
Maison >Périphériques technologiques >IA >Le modèle de diffusion surmonte les problèmes algorithmiques, l'AGI n'est pas loin ! Google Brain trouve le chemin le plus court dans un labyrinthe
Le modèle de diffusion surmonte les problèmes algorithmiques, l'AGI n'est pas loin ! Google Brain trouve le chemin le plus court dans un labyrinthe

- PHPzavant
- 2024-04-02 17:40:261385parcourir
Le « modèle de diffusion » peut-il également surmonter les problèmes algorithmiques ?
 Photos
Photos
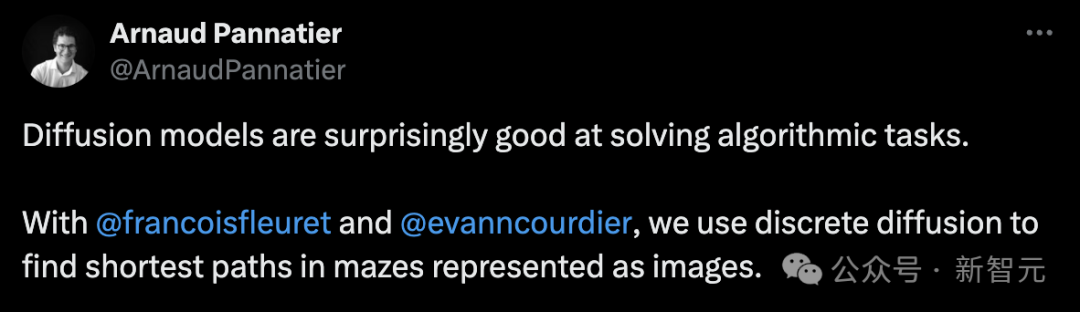
Un chercheur doctorant a réalisé une expérience intéressante, en utilisant la "diffusion discrète" pour trouver le chemin le plus court dans un labyrinthe représenté par une image.
 Images
Images
Selon l'auteur, chaque labyrinthe est généré en ajoutant à plusieurs reprises des murs horizontaux et verticaux.
Parmi eux, le point de départ et le point cible sont choisis au hasard.
Échantillonnez au hasard un chemin comme solution depuis le chemin le plus court du point de départ au point cible. Le chemin le plus court est calculé à l'aide d'un algorithme exact.
 Images
Images
Ensuite, utilisez le modèle de diffusion discrète et U-Net.
Le point de départ et le labyrinthe cible sont codés dans un canal, et le modèle utilise la solution dans un autre canal pour éliminer le bruit du labyrinthe.
 Photos
Photos
Même si le labyrinthe est un peu plus difficile, vous pouvez toujours bien le faire.
 Photos
Photos
Pour estimer l'étape de débruitage p(x_{t-1} | x_t), l'algorithme estime p(x_0 | x_t). La visualisation de cette estimation (rangée du bas) au cours du processus montre les « hypothèses actuelles » et se concentre finalement sur les résultats.
 Photos
Photos
Jim Fan, scientifique principal chez NVIDIA, a déclaré qu'il s'agissait d'une expérience intéressante et que le modèle de diffusion peut « restituer » l'algorithme. Il peut implémenter une traversée de labyrinthe à partir de pixels uniquement, même en utilisant U-Net, qui est beaucoup plus faible que Transforme.
J'ai toujours pensé que le modèle de diffusion est le moteur de rendu et que le Transformer est le moteur d'inférence. Il semble que le moteur de rendu lui-même puisse également coder des algorithmes séquentiels très complexes.
 Photo
Photo
Cette expérience a tout simplement choqué les internautes : "Que peut faire d'autre le modèle de diffusion ?!" En entraînant le transformateur de diffusion, AGI résoudra le problème.
 Photos
Photos
Cependant, cette étude n'a pas encore été officiellement publiée et l'auteur a déclaré qu'elle serait mise à jour sur arxiv ultérieurement.
 Il est à noter que dans cette expérience, ils ont utilisé le modèle de diffusion discrète proposé par l'équipe Google Brain en 2021.
Il est à noter que dans cette expérience, ils ont utilisé le modèle de diffusion discrète proposé par l'équipe Google Brain en 2021.
Photos
Tout récemment, cette étude a été mise à jour pour une nouvelle édition.
 Modèle de diffusion discrète
Modèle de diffusion discrète
Le "modèle génératif" est le problème central de l'apprentissage automatique.
Il peut être utilisé à la fois pour mesurer notre capacité à capturer des statistiques sur des ensembles de données naturelles et pour des applications en aval qui doivent générer des données de grande dimension telles que des images, du texte et de la parole.
GAN, VAE, grands modèles de réseaux neuronaux autorégressifs, flux normalisé et autres méthodes ont leurs propres avantages en termes de qualité des échantillons, de vitesse d'échantillonnage, de probabilité de journalisation et de stabilité de l'entraînement.
Récemment, le « modèle de diffusion » est devenu l'alternative la plus populaire pour la génération d'images et d'audio.
Il peut atteindre une qualité d'échantillon comparable au GAN et une log-vraisemblance comparable aux modèles autorégressifs avec moins d'étapes d'inférence. Bien que certaines personnes aient proposé des modèles de diffusion d'espaces d'états discrets et continus, les recherches récentes se sont principalement concentrées sur sur Processus de diffusion gaussienne opérant dans un espace d'état continu (tels que des images à valeur réelle et des données de forme d'onde).
 Le modèle de diffusion de l'espace d'états discrets a été exploré dans les domaines de la segmentation de texte et d'images, mais ne s'est pas révélé être un modèle compétitif dans les tâches de génération à grande échelle de texte et d'images.
Le modèle de diffusion de l'espace d'états discrets a été exploré dans les domaines de la segmentation de texte et d'images, mais ne s'est pas révélé être un modèle compétitif dans les tâches de génération à grande échelle de texte et d'images.
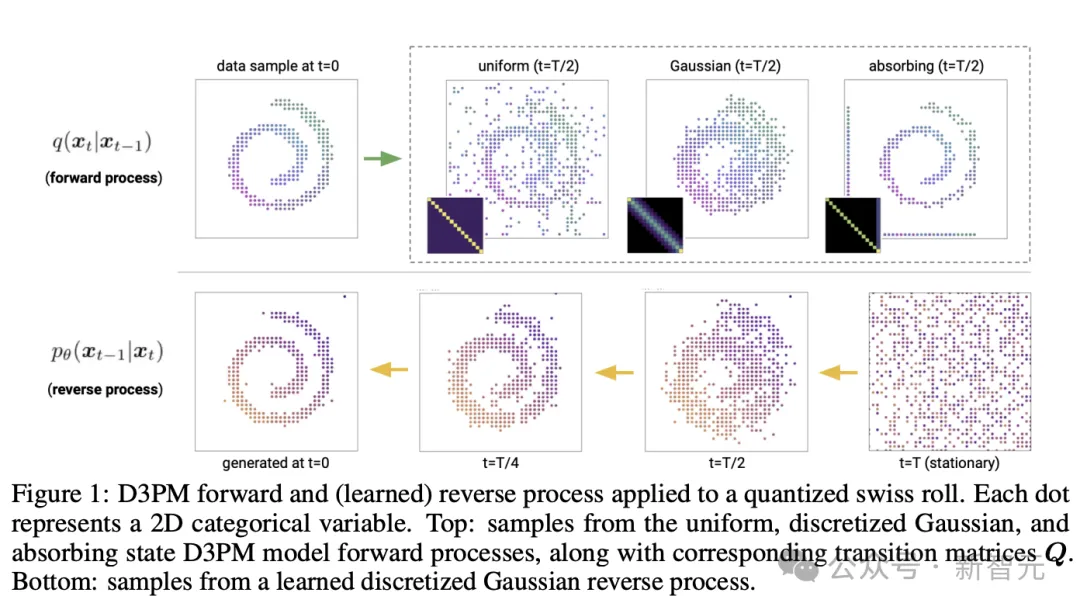
L'équipe de recherche de Google a proposé un nouveau modèle de probabilité de diffusion de débruitage discret (D3PM).
Dans l'étude, les auteurs ont démontré que le choix de la matrice de transition est une décision de conception importante qui peut améliorer les résultats dans les domaines de l'image et du texte.
De plus, ils ont proposé une nouvelle fonction de perte qui combine une limite inférieure variationnelle et une perte d'entropie croisée auxiliaire.
En termes de texte, ce modèle obtient de bons résultats dans la génération de texte au niveau des caractères tout en étant évolutif au grand ensemble de données de vocabulaire LM1B.
Sur l'ensemble de données d'images CIFAR-10, le dernier modèle se rapproche de la qualité de l'échantillon du modèle DDPM en espace continu et dépasse la log-vraisemblance du modèle DDPM en espace continu.
Photos
Auteur du projet
Arnaud Pannatier
Arnaud Pannatier de mars 2020 sous la direction de François Fleuret Le groupe machine learning commence un doctorat.
Il a récemment développé HyperMixer, en utilisant un super réseau pour permettre à MLPMixer de gérer des entrées de différentes longueurs. Cela permet au modèle de traiter l'entrée d'une manière invariante par permutation et il a été démontré que cela donne au modèle un comportement attentionnel qui évolue linéairement avec la longueur de l'entrée.
À l'EPFL, il a obtenu un baccalauréat en physique et un master en informatique et ingénierie (CSE-MASH).
Références :
https://www.php.cn/link/46994a3cd8d943d03b44b8fc9792d435
https://www.php.cn/link/1879 d84e181b6262704e95372dc9f4dc
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication détaillée de l'utilisation de StringAndDate en python
- Introduction à l'utilisation de la fonction php get_magic_quotes_gpc()
- Le nouveau produit des Red Devils : le chargeur GaN polyvalent de 150 W « Deuterium Front » sera financé par un financement participatif le 8 août !
- Honor Magic 6 Ultimate Edition dévoilé - L'appareil photo principal de 50 mégapixels + l'objectif périscope de 200 mégapixels brille