
Maison >Périphériques technologiques >IA >Explication détaillée de GQA, le mécanisme d'attention couramment utilisé dans les grands modèles, et l'implémentation du code Pytorch
Explication détaillée de GQA, le mécanisme d'attention couramment utilisé dans les grands modèles, et l'implémentation du code Pytorch

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-03 17:40:091303parcourir
Grouped Query Attention est une méthode d'attention multi-requêtes dans les grands modèles de langage. Son objectif est d'atteindre la qualité du MHA tout en maintenant la vitesse du MQA. L'attention des requêtes groupées regroupe les requêtes afin que les requêtes au sein de chaque groupe partagent le même poids d'attention, ce qui permet de réduire la complexité de calcul et d'augmenter la vitesse d'inférence.
Dans cet article, nous expliquerons l'idée de GQA et comment la traduire en code.
GQA a été proposé dans l'article GQA : Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. C'est une idée assez simple et propre, et repose sur une attention multi-têtes.
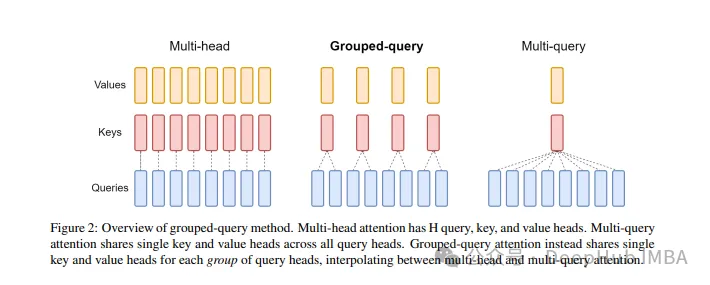
GQA
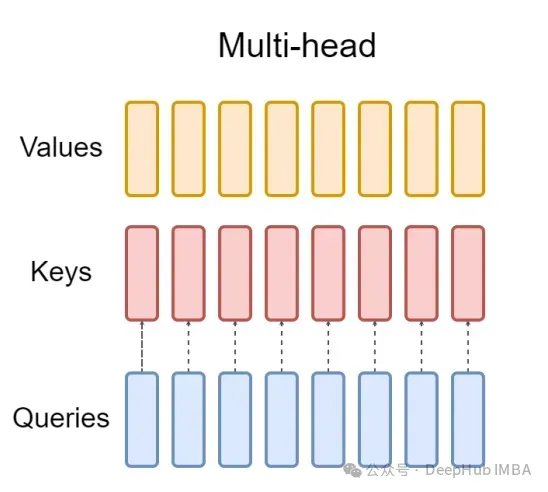
La couche d'attention multi-têtes (MHA) standard se compose d'en-têtes de requête H, d'en-têtes de clé et d'en-têtes de valeur. Chaque tête a des dimensions D. Le code Pytorch est le suivant :
from torch.nn.functional import scaled_dot_product_attention # shapes: (batch_size, seq_len, num_heads, head_dim) query = torch.randn(1, 256, 8, 64) key = torch.randn(1, 256, 8, 64) value = torch.randn(1, 256, 8, 64) output = scaled_dot_product_attention(query, key, value) print(output.shape) # torch.Size([1, 256, 8, 64])
Pour chaque en-tête de requête, il existe une clé correspondante. Ce processus est illustré dans la figure ci-dessous :
Et GQA divise l'en-tête de requête en groupes G, chaque groupe partage une clé et une valeur. Cela peut s'exprimer ainsi :
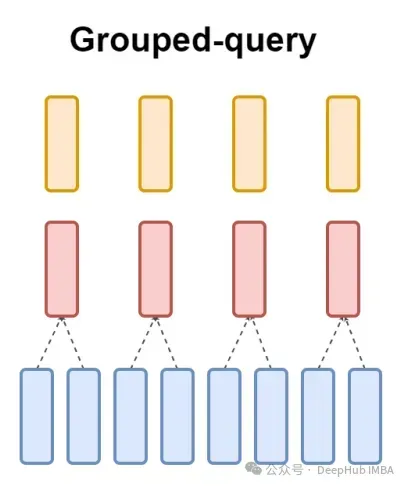
En utilisant des expressions visuelles, vous pouvez clairement comprendre le principe de fonctionnement de GQA, tout comme ce que nous avons dit ci-dessus. GQA est une idée assez simple et propre.
Implémentation du code Pytorch
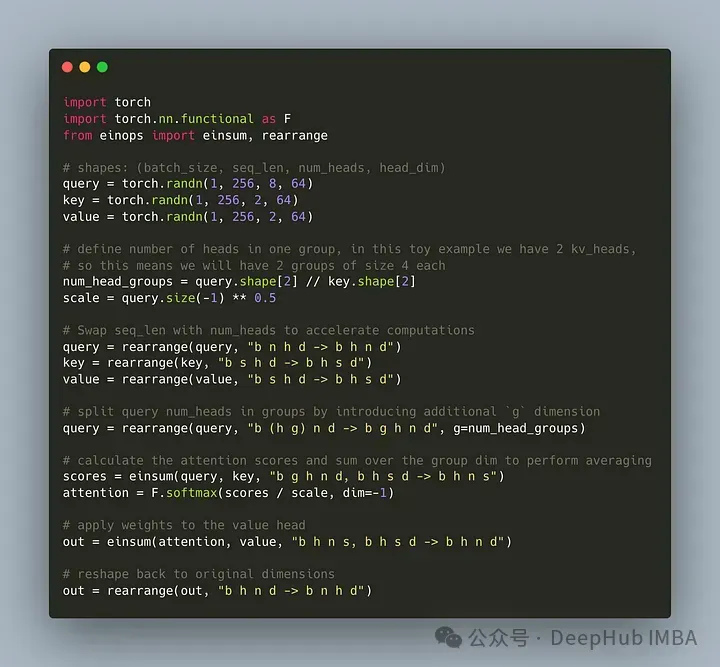
Écrivons le code pour diviser l'en-tête de requête en groupes G, chaque groupe partageant une clé et une valeur. Nous pouvons utiliser la bibliothèque einops pour effectuer efficacement des opérations complexes sur les tenseurs.
Tout d'abord, définissez la requête, les clés et les valeurs. Définissez ensuite le nombre de têtes d'attention. Le nombre est arbitraire, mais il faut s'assurer que num_heads_for_query % num_heads_for_key = 0, ce qui signifie qu'il doit être divisible. Notre définition est la suivante :
import torch # shapes: (batch_size, seq_len, num_heads, head_dim) query = torch.randn(1, 256, 8, 64) key = torch.randn(1, 256, 2, 64) value = torch.randn(1, 256, 2, 64) num_head_groups = query.shape[2] // key.shape[2] print(num_head_groups) # each group is of size 4 since there are 2 kv_heads
Afin d'améliorer l'efficacité, échanger les dimensions seq_len et num_heads, einops peut être simplement complété comme suit :
from einops import rearrange query = rearrange(query, "b n h d -> b h n d") key = rearrange(key, "b s h d -> b h s d") value = rearrange(value, "b s h d -> b h s d")
Ensuite, nous devons introduire le "regroupement" dans le concept de matrice de requête.
from einops import rearrange query = rearrange(query, "b (h g) n d -> b g h n d", g=num_head_groups) print(query.shape) # torch.Size([1, 4, 2, 256, 64])
Avec le code ci-dessus nous remodelons la 2D en 2D : Pour le tenseur que nous avons défini, la dimension d'origine 8 (le nombre de têtes dans la requête) est maintenant divisée en deux groupes (pour correspondre aux têtes dans les clés et nombre de valeurs), chaque taille de groupe est de 4.
La dernière et la plus difficile partie consiste à calculer le score d'attention. Mais en fait, cela peut être fait en une seule ligne grâce à l'opération insum. Le tenseur
from einops import einsum, rearrange # g stands for the number of groups # h stands for the hidden dim # n and s are equal and stands for sequence length scores = einsum(query, key, "b g h n d, b h s d -> b h n s") print(scores.shape) # torch.Size([1, 2, 256, 256])
scores a la même forme que le tenseur de valeur ci-dessus. Voyons comment cela fonctionne
einsum fait deux choses pour nous :
1 Une requête et une multiplication matricielle de clés. Dans notre cas, les formes de ces tenseurs sont (1,4,2,256,64) et (1,2,256,64), donc la multiplication matricielle selon les deux dernières dimensions nous donne (1,4,2,256,256).
2. Additionnez les éléments dans la deuxième dimension (dimension g) - si la dimension est omise dans la forme de sortie spécifiée, einsum terminera automatiquement ce travail, et une telle sommation est utilisée pour faire correspondre les clés et le nombre de têtes dans la valeur.
Enfin, notez la multiplication standard des fractions et des valeurs :
import torch.nn.functional as F scale = query.size(-1) ** 0.5 attention = F.softmax(similarity / scale, dim=-1) # here we do just a standard matrix multiplication out = einsum(attention, value, "b h n s, b h s d -> b h n d") # finally, just reshape back to the (batch_size, seq_len, num_kv_heads, hidden_dim) out = rearrange(out, "b h n d -> b n h d") print(out.shape) # torch.Size([1, 256, 2, 64])
L'implémentation GQA la plus simple est maintenant terminée, nécessitant moins de 16 lignes de code python :
Enfin, une brève mention de MQA : Multi-Query Attention (MQA) est une autre méthode populaire pour simplifier MHA. Toutes les requêtes partageront les mêmes clés et valeurs. Le diagramme schématique est le suivant :
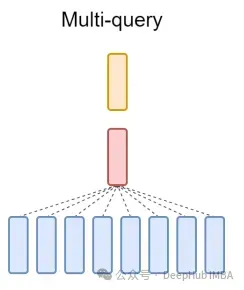
Comme vous pouvez le voir, MQA et MHA peuvent être dérivés de GQA. GQA avec une seule clé et valeur est équivalent à MQA, tandis que GQA avec des groupes égaux au nombre d'en-têtes est équivalent à MHA.
Quels sont les avantages du GQA
Le GQA est un bon compromis entre les meilleures performances (MQA) et la meilleure qualité de modèle (MHA).
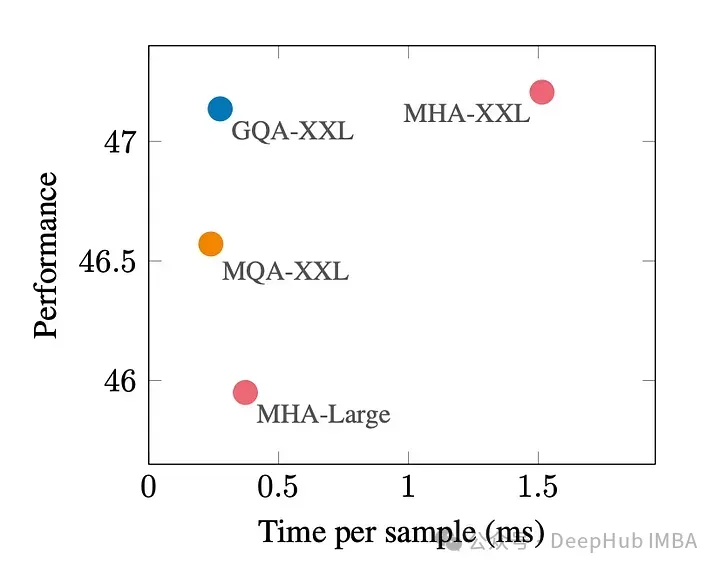
La figure ci-dessous montre qu'en utilisant GQA, vous pouvez obtenir presque la même qualité de modèle que MHA, tout en augmentant le temps de traitement de 3 fois, atteignant les performances de MQA. Cela peut être essentiel pour les systèmes à charge élevée.
Il n'y a pas d'implémentation officielle de GQA dans pytorch. J'ai donc trouvé une meilleure implémentation non officielle. Si vous êtes intéressé, vous pouvez l'essayer :
https://www.php.cn/link/5b52e27a9d5bf294f5b593c4c071500e
GQA paper :
https https://www.php.cn/link/e4ba31fba036a999321d5460f7f2d1d1
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!