAM est un pré-entraînement sur des ensembles de données à grande échelle, mais il existe un problème de généralisation. Nous utilisons une supervision faible pour adapter SAM sur diverses tâches en aval afin d'améliorer la robustesse adaptative
et l'efficacité informatique . Plus précisément, nous adoptons d'abord une stratégie d'auto-formation dans le domaine passif pour éviter la dépendance aux données sources. L'auto-formation génère des pseudo-étiquettes pour superviser les mises à jour du modèle, mais elles sont sensibles aux pseudo-étiquettes incorrectes. Nous introduisons le
modèle source gelé comme réseau d'ancrage pour standardiser les mises à jour du modèle.
- Pour réduire davantage le coût de calcul élevé lié à la mise à jour des poids complets du modèle, nous appliquons une décomposition des poids de bas rang à l'encodeur et effectuons une rétropropagation via un chemin de raccourci de bas rang.
- Enfin, afin d'améliorer encore l'effet de l'adaptation passive du domaine, nous introduisons une supervision faible, telle que des annotations de points clairsemées, dans le domaine cible pour fournir en même temps des informations d'adaptation de domaine plus fortes. Ce type de supervision faible est naturellement compatible avec l'encodeur de repère dans SAM.
- Avec un encadrement faible comme Prompt, nous obtenons des pseudo labels auto-formés plus locaux et explicites. Le modèle optimisé montre une capacité de généralisation plus forte sur plusieurs tâches en aval.
Nous résumons les contributions de ce travail comme suit : 
1 Inspirés par le problème de généralisation du SAM dans les tâches en aval, nous proposons une solution indépendante des tâches et ne nécessitant pas de données sources, par. S'entraîner automatiquement pour s'adapter au SAM. 2. Nous utilisons une supervision faible, y compris des cases, des points et d'autres étiquettes, pour améliorer l'effet adaptatif. Ces étiquettes faiblement supervisées sont entièrement compatibles avec l'encodeur d'invite de SAM. 3. Nous menons des expériences approfondies sur 5 types de tâches de segmentation d'instances en aval pour démontrer l'efficacité de la méthode adaptative faiblement supervisée proposée.
- Adresse de l'article : https://arxiv.org/pdf/2312.03502.pdf
- Adresse du projet : https://github.com/Zhang-Haojie/WeSAM
-
Titre de l'article : Améliorer la généralisation de Modèle de base de segmentation sous changement de distribution via une adaptation faiblement supervisée
Basé sur auto-formation Comment le cadre adaptatif
une supervision faible aide à parvenir à une auto-formation efficace
mise à jour du poids de faible rang
- 1. Segmenter n'importe quel modèle
-
SAM consiste principalement de trois composants Composition :
Image Encoder (ImageEncoder), Prompt Encoder (PromptEncoder) et Decoder (MaskDecoder) - .
-
L'encodeur d'image est pré-entraîné à l'aide de MAE, et l'ensemble du SAM est affiné davantage sur l'ensemble d'entraînement SA-1B avec 1,1 milliard d'annotations. Une combinaison de perte focale et de perte de dés est utilisée pendant l'entraînement. Au moment de l'inférence, une image de test x est d'abord codée par un encodeur d'image, puis, à l'invite, un décodeur léger effectue trois niveaux de prédictions.
2. Auto-formation sur l'adaptation de domaine sans source Auto-formation adaptée au domaine
Pour l'ensemble de données cible non étiqueté DT={xi} et le pré- modèle de segmentation entraîné. Nous utilisons l'architecture élève-enseignant pour l'auto-formation. Comme le montre la figure 2, nous maintenons trois réseaux d'encodeurs, à savoir le modèle d'ancrage, le modèle d'étudiant et le modèle d'enseignant, où les modèles d'étudiant et d'enseignant partagent des poids. Plus précisément, pour chaque échantillon xi, une augmentation aléatoire des données faibles est appliquée comme entrée des modèles d'ancrage et d'enseignant, une augmentation aléatoire des données fortes est appliquée comme entrée du modèle étudiant, et trois encodages de réseau d'encodeurs sont généré trois cartes de fonctionnalités. 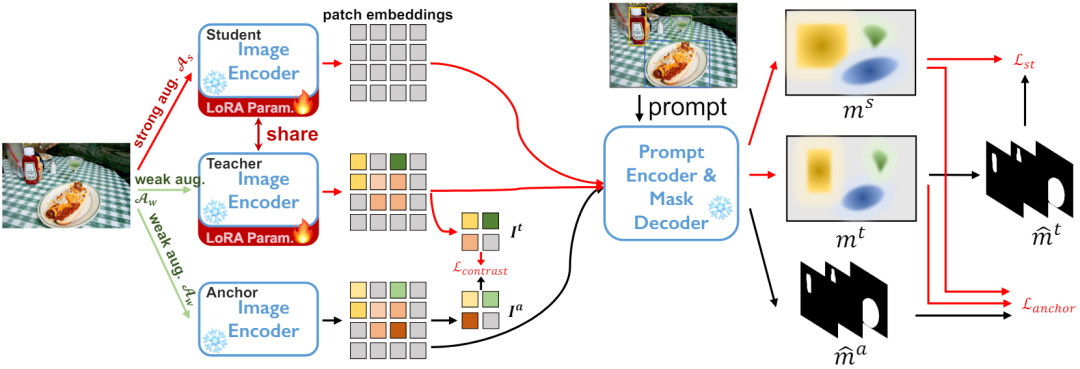 Dans le réseau de décodeur, étant donné un certain nombre Np d'invites, telles qu'une boîte, un point ou un masque grossier, un ensemble de masques de segmentation d'instance sera déduit.
Dans le réseau de décodeur, étant donné un certain nombre Np d'invites, telles qu'une boîte, un point ou un masque grossier, un ensemble de masques de segmentation d'instance sera déduit.
Sur la base des connaissances ci-dessus, nous développons ci-dessous les trois ensembles d'objectifs d'optimisation pour l'auto-formation. 1) Auto-formation élève-enseignant Nous mettons d'abord à jour le modèle élève/enseignant en utilisant la même fonction de perte utilisée lors de la formation de SAM comme objectif d'optimisation de l'auto-formation. L’autoformation est largement utilisée dans l’apprentissage semi-supervisé et s’est récemment révélée très efficace pour l’adaptation passive au domaine. Plus précisément, nous utilisons les résultats de prédiction générés par le modèle de l'enseignant comme pseudo-étiquettes, et utilisons la perte focale et la perte de dés pour superviser la production des élèves.
2) Perte d'ancrage pour une régularisation robuste
L'entraînement en réseau utilisant uniquement la perte d'auto-entraînement est sensible à l'accumulation de faux pseudo-étiquettes prédits par le réseau d'enseignants, ce qu'on appelle le biais de confirmation. Les observations montrent également que les performances se dégradent après de longues itérations utilisant uniquement l'auto-formation. Les méthodes d'adaptation de domaine passives existantes emploient souvent des contraintes supplémentaires pour éviter les effets négatifs de l'auto-formation, telles qu'une distribution uniforme des prédictions.
Nous effectuons une régularisation par perte d'ancre, comme le montre l'équation 3,
minimise la perte de dés entre le modèle d'ancre et le modèle étudiant/enseignant respectivement. Le modèle d'ancrage gelé, en tant que connaissance héritée du domaine source, n'encourage pas un écart excessif entre le modèle source et le modèle de mise à jour d'auto-apprentissage, et peut empêcher l'effondrement du modèle. 3) Espace de fonctionnalité d'encodeur régularisé à perte de contraste 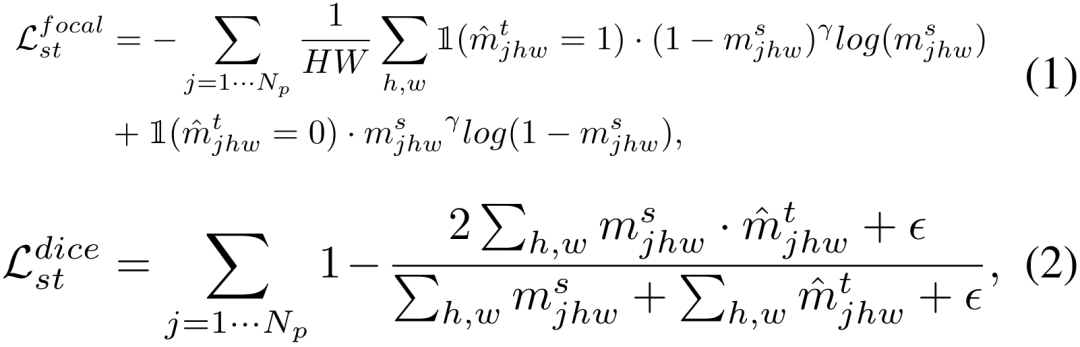 下 Comparaison perte des deux branches de la figure 3
下 Comparaison perte des deux branches de la figure 3
Les deux objectifs d'entraînement ci-dessus sont effectués dans l'espace de sortie du décodeur. La partie expérimentale révèle que la mise à jour du réseau d'encodeurs est le moyen le plus efficace d'adapter SAM, il est donc nécessaire d'appliquer directement la régularisation aux caractéristiques sorties du réseau d'encodeurs . Comme le montre la figure 3, nous recadrons les caractéristiques de chaque instance à partir de la carte des caractéristiques en fonction du masque prédit dans les branches d'ancrage et d'enseignant. Nous définissons plus en détail les paires d'échantillons positifs et négatifs dans la perte de contraste. Les paires d'échantillons positives sont construites à partir des caractéristiques d'instance correspondant à la même invite dans les deux branches, tandis que les paires d'échantillons négatives sont construites à partir des caractéristiques d'instance. correspondant à différentes invites de. La perte de contraste finale est indiquée ci-dessous, où
est le coefficient de température. 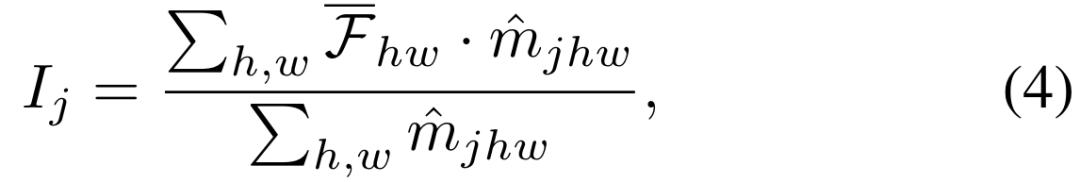
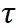 4) Perte totale
4) Perte totale 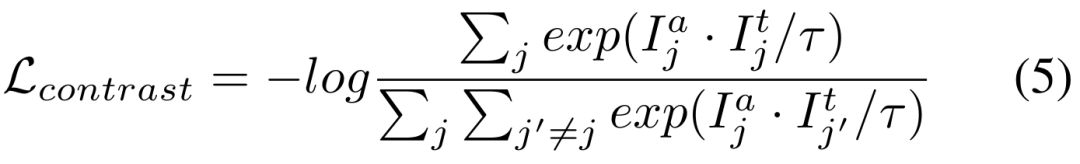
Nous combinons les trois fonctions de perte ci-dessus dans la perte adaptative finale sans source. 3. Génération d'invites auto-formée La segmentation SAM nécessite une entrée d'invite pour indiquer l'objet cible à segmenter, mais il peut y avoir des problèmes d'ambiguïté granulaire. Les projets Prompt peuvent être mis en œuvre de manière entièrement automatisée ou via une interaction humaine. 1) Générer une invite de manière entièrement automatiqueNous utilisons d'abord les points d'échantillonnage denses de la grille comme entrée rapide, générons les masques pour la segmentation de l'étape initiale via le modèle Anchor, éliminons les masques avec de faibles scores d'IoU et de stabilité, puis continuez. La suppression non maximale est utilisée pour obtenir les résultats de segmentation. Ensuite, un ensemble fixe d'invites est généré à partir des masques finaux comme entrée d'invite pour les trois branches. Par conséquent, les longueurs de masque des trois sorties de segmentation de réseau sont les mêmes et présentent une correspondance exacte biunivoque. 2) Faible supervision des invites Bien que les invites puissent être obtenues en utilisant un échantillonnage en grille sur l'image et en filtrant les masques de mauvaise qualité et en double pour une segmentation automatique. Mais ces segmentations sont de relativement mauvaise qualité, peuvent contenir de nombreuses prédictions faussement positives et ont une granularité peu claire. La qualité des invites qui en résulte est inégale, ce qui rend l'auto-formation moins efficace. Par conséquent, en nous appuyant sur des travaux antérieurs d'adaptation de domaine faiblement supervisés, nous proposons d'utiliser trois méthodes faiblement supervisées, notamment la boîte englobante, le point d'annotation de point clairsemé et le masque grossier de polygone de segmentation grossière. Dans SAM, ces méthodes de supervision faibles correspondent parfaitement à une saisie rapide, et une supervision faible peut être intégrée de manière transparente pour s'adapter à SAM. 4. Mise à jour du poids de bas rangL'énorme réseau d'encodeurs du modèle de base rend extrêmement difficile la mise à jour des poids de tous les modèles. Cependant, de nombreuses études existantes montrent que la mise à jour des pondérations du réseau d'encodeurs est un moyen efficace d'ajuster les modèles pré-entraînés. Pour pouvoir mettre à jour le réseau d'encodeurs de manière plus efficace et plus rentable, nous avons choisi une méthode de mise à jour de bas rang conviviale sur le plan informatique. Pour chaque poids θ dans le réseau de codeurs, nous utilisons une approximation de bas rang ω = AB et définissons un taux de compression r. Seuls A et B sont mis à jour via rétropropagation pour réduire l'utilisation de la mémoire. Pendant la phase d'inférence, les poids sont reconstruits en combinant l'approximation de bas rang avec les poids d'origine, c'est-à-dire θ = θ + AB. Dans les expériences, nous fournissons des comparaisons détaillées avec des méthodes de pointe et des résultats qualitatifs. Enfin, nous analysons l’efficacité de chaque partie et la conception spécifique du réseau. Dans ce travail, nous évaluons cinq types différents de tâches de segmentation en aval, dont certaines présentent des changements de distribution importants par rapport à SA-1B. L'ensemble de données couvre des images naturelles claires, des images naturelles avec des interférences supplémentaires, des images médicales, des objets camouflés et des images de robots, soit un total de 10 types. Partitionnement des données : chaque ensemble de données en aval est divisé en ensembles d'apprentissage et en ensembles de test qui ne se chevauchent pas. Le tableau 1 répertorie les ensembles de données sur lesquels chaque type de tâche en aval a été évalué, ainsi que la répartition des ensembles de données de formation et de test. 
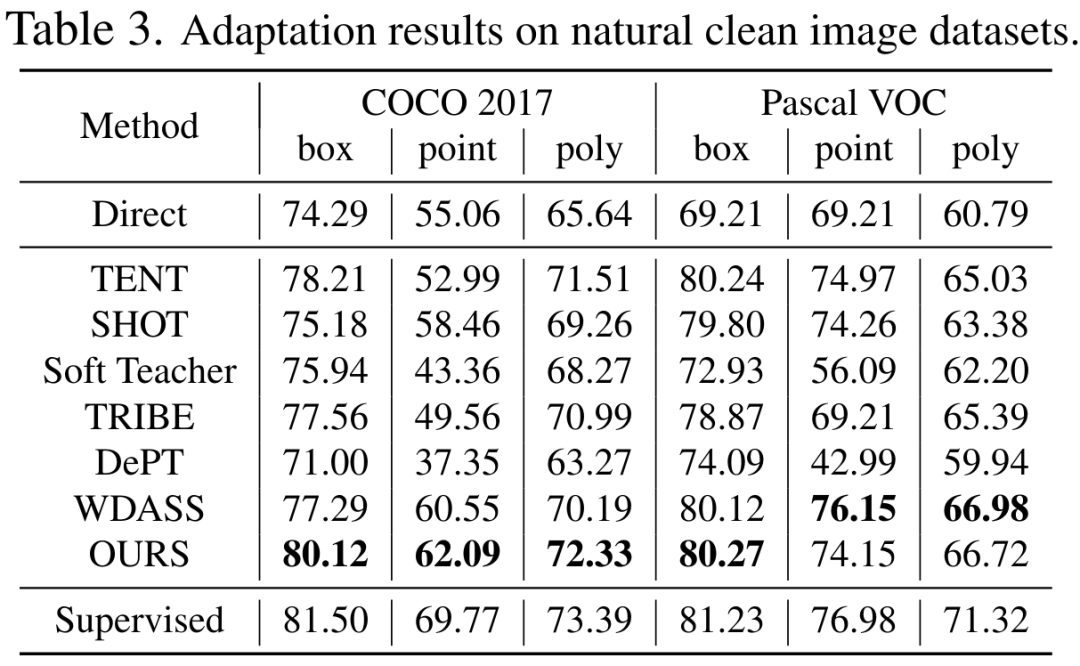
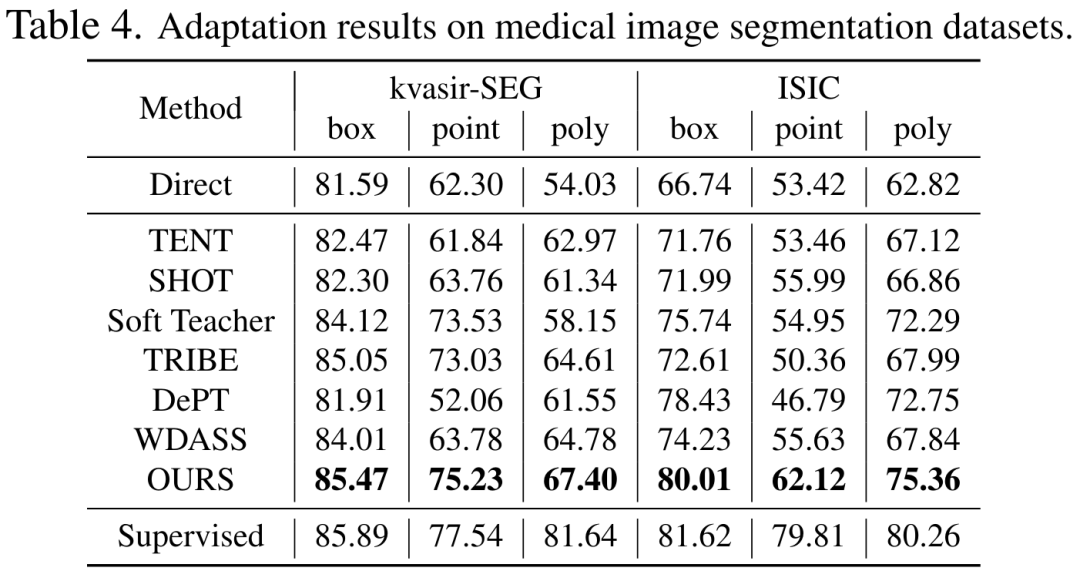
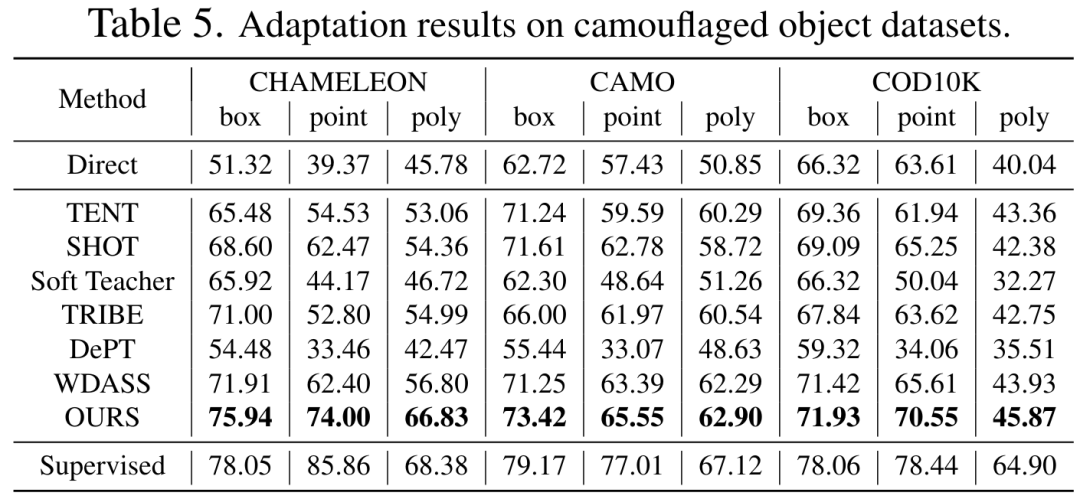
Modèle Segment-Anything : En raison de limitations de mémoire, nous adoptons ViT-B comme réseau d'encodeurs. Utilisez un encodeur d'indices standard et un décodeur de masque. Génération d'invites : les entrées d'invites pour les phases de formation et d'évaluation sont calculées à partir des masques GT de segmentation d'instance, simulant l'interaction humaine sous forme de supervision faible. Plus précisément, nous extrayons la boîte de la boîte englobante minimale de l'ensemble du masque GT. Les points sont créés en sélectionnant au hasard 5 points d'échantillonnage positifs dans le masque GT et 5 points d'échantillonnage négatifs à l'extérieur du masque. Les masques grossiers sont simulés en ajustant les polygones aux masques GT. 3. Résultats expérimentauxLes tableaux 2, 3, 4 et 5 sont respectivement les résultats des tests sur les images naturelles avec interférences supplémentaires, les images naturelles claires, les images médicales et les ensembles de données d'objets camouflés. Les résultats expérimentaux complets peuvent être trouvés dans l'article. Les expériences démontrent que notre schéma surpasse les schémas SAM pré-entraînés et d'adaptation de domaine de pointe sur presque tous les ensembles de données de segmentation en aval. 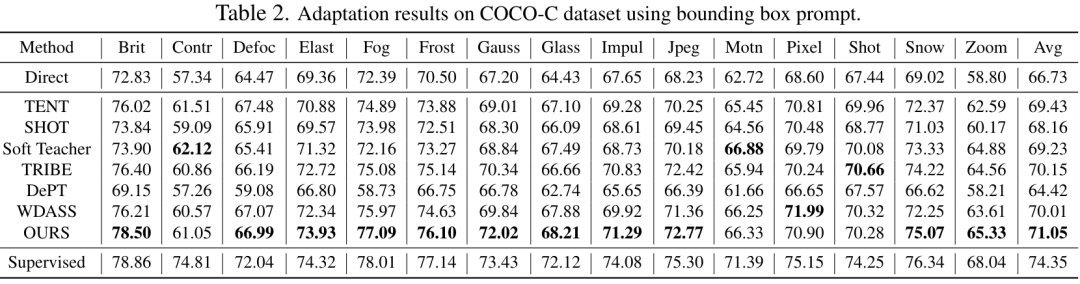
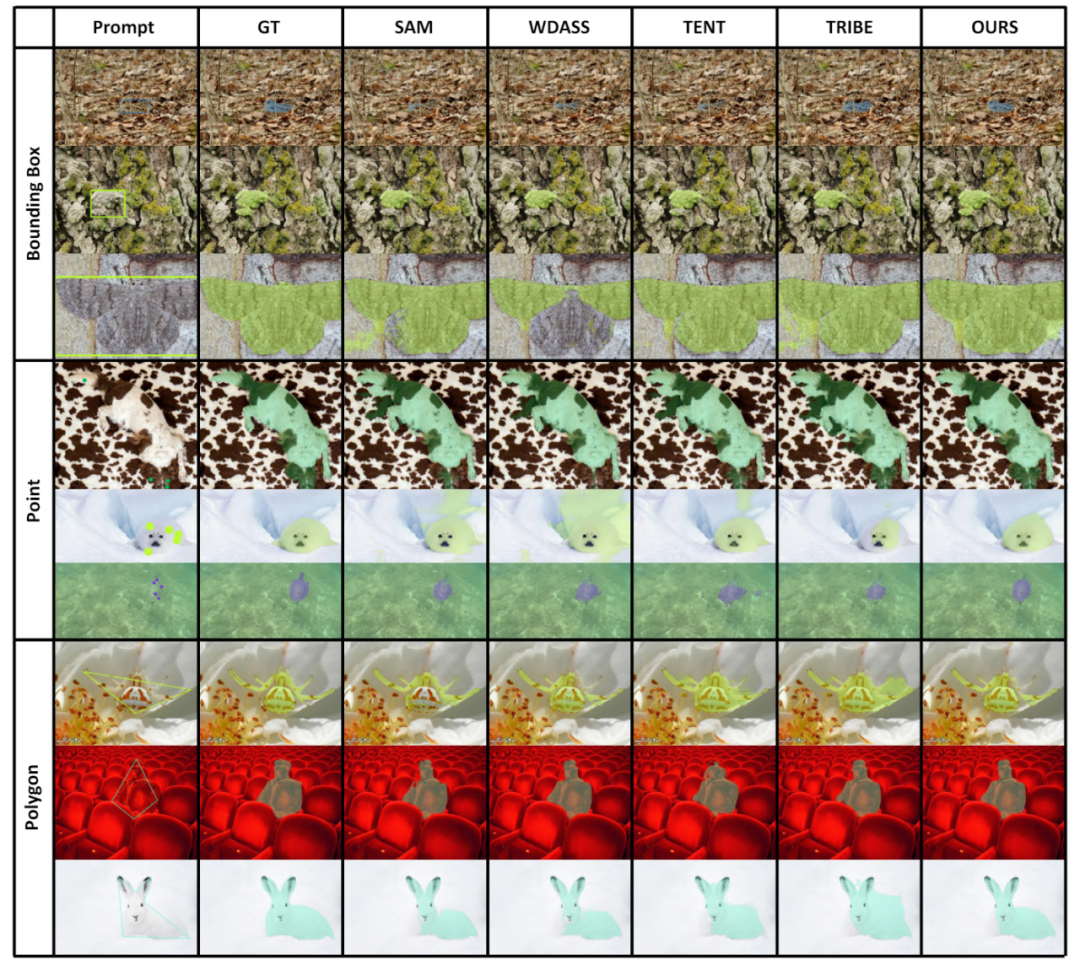
4. Résultats de visualisationUne partie des résultats de visualisation est présentée dans la figure 4, et d'autres résultats de visualisation peuvent être trouvés dans l'article. Figure 4 Résultats de visualisation de quelques exemples 
5. Expériences d'ablation et analyses complémentaires
Nous sommes sur l'ensemble de données COCO L'efficacité de chacun des trois objectifs d'optimisation d'auto-entraînement est analysée, comme le montre le tableau 7. . Dans le tableau 7, nous analysons également l'effet de la méthode proposée sur l'adaptation sans utiliser d'informations de supervision faibles. 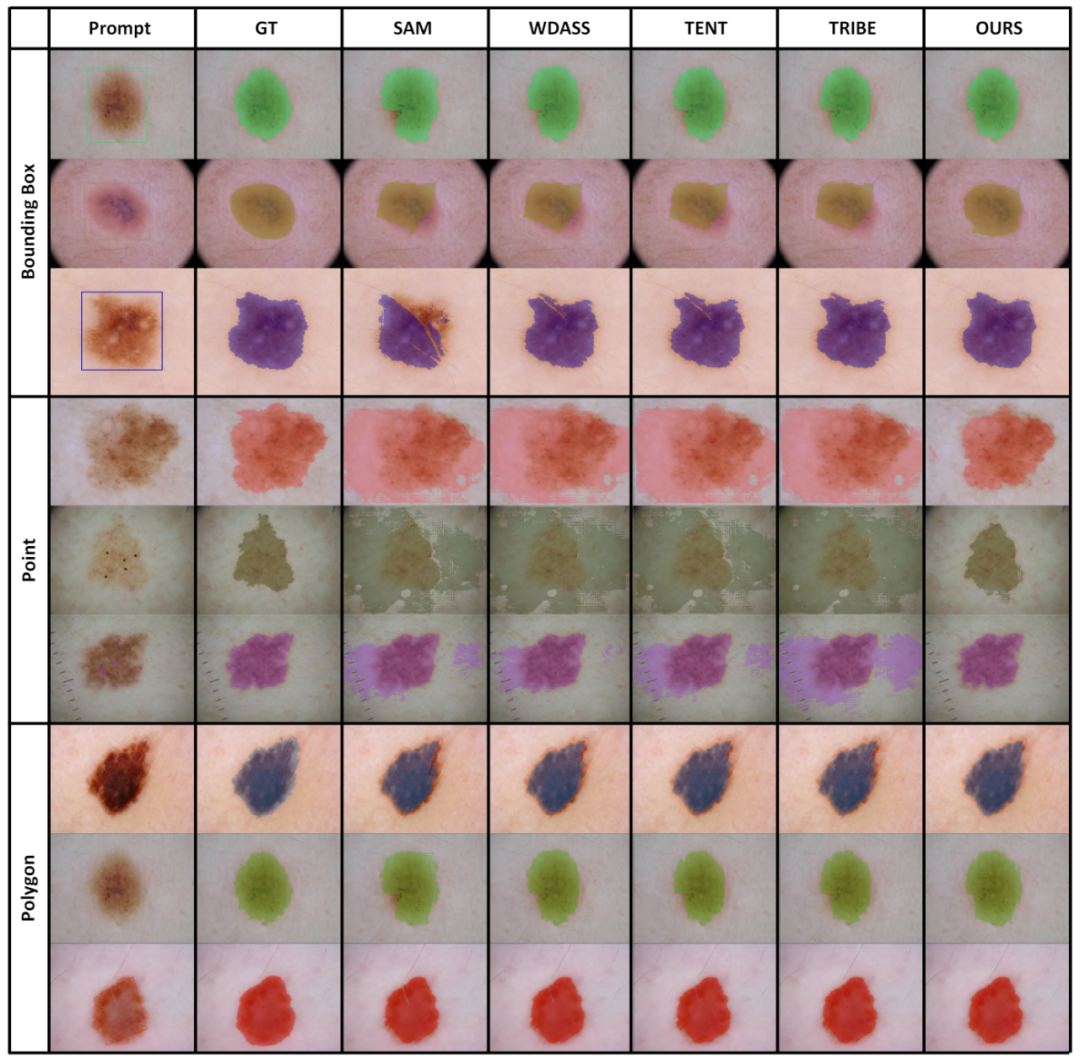
Nous avons analysé la différence de performances entre l'entraînement et les tests en utilisant différentes catégories d'invites, comme le montre le tableau 8. Les expériences montrent que notre schéma fonctionne toujours bien dans des conditions d'invites croisées. De plus, nous avons également analysé les résultats expérimentaux d'optimisation de différents modules, y compris les décodeurs, LayerNorm et différents schémas de réglage fin, ainsi que leurs combinaisons, et leurs expériences ont prouvé que le schéma LoRA de l'encodeur de réglage fin a le meilleur effet.
RésuméBien que le modèle de vision de base puisse bien fonctionner sur les tâches de segmentation, il souffre toujours de mauvaises performances dans les tâches en aval. Nous étudions la capacité de généralisation du modèle Segment-Anything dans plusieurs tâches de segmentation d'images en aval et proposons une méthode d'auto-entraînement basée sur la régularisation des ancres et le réglage fin de bas rang. Cette méthode ne nécessite pas d'accès à l'ensemble de données source, a un faible coût en mémoire, est naturellement compatible avec une supervision faible et peut améliorer considérablement l'effet adaptatif. Après une vérification expérimentale approfondie, les résultats montrent que la méthode d'adaptation de domaine proposée peut améliorer considérablement la capacité de généralisation du SAM sous divers changements de distribution. 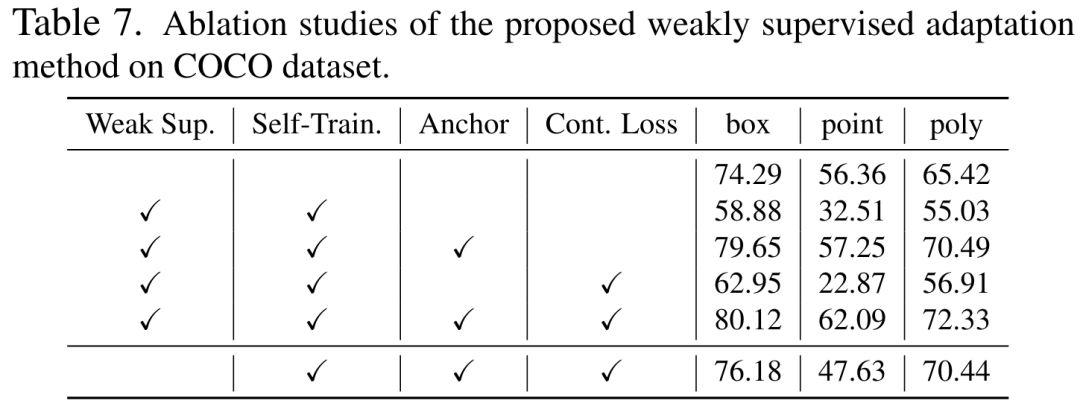
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!