
Maison >Périphériques technologiques >IA >Tongyi Qianwen dispose de 32 milliards de modèles de paramètres open source et a réalisé les 7 principaux modèles de langage en open source.
Tongyi Qianwen dispose de 32 milliards de modèles de paramètres open source et a réalisé les 7 principaux modèles de langage en open source.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-08 15:31:271094parcourir
Le 7 avril, Alibaba Cloud a informé Qianwen du modèle open source de 32 milliards de paramètres Qwen1.5-32B, qui peut maximiser l'équilibre entre performances, efficacité et utilisation de la mémoire, offrant aux entreprises et aux développeurs un choix de modèle plus rentable. À l'heure actuelle, Notification Qianwen a ouvert un total de 6 grands modèles linguistiques, et les téléchargements cumulés dans les communautés open source au pays et à l'étranger ont dépassé les 3 millions.
Question générale Qianwen a déjà développé des modèles de paramètres de 500 millions, 1,8 milliard, 4 milliards, 7 milliards, 14 milliards et 72 milliards, et tous ont été mis à niveau vers la version 1.5. Parmi eux, plusieurs modèles de petite taille peuvent être facilement déployés du côté de l'appareil, et le modèle à 72 milliards de paramètres offre des performances de pointe et a été répertorié à plusieurs reprises sur HuggingFace et d'autres listes de modèles. Le modèle open source de 32 milliards de paramètres atteindra un équilibre plus idéal entre performances, efficacité et utilisation de la mémoire. Par exemple, par rapport au modèle 14B, le 32B a des capacités plus fortes dans les scénarios d'agents, par rapport au 72B, le 32B a des coûts de raisonnement inférieurs ; L'équipe chargée des problèmes généraux espère que le modèle open source 32B pourra fournir de meilleures solutions pour les applications en aval.
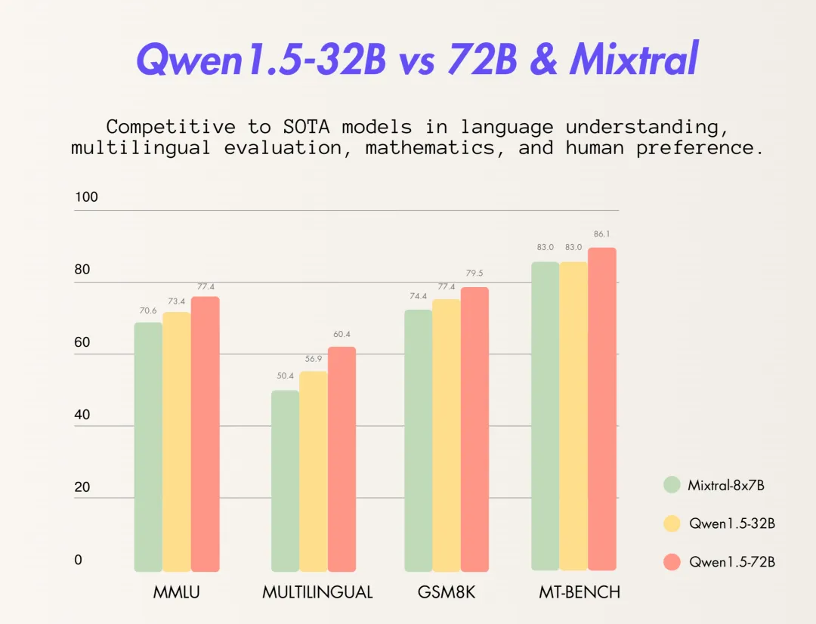
En termes de capacités de base, le modèle Qianwen à 32 milliards de paramètres a bien fonctionné dans plusieurs tests tels que MMLU, GSM8K, HumanEval, BBH, etc. Les performances sont proches du modèle Qianwen à 72 milliards de paramètres, dépassant de loin ses Modèle à 30 milliards de paramètres.
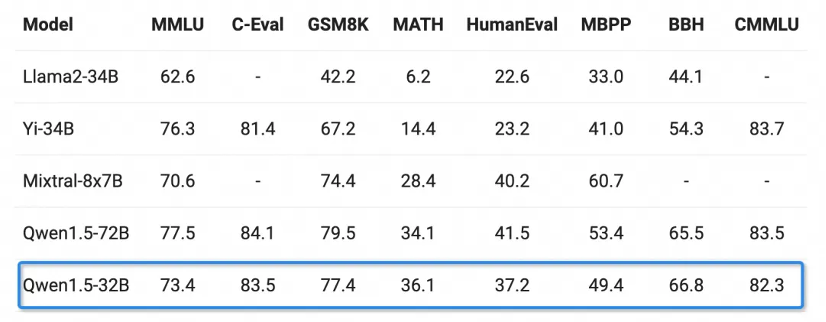
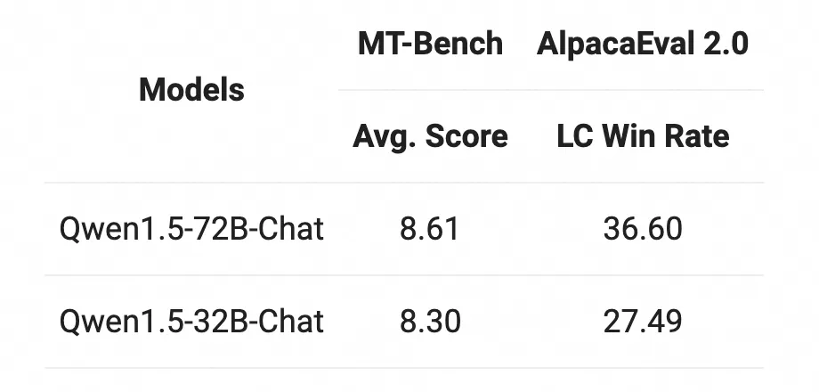
Quant au modèle Chat, le modèle Qwen1.5-32B-Chat a obtenu plus de 8 points dans l'évaluation MT-Bench, et l'écart avec le Qwen1.5-72B-Chat est relativement faible.
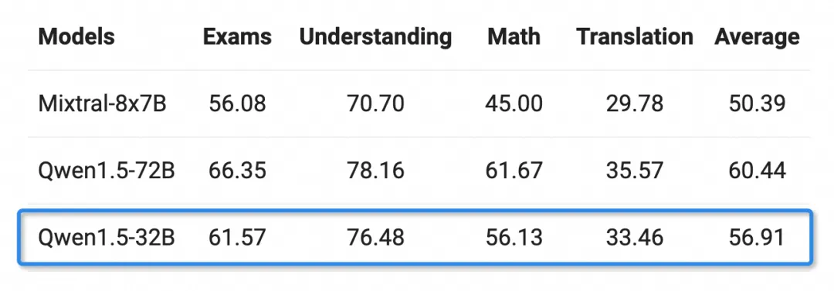
Les personnes ayant de riches compétences linguistiques peuvent le faire dans plusieurs domaines tels que les examens, la compréhension, les mathématiques et la traduction après avoir choisi 12 langues dont l'arabe, l'espagnol, le français, le japonais, le coréen, etc. La capacité multilingue de Qwen1.5-32B est limitée au modèle général de paramètres Qwen à 72 milliards.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Que dois-je faire si l'utilisation de la mémoire atteint 60 % lors du démarrage de Windows 10 ?
- Article vedette|La demande de puissance de calcul explose sous le boom des grands modèles d'IA : Lingang veut construire une industrie de plusieurs dizaines de milliards, et SenseTime sera le « maître de la chaîne »
- Les techniques d'optimisation de la mémoire C++ révélées : méthodes clés pour réduire l'utilisation de la mémoire
- Comment résoudre le problème de l'utilisation élevée de la mémoire dans Win10