
Maison >Périphériques technologiques >IA >Trop complet ! Une revue de l'apprentissage profond multimodal !
Trop complet ! Une revue de l'apprentissage profond multimodal !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-08 09:10:021090parcourir
1. Introduction
Notre expérience du monde est multimodale : nous voyons des objets, entendons des sons, ressentons des textures, sentons et goûtons. La modalité fait référence à la manière dont une certaine condition se produit ou est vécue, et lorsqu'une question de recherche contient plusieurs modalités, elle est qualifiée de multimodale. Pour que l’IA progresse dans la compréhension du monde qui nous entoure, elle doit être capable d’interpréter simultanément ces signaux multimodaux.
Par exemple, les images sont souvent associées à des balises et à des explications textuelles, et le texte contient des images pour exprimer plus clairement l'idée centrale de l'article. Différentes modalités ont des propriétés statistiques très différentes. Ces données sont appelées big data multimodales et contiennent de riches informations multimodales et intermodales, posant d'énormes défis aux méthodes traditionnelles de fusion de données.
Dans cette revue, nous présenterons des modèles d'apprentissage profond révolutionnaires pour fusionner ces big data multimodaux. Alors que le big data multimodal est de plus en plus exploré, certains défis doivent encore être relevés. Par conséquent, cet article propose une revue de l'apprentissage profond pour la fusion de données multimodales, dans le but de fournir aux lecteurs (quelle que soit leur communauté d'origine) les principes de base des méthodes de fusion d'apprentissage profond multimodal et d'inspirer de nouveaux types de données multimodales pour la technologie de fusion d'apprentissage profond.
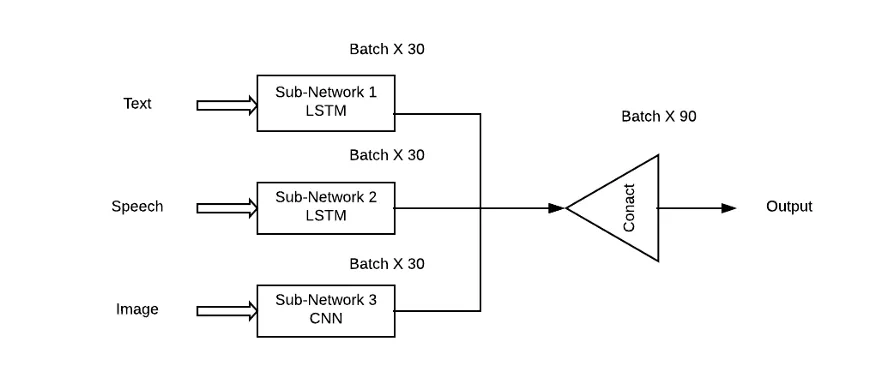
Le problème avec cette approche est qu'elle accordera la même importance à tous les sous-réseaux/modèles, ce qui est très improbable dans les situations du monde réel. Une combinaison pondérée de sous-réseaux doit être utilisée ici afin que chaque modalité d'entrée puisse avoir une contribution d'apprentissage (Thêta) à la prédiction de sortie. 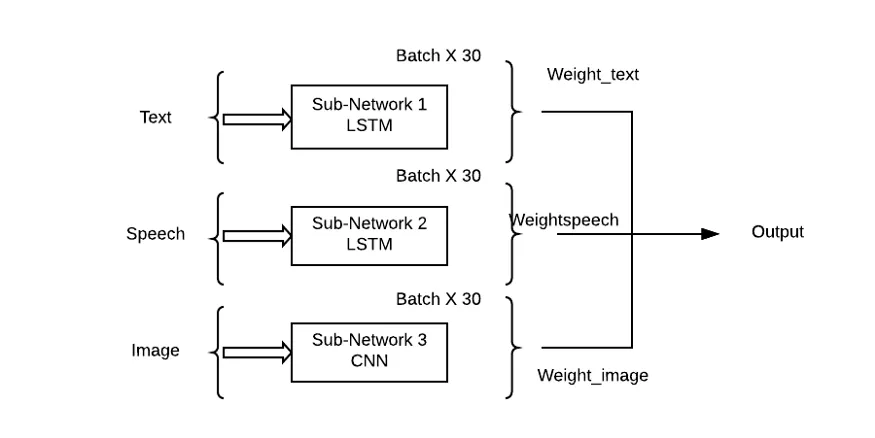
2. Architecture d'apprentissage profond représentative
Dans cette section, nous présenterons l'architecture d'apprentissage profond représentative du modèle d'apprentissage profond de fusion de données multimodales. Plus précisément, la définition de l'architecture profonde, du calcul rétroactif et du calcul de rétropropagation, ainsi que les variations typiques sont données. Les modèles représentatifs sont résumés.
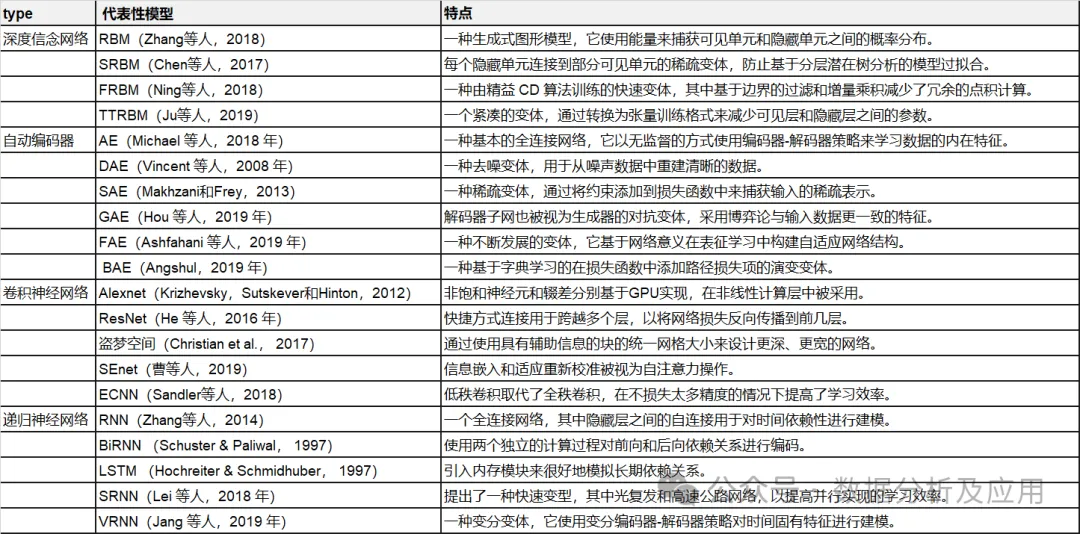
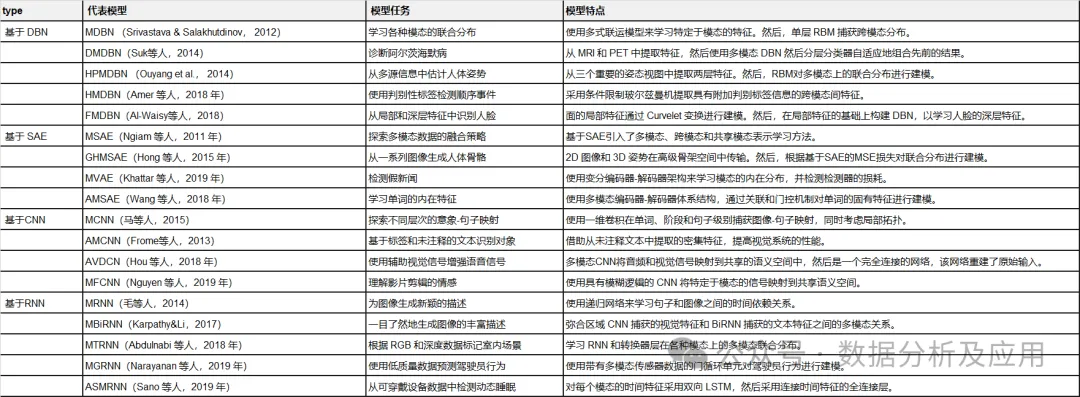
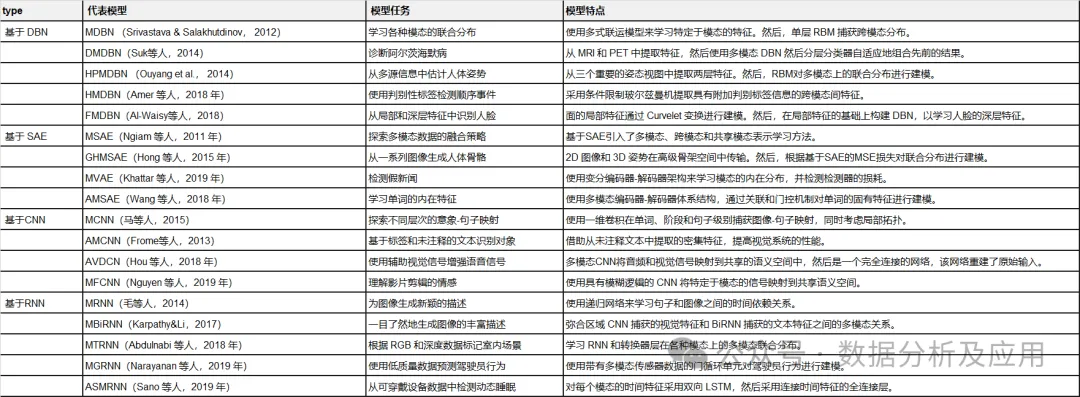
Tableau 1 : Résumé des modèles représentatifs de deep learning.
2.1 Réseau de croyance profonde (DBN)
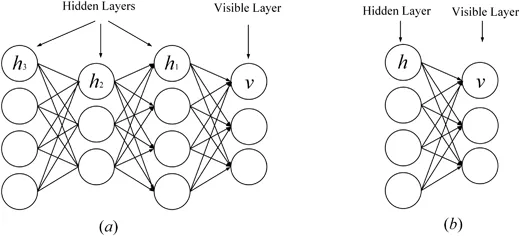
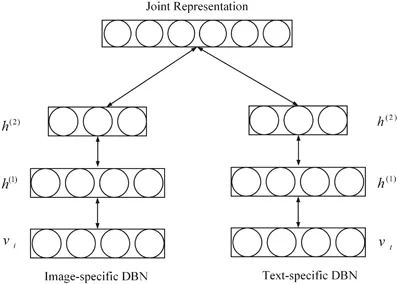
La machine Boltzmann restreinte (RBM) est le bloc de base du réseau de croyance profonde (Zhang, Ding, Zhang et Xue, 2018 ; Bengio, 2009). RBM est une variante spéciale de la machine de Boltzmann (voir Figure 1), qui se compose d'une couche visible et d'une couche cachée. Il existe une connexion complète entre la couche visible et la couche cachée, mais il n'y a aucune connexion entre les unités de la même ; couche. RBM est également un modèle génératif qui utilise une fonction énergétique pour capturer la distribution de probabilité entre les unités visibles et cachées. En utilisant la dérivée de la fonction énergétique, la distribution de probabilité des unités entre les unités visibles et cachées peut être calculée. RBM peut capturer la distribution de probabilité entre les éléments individuels et les unités cachées. Il n'y a pas de connexions entre les cellules dans RBM, sauf qu'il n'y a pas de connexions entre les cellules au sein de la même couche et que toutes les cellules sont connectées via des connexions complètes. RBM utilise également la fonction énergétique pour calculer la distribution de probabilité entre les unités visibles et cachées. En utilisant la fonction de probabilité de RBM, la distribution de probabilité entre les unités peut être capturée.
Récemment, certains RBM avancés ont été proposés pour améliorer les performances. Par exemple, pour éviter le surajustement du réseau, Chen, Zhang, Yeung et Chen (2017) ont conçu une machine Boltzmann clairsemée qui apprend la structure du réseau sur la base d'arbres latents hiérarchiques. Ning, Pittman et Shen (2018) ont introduit l'algorithme de divergence contrastive rapide dans RBM, où le filtrage basé sur les limites et le produit delta sont utilisés pour réduire les calculs de produits scalaires redondants dans le calcul. Pour protéger la structure interne des données multidimensionnelles, Ju et al. (2019) ont proposé le tenseur RBM pour apprendre les distributions de haut niveau cachées dans les données multidimensionnelles, où la décomposition tensorielle est utilisée pour éviter la malédiction de la dimensionnalité.
DBM est une architecture profonde typique, empilée par plusieurs RBM (Hinton & Salakhutdinov, 2006). Il s'agit d'un modèle génératif basé sur une stratégie de formation préalable et de mise au point qui peut exploiter l'énergie pour capturer la répartition des articulations entre les objets visibles et les étiquettes correspondantes. En pré-formation, chaque couche cachée est modélisée avec gourmandise comme un RBM formé à une politique non supervisée. Ensuite, chaque couche cachée est entraînée davantage grâce aux informations discriminantes des étiquettes de formation dans la stratégie supervisée. Les DBN ont été utilisés pour résoudre des problèmes dans de nombreux domaines, tels que la réduction de la dimensionnalité des données, l'apprentissage des représentations et le hachage sémantique. Un DBM représentatif est présenté dans la figure 1 .
Figure 1:
2.2 Autoencoder empilé (SAE)
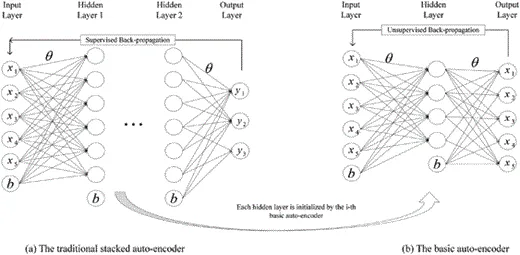
Stacké Autoencoder (SAE) est un modèle typique d'apprentissage en profondeur de l'architecture d'encodeur (Michael, Olivier et Mario, 2018; Weng , Lu, Tan et Zhou, 2016). Il peut capturer des caractéristiques concises de l'entrée en transformant l'entrée d'origine en une représentation intermédiaire de manière non supervisée-supervisée. SAE a été largement utilisé dans de nombreux domaines, notamment la réduction de dimensionnalité (Wang, Yao et Zhao, 2016), la reconnaissance d'images (Jia, Shao, Li, Zhao et Fu, 2018) et la classification de texte (Chen et Zaki, 2017). La figure 2 montre un SAE représentatif.
Figure 2 :
2.3 Réseau neuronal convolutif (CNN)
DBN et SAE sont des réseaux neuronaux entièrement connectés. Dans les deux réseaux, chaque neurone de la couche cachée est connecté à chaque neurone de la couche précédente, et cette topologie crée un grand nombre de connexions. Afin d'entraîner les poids de ces connexions, les réseaux de neurones entièrement connectés nécessitent un grand nombre d'objets d'entraînement pour éviter le surapprentissage et le sous-apprentissage, qui nécessitent beaucoup de calculs. De plus, la topologie entièrement connectée ne prend pas en compte les informations de position des caractéristiques contenues entre les neurones. Par conséquent, les réseaux de neurones profonds entièrement connectés (DBN, SAE et leurs variantes) ne peuvent pas gérer des données de grande dimension, en particulier des images volumineuses et des données audio volumineuses.
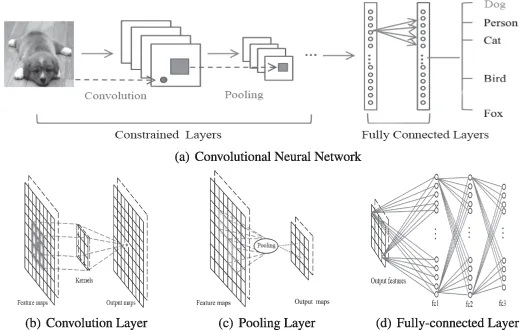
Le réseau neuronal convolutif est un réseau profond spécial qui prend en compte la topologie locale des données (Li, Xia, Du, Lin et Samat, 2017 ; Sze, Chen, Yang et Emer, 2017). Les réseaux de neurones convolutifs comprennent des réseaux entièrement connectés et des réseaux contraints contenant des couches convolutives et des couches de pooling. Les réseaux contraints utilisent des opérations de convolution et de pooling pour obtenir des champs récepteurs locaux et une réduction des paramètres. Comme DBN et SAE, les réseaux de neurones convolutifs sont formés via l'algorithme de descente de gradient stochastique. Elle a fait de grands progrès en reconnaissance d’images médicales (Maggiori, Tarabalka, Charpiat, & Alliez, 2017) et en analyse sémantique (Hu, Lu, Li, & Chen, 2014). Un CNN représentatif est illustré à la figure 3.
Figure 3 :
2.4 Réseau neuronal récurrent (RNN)
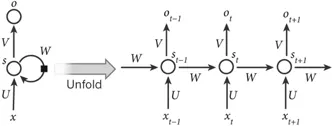
Le réseau neuronal récurrent est une architecture informatique neuronale qui traite des données en série (Martens et Sutskever, 2011 ; Sutskever, Martens et Hinton, 2011). Contrairement aux architectures profondes (c'est-à-dire DBN, SAE et CNN), elle mappe non seulement les modèles d'entrée aux résultats de sortie, mais transfère également les états cachés vers la sortie en exploitant les connexions entre les unités cachées (Graves & Schmidhuber, 2008). En utilisant ces connexions cachées, les RNN modélisent les dépendances temporelles, partageant ainsi les paramètres entre objets dans la dimension temporelle. Il a été appliqué dans divers domaines tels que l'analyse de la parole (Mulder, Bethard et Moens, 2015), le sous-titrage d'images (Xu et al., 2015) et la traduction linguistique (Graves & Jaitly, 2014), obtenant d'excellentes performances. Semblable à l’architecture deep forward, son calcul comprend également des étapes de passage direct et de rétropropagation. Dans le calcul de la passe directe, le RNN obtient simultanément les états d'entrée et caché. Dans le calcul de rétropropagation, il utilise l'algorithme de rétropropagation temporelle pour rétropropager la perte pour le pas de temps. La figure 4 montre un RNN représentatif.
Figure 4 :
3. Apprentissage profond pour la fusion de données multimodales
Dans cette section, nous passons en revue les dernières recherches du point de vue des tâches modèles, des cadres de modèles et des ensembles de données d'évaluation. modèle d'apprentissage profond de fusion de données multimodales. Ils sont divisés en quatre catégories en fonction de l’architecture d’apprentissage profond utilisée. Le tableau 2 résume les modèles représentatifs d’apprentissage profond multimodal.
Tableau 2 :
Résumé des modèles représentatifs d'apprentissage profond multimodal.
3.1 Fusion de données multimodales de croyance profonde basée sur un réseau
3.1.1 Exemple 1
Srivastava et Salakhutdinov (2012) ont proposé une fusion de données multimodale basée sur le modèle d'apprentissage profond de Boltzmann La modalité Le modèle de génération apprend les représentations multimodales en ajustant la distribution conjointe des données multimodales sur diverses modalités (telles que les images, le texte et l'audio).
Chaque module du DBN multimodal proposé est initialisé de manière couche par couche non supervisée, et une méthode d'approximation basée sur MCMC est utilisée pour la formation du modèle.
Afin d'évaluer la représentation multimodale apprise, un grand nombre de tâches sont effectuées, telles que la génération de tâches modales manquantes, la déduction de tâches de représentation conjointe et des tâches discriminantes. Les expériences vérifient si la représentation multimodale apprise satisfait aux propriétés requises.
3.1.2 Exemple 2
Pour diagnostiquer efficacement la maladie d'Alzheimer à un stade précoce, Suk, Lee, Shen et l'Alzheimer's Disease Neuroimaging Initiative (2014) ont proposé un modèle Erzmann multimodal en verre, qui peut fusionner des connaissances complémentaires dans les données multimodales. Plus précisément, pour remédier aux limitations causées par les méthodes d'apprentissage de fonctionnalités superficielles, DBN est utilisé pour apprendre des représentations approfondies de chaque modalité en transférant des représentations spécifiques à un domaine vers des représentations abstraites hiérarchiques. Ensuite, un RBM monocouche est construit sur des vecteurs concaténés, qui sont des combinaisons linéaires de représentations abstraites hiérarchiques de chaque modalité. Il est utilisé pour apprendre les représentations multimodales en construisant une distribution conjointe de différentes caractéristiques multimodales. Enfin, le modèle proposé est évalué de manière approfondie sur l'ensemble de données ADNI sur la base de trois diagnostics typiques, atteignant ainsi une précision diagnostique de pointe.
3.1.3 Exemple 3
Pour estimer avec précision la pose humaine, Ouyang, Chu et Wang (2014) ont conçu un modèle d'apprentissage profond multi-sources en extrayant la distribution conjointe des modèles corporels dans un espace d'ordre élevé, Apprenez les représentations multimodales à partir de types mélangés, de scores d’apparence et de modalités déformées. Dans le modèle profond multisource à pose humaine, trois modalités largement utilisées sont extraites de modèles de structure d'image qui combinent des parties du corps sur la base de la théorie des champs aléatoires conditionnels. Pour obtenir des données multimodales, le modèle de structure graphique est entraîné via une machine à vecteurs de support linéaire. Chacune des trois caractéristiques est ensuite introduite dans un modèle Boltzmann restreint à deux couches pour capturer une représentation abstraite de l'espace de pose d'ordre élevé à partir d'une représentation spécifique à une caractéristique. Grâce à une initialisation non supervisée, chaque modèle Boltzmann restreint spécifique à une modalité capture une représentation intrinsèque de l'espace global. Ensuite, RBM est utilisé pour apprendre davantage la représentation des poses humaines sur la base de vecteurs concaténés de types de mélange de haut niveau, de scores d'apparence et de représentations de déformation. Pour former le modèle d'apprentissage profond multi-source proposé, une fonction objective spécifique à une tâche prenant en compte à la fois la position du corps et la détection humaine est conçue. Le modèle proposé est validé sur LSP, PARSE et UIUC et produit des améliorations jusqu'à 8,6%.
Récemment, de nouveaux modèles d'apprentissage de fonctionnalités multimodaux basés sur DBN ont été proposés. Par exemple, Amer, Shields, Siddiquie et Tamrakar (2018) ont proposé une approche hybride pour la détection d'événements séquentiels, dans laquelle la RBM conditionnelle était utilisée pour extraire des caractéristiques modales et intermodales avec des informations d'étiquette discriminantes supplémentaires. Al-Waisy, Qahwaji, Ipson et Al-Fahdawi (2018) ont introduit une approche multimodale de la reconnaissance faciale. Dans cette approche, un modèle basé sur DBN est utilisé pour modéliser la distribution multimodale des caractéristiques artisanales locales capturées par la transformation Curvelet, qui peut fusionner les avantages des caractéristiques locales et des caractéristiques profondes (Al-Waisy et al., 2018).
3.1.4 Résumé
Ces modèles multimodaux basés sur DBN utilisent des réseaux de graphes probabilistes pour convertir des représentations spécifiques à une modalité en fonctionnalités sémantiques dans un espace partagé. Ensuite, la répartition conjointe sur les modalités est modélisée en fonction des caractéristiques de l'espace partagé. Ces modèles multimodaux basés sur DBN sont plus flexibles et robustes dans les stratégies d'apprentissage non supervisées, semi-supervisées et supervisées. Ils sont idéaux pour capturer les caractéristiques informatives des données d’entrée. Cependant, ils ignorent la topologie spatiale et temporelle des données multimodales.
3.2 Fusion de données multimodales basée sur des auto-encodeurs empilés
3.2.1 Exemple 4
Ngiam et al (2011) ont proposé un apprentissage profond multimodal basé sur des auto-encodeurs empilés (SAE) L'apprentissage profond le plus représentatif. modèle de fusion de données multimodales. Ce modèle d'apprentissage profond vise à résoudre deux problèmes de fusion de données : l'apprentissage de représentations multimodales et modales partagées. Le premier vise à exploiter les connaissances d'autres modalités pour capturer de meilleures représentations monomodales, tandis que le second apprend des corrélations complexes entre les modalités au niveau intermédiaire. Pour atteindre ces objectifs, trois scénarios d'apprentissage (apprentissage multimodal, intermodal et modal partagé) sont conçus, comme le montrent le tableau 3 et la figure 6.
Figure 6 :
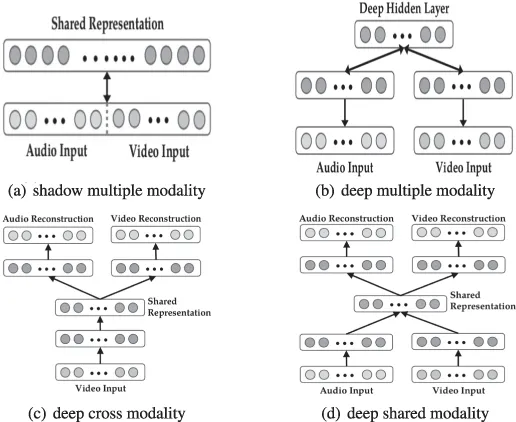 Architecture pour l'apprentissage multimodal, cross-modal et modal partagé.
Architecture pour l'apprentissage multimodal, cross-modal et modal partagé.
Tableau 3 : Paramètres pour l'apprentissage multimodal.
Dans les scénarios d'apprentissage multimodaux, les spectrogrammes audio et les images vidéo sont connectés en vecteurs de manière linéaire. Les vecteurs concaténés sont introduits dans une machine Boltzmann restreinte et sparse (SRBM) pour apprendre la corrélation entre l'audio et la vidéo. Ce modèle ne peut apprendre que des représentations conjointes fantômes de plusieurs modalités, car les corrélations sont implicites dans la représentation haute dimension du niveau d'origine et le SRBM monocouche ne peut pas les modéliser. Inspirés par cela, des vecteurs concaténés de représentations de niveau intermédiaire sont entrés dans SRBM pour modéliser la corrélation de plusieurs modalités, montrant ainsi de meilleures performances.
Dans le scénario d'apprentissage multimodal, un auto-encodeur multimodal profondément empilé est proposé pour apprendre explicitement la corrélation entre les modalités. Plus précisément, l'audio et la vidéo sont présentés comme entrées dans l'apprentissage des fonctionnalités, et un seul d'entre eux est entré dans le modèle lors de la formation et des tests supervisés. Le modèle est initialisé de manière multimodale et peut bien simuler des relations intermodales.
Dans la représentation modale partagée, motivée par le débruitage des auto-encodeurs, des auto-encodeurs multimodaux profondément empilés spécifiques à une modalité sont introduits pour explorer les représentations conjointes entre les modalités, en particulier lorsqu'un modal est manquant. L'ensemble de données de formation, élargi en remplaçant l'une des modalités par zéro, est introduit dans le modèle pour l'apprentissage des fonctionnalités.
Enfin, des expériences détaillées sont menées sur les ensembles de données CUAVE et AVLetters pour évaluer les performances de l'apprentissage profond multimodal dans l'apprentissage de fonctionnalités spécifiques à une tâche.
3.2.2 Exemple 5
Pour générer des squelettes humains visuellement et sémantiquement efficaces à partir d'une série d'images (notamment des vidéos), Hong, Yu, Wan, Tao et Wang (2015) ont proposé un auto-encodeur profond multimodal pour capturer la relation de fusion entre les images et les poses. En particulier, l'auto-encodeur profond multimodal proposé est entraîné via une stratégie en trois étapes pour construire un mappage non linéaire entre les images 2D et les poses 3D. Au cours de l'étape de fusion de caractéristiques, une représentation hypergraphique de bas rang multi-vues est exploitée pour construire une représentation 2D interne à partir d'une série de caractéristiques d'image (telles que des histogrammes à gradient orienté et un contexte de forme) basées sur un apprentissage multiple. Dans la deuxième étape, un auto-encodeur monocouche est entraîné pour apprendre une représentation abstraite utilisée pour récupérer la pose 3D en reconstruisant les caractéristiques inter-images 2D. Pendant ce temps, un auto-encodeur monocouche est entraîné de la même manière pour apprendre des représentations abstraites de poses 3D. Après avoir obtenu la représentation abstraite de chaque modalité, un réseau de neurones est utilisé pour apprendre la corrélation multimodale entre les images 2D et les poses 3D en minimisant la distance euclidienne au carré entre les deux représentations mutuelles modales. L'apprentissage de l'auto-encodeur profond multimodal proposé comprend des étapes d'initialisation et de réglage fin. Lors de l'initialisation, les paramètres de chaque sous-partie de l'auto-encodeur profond multimodal sont copiés à partir de l'auto-encodeur et du réseau neuronal correspondants. Ensuite, les paramètres de l’ensemble du modèle sont ensuite affinés grâce à un algorithme de descente de gradient stochastique pour construire une pose tridimensionnelle à partir de l’image bidimensionnelle correspondante.
3.2.3 Résumé
Le modèle multimodal basé sur SAE adopte une architecture encodeur-décodeur pour extraire les caractéristiques modales intrinsèques et les caractéristiques intermodales via des méthodes de reconstruction de manière non supervisée. Puisqu’ils sont basés sur SAE, qui est un modèle entièrement connecté, de nombreux paramètres doivent être entraînés. De plus, ils ignorent la topologie spatiale et temporelle des données multimodales.
3.3 Fusion de données multimodales basée sur un réseau de neurones convolutifs
3.3.1 Exemple 6
Afin de simuler la distribution du mappage sémantique entre des images et des phrases, Ma, Lu, Shang et Li (2015) proposé Un réseau neuronal convolutif multimodal. Afin de capturer pleinement la pertinence sémantique, une stratégie de fusion à trois niveaux (niveau mot, niveau étape et niveau phrase) est conçue dans l'architecture de bout en bout. L'architecture se compose d'un sous-réseau d'imagerie, d'un sous-réseau correspondant et d'un sous-réseau multimodal. Le sous-réseau d'image est un réseau neuronal convolutif profond représentatif tel qu'Alexnet et Inception, qui code efficacement les entrées d'image dans des représentations concises. Le sous-réseau de correspondance modélise une représentation conjointe qui associe le contenu d'une image à des fragments de mots de phrases dans l'espace sémantique.
3.3.2 Exemple 7
Pour étendre le système de reconnaissance visuelle à un nombre illimité de catégories discrètes, Frome et al (2013) ont proposé un réseau neuronal convolutif multimodal en exploitant les informations sémantiques contenues dans les données textuelles. . réseau. Le réseau se compose d'un sous-modèle linguistique et d'un sous-modèle visuel. Le sous-modèle linguistique est basé sur le modèle skip-gram, qui peut transférer des informations textuelles dans une représentation dense de l'espace sémantique. Le sous-modèle visuel est un réseau neuronal convolutif représentatif tel qu'Alexnet, qui est pré-entraîné sur l'ensemble de données ImageNet de 1 000 classes pour capturer les caractéristiques visuelles. Pour modéliser la relation sémantique entre les images et le texte, les sous-modèles linguistiques et visuels sont combinés via des couches de projection linéaire. Chaque sous-modèle est initialisé avec des paramètres pour chaque modalité. Ensuite, pour entraîner ce modèle multimodal visuel-sémantique, une nouvelle fonction de perte est proposée, capable de fournir des scores de similarité élevés pour les paires d'images et d'étiquettes correctes en combinant la similarité du produit scalaire et la perte de rang charnière. Le modèle produit des performances de pointe sur l'ensemble de données ImageNet, évitant ainsi des résultats sémantiquement déraisonnables.
3.3.3 Résumé
Les modèles multimodaux basés sur CNN peuvent apprendre des fonctionnalités multimodales locales entre les modalités via des champs locaux et des opérations de mutualisation. Ils modélisent explicitement la topologie spatiale des données multimodales. Et ce ne sont pas des modèles entièrement connectés avec un nombre de paramètres très réduit.
3.4 Fusion de données multimodales basée sur un réseau neuronal récurrent
3.4.1 Exemple 8
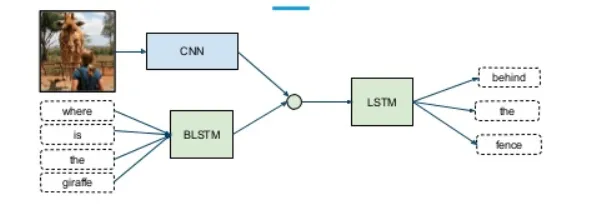
Pour générer des légendes pour les images, Mao et al (2014) ont proposé une architecture neuronale récurrente multimodale . Ce réseau neuronal récurrent multimodal peut établir des corrélations probabilistes entre des images et des phrases. Il aborde la limitation des travaux antérieurs qui ne peuvent pas générer de nouvelles légendes d'images car ils récupèrent les légendes correspondantes dans une base de données de phrases basée sur des mappages image-texte appris. Contrairement aux travaux antérieurs, les modèles neuronaux récurrents multimodaux (MRNN) apprennent des distributions conjointes sur l'espace sémantique à partir de mots et d'images. Lorsqu'une image est présentée, elle génère des phrases textuelles basées sur la distribution conjointe capturée. Plus précisément, le réseau neuronal récurrent multimodal se compose d'un sous-réseau linguistique, d'un sous-réseau visuel et d'un sous-réseau multimodal, comme le montre la figure 7. Le sous-réseau linguistique se compose d'une partie d'intégration de mots à deux couches qui capture des représentations efficaces spécifiques à une tâche et d'une partie neuronale récurrente à une seule couche qui modélise la dépendance temporelle des phrases. Le sous-réseau de vision est essentiellement un réseau neuronal convolutionnel profond, tel qu'Alexnet, Resnet ou Inception, qui code des images de grande dimension en représentations compactes. Enfin, le sous-réseau multimodal est un réseau caché qui modélise la distribution sémantique conjointe du langage appris et des représentations visuelles.
Figure 7 :
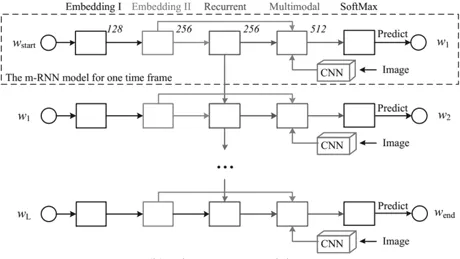
3.4.2 Exemple 9
Afin de résoudre la limitation des systèmes de reconnaissance visuelle actuels qui ne peuvent pas générer de riches descriptions d'images en un seul coup d'œil, nous avons proposé un modèle par reliant le modèle entre les données visuelles et textuelles. La relation entre les états, un modèle d'alignement multimodal est proposé (Karpathy & Li, 2017). Pour y parvenir, un double schéma a été proposé. Premièrement, un modèle d'intégration sémantique visuelle est conçu pour générer des ensembles de données de formation multimodaux. Un RNN multimodal est ensuite formé sur cet ensemble de données pour générer de riches descriptions d'images.
Dans le modèle d'intégration sémantique visuelle, des réseaux de neurones convolutifs régionaux sont utilisés pour obtenir des représentations d'images riches contenant suffisamment d'informations pour le contenu correspondant aux phrases. Un RNN bidirectionnel est ensuite utilisé pour coder chaque phrase dans un vecteur dense de mêmes dimensions que la représentation de l'image. De plus, une fonction de notation multimodale est présentée pour mesurer la similarité sémantique entre les images et les phrases. Enfin, la méthode des champs aléatoires de Markov est utilisée pour générer des ensembles de données multimodales.
Dans le RNN multimodal, un modèle étendu plus efficace basé sur le contenu du texte et la saisie d'images est proposé. Le modèle multimodal se compose d'un réseau neuronal convolutif qui code les entrées d'image et d'un RNN qui code les caractéristiques de l'image et les phrases. Le modèle est également entraîné via l'algorithme de descente de gradient stochastique. Les deux modèles multimodaux sont évalués de manière approfondie sur les ensembles de données Flickr et Mscoco et atteignent des performances de pointe.
3.4.3 Résumé
Le modèle multimodal basé sur RNN peut analyser la dépendance temporelle cachée dans les données multimodales à l'aide d'un transfert d'état explicite dans le calcul d'unités cachées. Ils utilisent un algorithme de rétropropagation temporelle pour entraîner les paramètres. Étant donné que le calcul est effectué dans des transferts d’états cachés, il est difficile de le paralléliser sur des appareils hautes performances.
4. Résumé et perspectives
Nous résumons le modèle en quatre groupes de modèles d'apprentissage en profondeur de données multimodales basés sur DBN, SAE, CNN et RNN. Ces modèles pionniers ont déjà permis des progrès. Cependant, ces modèles en sont encore à leurs stades préliminaires, de sorte que des défis subsistent.
Tout d'abord, il existe un grand nombre de poids libres dans le modèle d'apprentissage profond de fusion de données multimodales, notamment des paramètres redondants qui ont peu d'impact sur la tâche cible. Afin d'entraîner ces paramètres qui capturent la structure caractéristique des données, une grande quantité de données est entrée dans un modèle d'apprentissage profond multimodal de fusion de données basé sur l'algorithme de rétropropagation, qui nécessite beaucoup de temps et de calculs. Par conséquent, la manière de concevoir de nouvelles méthodes de compression multimodales d’apprentissage profond combinées aux stratégies de compression existantes constitue également une direction de recherche potentielle.
Deuxièmement, les données multimodales contiennent non seulement des informations intermodales, mais contiennent également de riches informations intermodales. Par conséquent, la combinaison de stratégies d’apprentissage profond et de fusion sémantique peut être un moyen de relever les défis posés par l’exploration des données multimodales. Troisièmement, des données multimodales sont collectées à partir d'environnements dynamiques, ce qui montre que les données sont incertaines. Par conséquent, avec la croissance explosive des données multimodales dynamiques, le problème de conception de modèles d’apprentissage profond multimodaux en ligne et incrémentiels pour la fusion de données doit être résolu.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Un petit apprentissage automatique promet d'intégrer l'apprentissage profond dans les microprocesseurs
- La bonne façon de jouer à l'apprentissage profond par blocs de construction ! L'Université nationale de Singapour lance DeRy, un nouveau paradigme d'apprentissage par transfert qui transforme le transfert de connaissances en impression à caractères mobiles
- comment réparer LSP
- Qu'est-ce qu'un masque de sous-réseau ?