
Maison >Périphériques technologiques >IA >Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA
Le document multimodal Alibaba 7B comprenant le grand modèle remporte le nouveau SOTA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-02 11:31:27974parcourir
Compréhension de documents multimodauxCapacité nouveau SOTA !
L'équipe Alibaba mPLUG a publié le dernier travail open source mPLUG-DocOwl 1.5, qui propose une série de solutions pour les quatre défis majeurs que sont la reconnaissance de texte d'image haute résolution, la compréhension universelle de la structure des documents, le suivi des instructions et l'introduction de connaissances externes. .
Sans plus tarder, regardons d’abord les effets.
Reconnaissance et conversion en un clic de graphiques aux structures complexes au format Markdown :
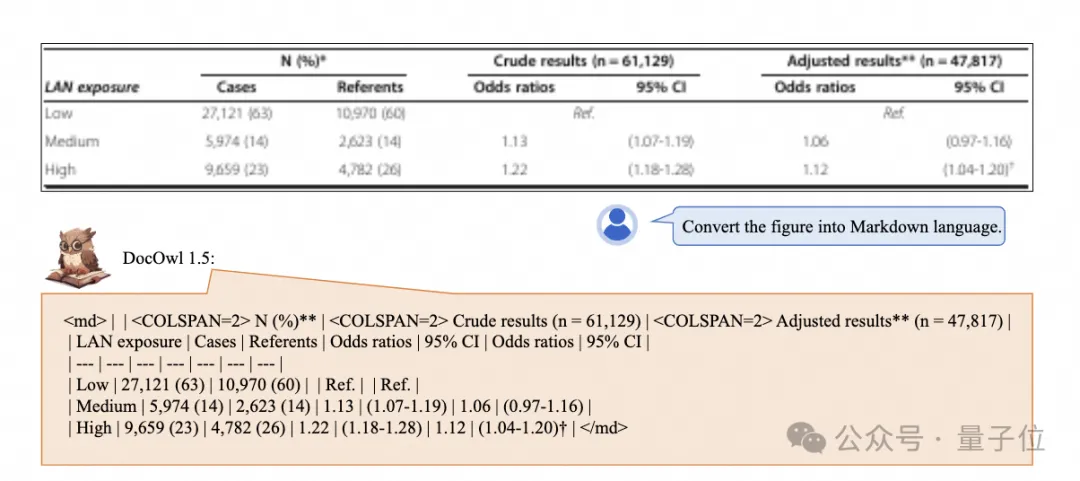
Des graphiques de différents styles sont disponibles :
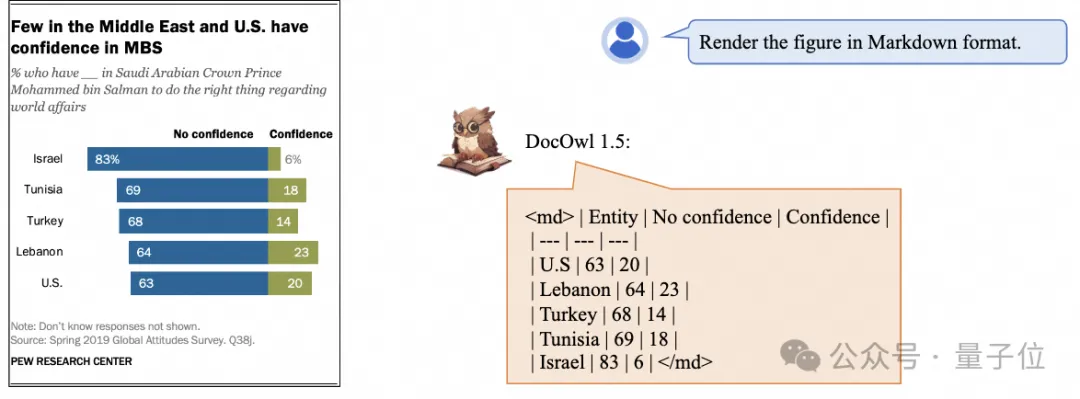
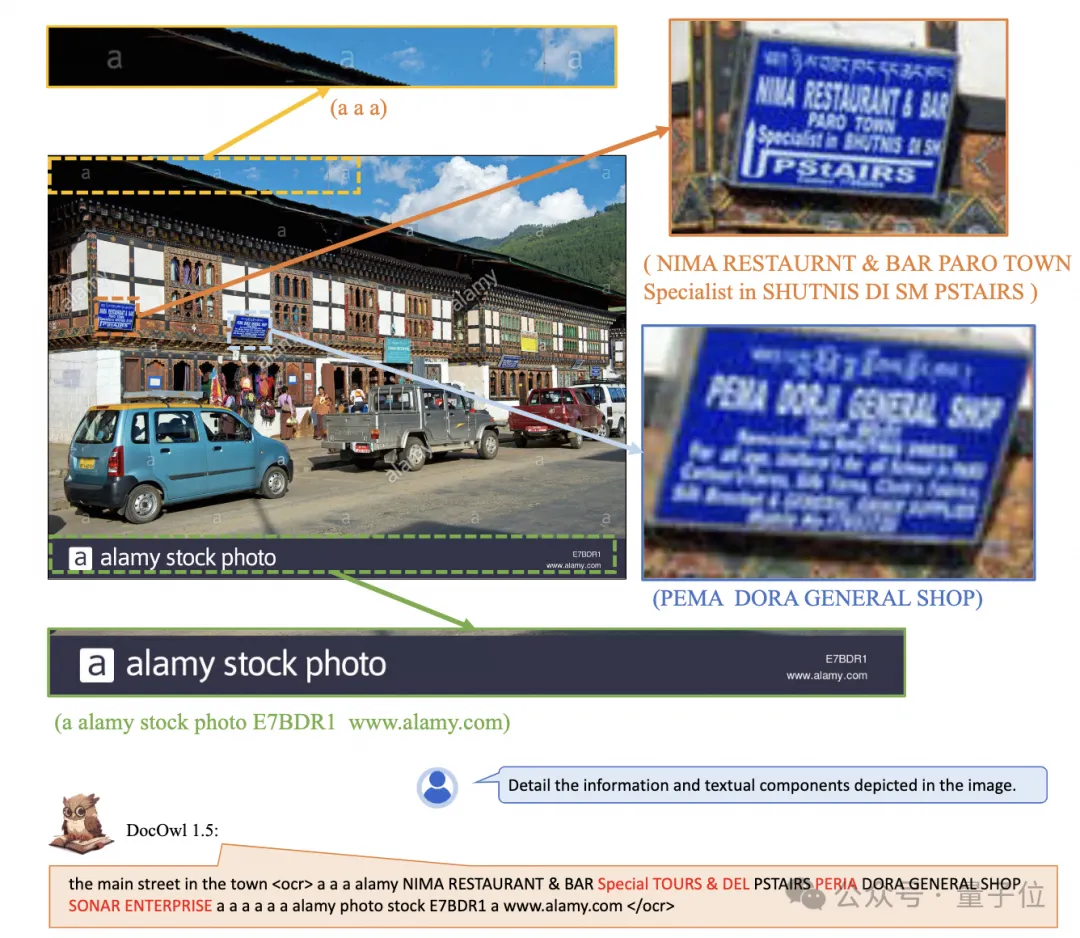
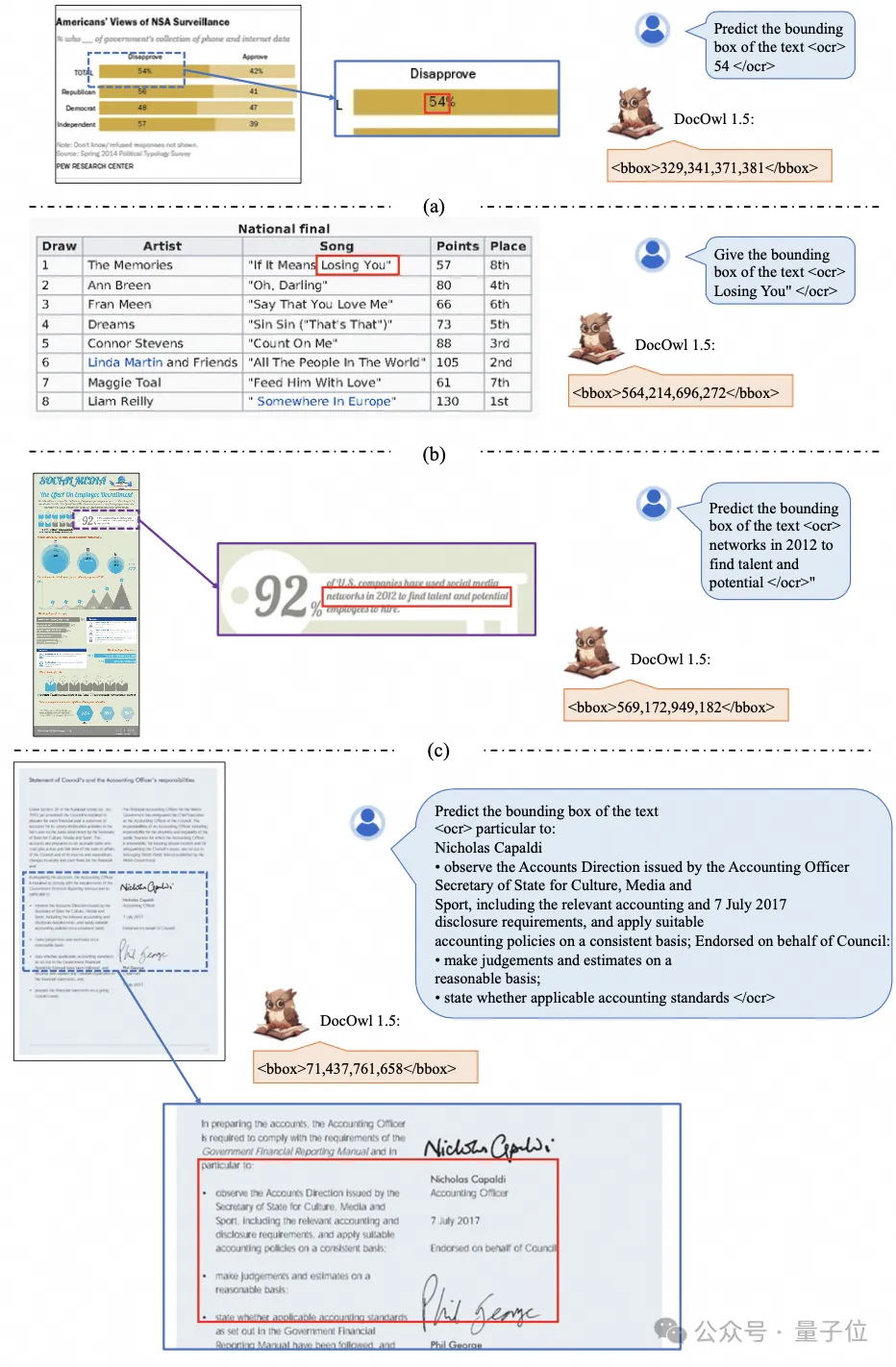
Une reconnaissance et un positionnement de texte plus détaillés peuvent également être facilement gérés :

Donnez également une explication détaillée de la compréhension des documents :

Vous devez savoir que la « compréhension des documents » est actuellement un scénario important pour la mise en œuvre de grands modèles de langage. Il existe de nombreux produits sur le marché pour aider à la lecture des documents, et certains. utiliser principalement des systèmes OCR pour lire du texte. La reconnaissance et la compréhension de texte avec LLM peuvent permettre d'obtenir de bonnes capacités de compréhension de documents.
Cependant, en raison des diverses catégories d'images de documents, du texte riche et de la mise en page complexe, il est difficile d'atteindre une compréhension universelle des images avec des structures complexes telles que des graphiques, des infographies et des pages Web.
Les grands modèles multimodaux actuellement populaires QwenVL-Max, Gemini, Claude3 et GPT4V ont tous de solides capacités de compréhension d'images de documents. Cependant, les modèles open source ont progressé lentement dans cette direction.
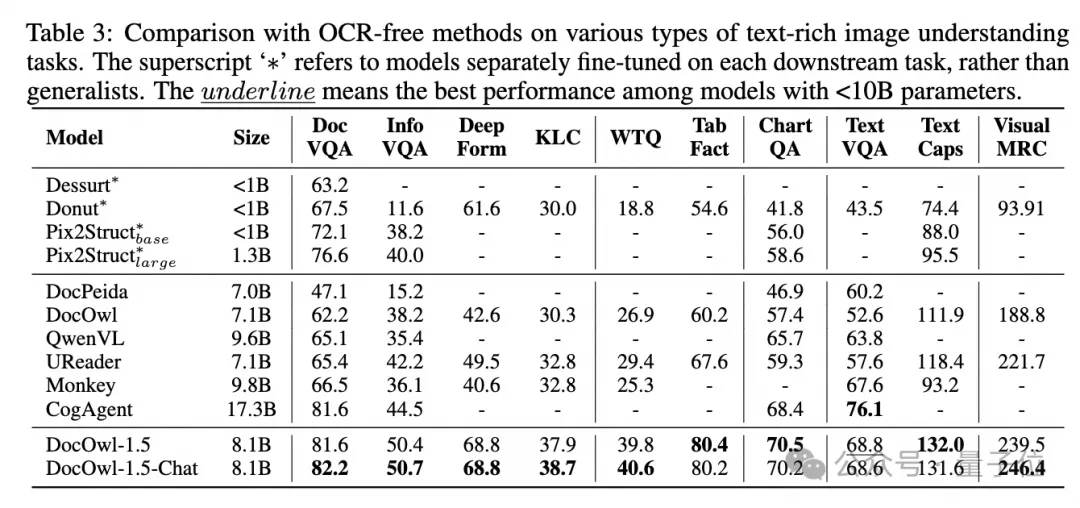
La nouvelle recherche d'Alibaba, mPLUG-DocOwl 1.5, a remporté le SOTA sur 10 tests de compréhension de documents, s'est améliorée de plus de 10 points sur 5 ensembles de données, a dépassé le CogAgent de Wisdom de 17,3 milliards sur certains ensembles de données et a atteint 82,2 sur l'effet DocVQA.
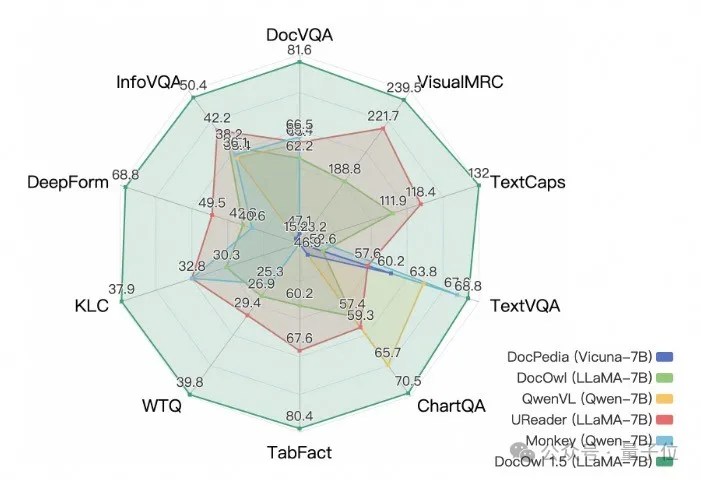
En plus de la capacité de fournir des réponses simples sur le benchmark, grâce à une petite quantité d'"explications détaillées" (raisonnement) affinement des données, DocOwl 1.5-Chat peut également avoir la capacité d'expliquer en détail dans le domaine des documents multimodaux, qui présente un grand potentiel d'application.
L'équipe Alibaba mPLUG investit dans la recherche multimodale sur la compréhension des documents depuis juillet 2023 et a successivement publié mPLUG-DocOwl, UReader, mPLUG-PaperOwl, mPLUG-DocOwl 1.5 et open source une série de modèles de compréhension de documents volumineux et données d'entraînement.
Cet article part du dernier travail mPLUG-DocOwl 1.5, analysant les principaux défis et solutions efficaces dans le domaine de la « compréhension multimodale des documents ».
Défi 1 : Reconnaissance de texte d'image haute résolution
Différentes des images générales, les images de documents se caractérisent par des formes et des tailles diverses, qui peuvent inclure des images de documents au format A4, des images de tableaux courtes et larges et des pages Web mobiles longues et étroites. Les captures d'écran, les images de scènes aléatoires, etc. sont distribuées dans une large gamme de résolutions.
Lorsque les grands modèles multimodaux grand public encodent des images, ils mettent souvent directement à l'échelle la taille de l'image. Par exemple, mPLUG-Owl2 et QwenVL évoluent à 448 x 448 et LLaVA 1.5 à 336 x 336.
La simple mise à l'échelle de l'image du document rendra le texte de l'image flou et déformé, le rendant méconnaissable.
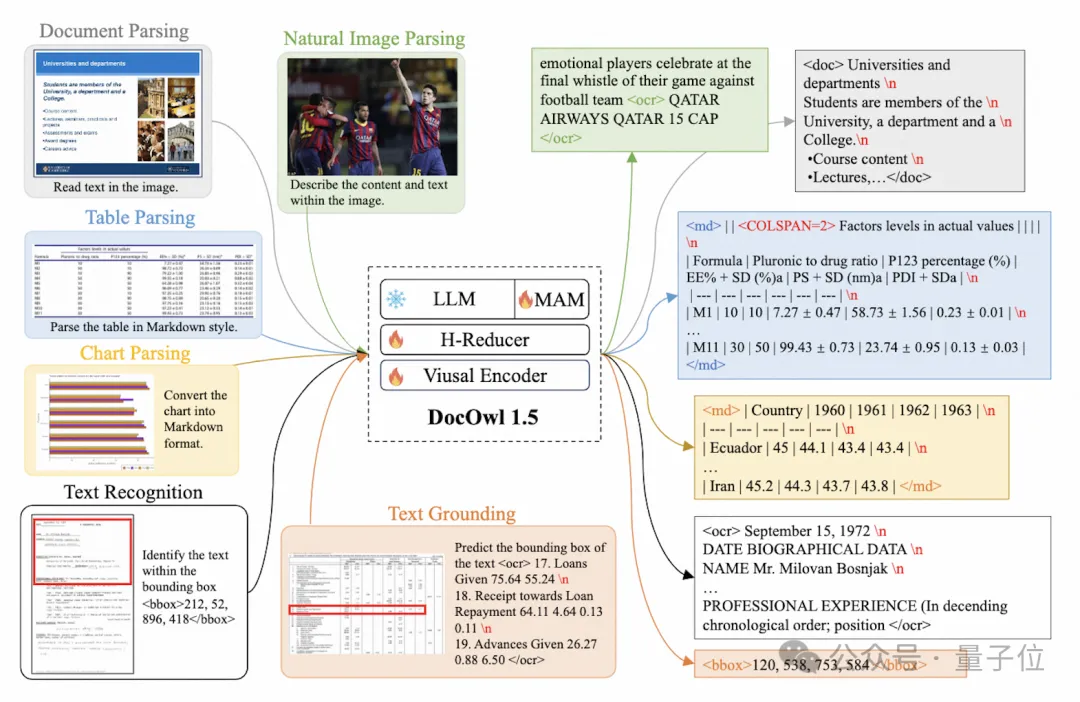
Afin de traiter les images de documents, mPLUG-DocOwl 1.5 poursuit l'approche de coupe de son prédécesseur UReader. La structure du modèle est illustrée dans la figure 1 :
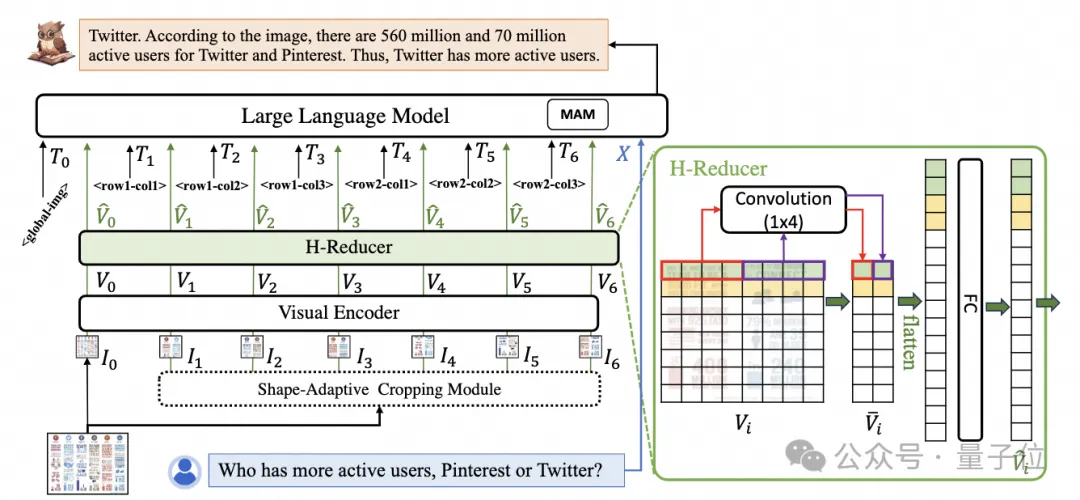
△Figure 1 : diagramme de structure du modèle DocOwl 1.5
UReader. Il a d'abord été proposé d'obtenir une série de sous-images via le module de recadrage adaptatif de forme sans paramètres basé sur le grand modèle multimodal existant. Chaque sous-image est codée par un encodeur basse résolution. Enfin, les sous-graphiques associés. pour diriger la sémantique via des modèles de langage. Cette stratégie de découpe graphique peut utiliser au maximum les capacités des encodeurs visuels à usage général existants
(tels que CLIP ViT-14/L) pour la compréhension des documents, réduisant considérablement le coût de reconversion des encodeurs visuels haute résolution . Le module de découpe à forme adaptée est représenté sur la figure 2 : Pour la compréhension des documents qui ne repose pas sur les systèmes OCR, la reconnaissance du texte est une capacité de base. Il est très important d'acquérir une compréhension sémantique et structurelle du contenu du document. Par exemple, comprendre le contenu des tableaux. nécessite de comprendre les en-têtes de tableau et la correspondance entre les lignes et les colonnes. La compréhension des graphiques nécessite la compréhension de diverses structures telles que les graphiques linéaires, les graphiques à barres et les diagrammes circulaires. La compréhension des contrats nécessite la compréhension de diverses paires clé-valeur telles que les signatures de date. mPLUG-DocOwl 1.5 se concentre sur la résolution des capacités de compréhension structurelle telles que les documents généraux. Grâce à l'optimisation de la structure du modèle et à l'amélioration des tâches de formation, il a atteint des capacités de compréhension générale des documents considérablement plus fortes. En termes de structure, comme le montre la figure 1, mPLUG-DocOwl 1.5 abandonne le module de connexion au langage visuel d'Abstractor dans mPLUG-Owl/mPLUG-Owl2, utilise H-Reducer basé sur "convolution + couche entièrement connectée" pour la fonctionnalité agrégation et alignement des fonctionnalités . Par rapport à Abstractor basé sur des requêtes apprenables, H-Reducer conserve la relation de position relative entre les caractéristiques visuelles et transfère mieux les informations sur la structure du document vers le modèle de langage. Par rapport au MLP qui conserve la longueur de la séquence visuelle, H-Reducer réduit considérablement le nombre de caractéristiques visuelles grâce à la convolution, permettant à LLM de comprendre plus efficacement les images de documents haute résolution. Considérant que le texte de la plupart des images de documents est d'abord disposé horizontalement et que la sémantique du texte dans la direction horizontale est cohérente, le H-Reducer utilise une forme de convolution et une taille de pas de 1x4. Dans cet article, l'auteur a prouvé, grâce à suffisamment d'expériences comparatives, la supériorité de H-Reducer dans la compréhension structurelle et que 1x4 est une forme d'agrégat plus générale. En termes de tâches de formation, mPLUG-DocOwl 1.5 conçoit une tâche d'apprentissage de structure unifiée (Unified Structure Learning) pour tous les types d'images, comme le montre la figure 3. △Figure 3 : Apprentissage de structure unifié L'apprentissage de structure unifié comprend non seulement l'analyse globale de texte d'image, mais également la reconnaissance et le positionnement de texte multi-granularité. Dans la tâche globale d'analyse de texte d'image, pour les images de documents et les images de pages Web, les espaces et les sauts de ligne peuvent être utilisés pour représenter le plus souvent la structure du texte ; pour les tableaux, l'auteur introduit des caractères spéciaux pour représenter plusieurs lignes et colonnes en fonction de Syntaxe Markdown. Les caractères prennent en compte la simplicité et la polyvalence de la représentation des tableaux ; pour les graphiques, étant donné que les graphiques sont des présentations visuelles de données tabulaires, l'auteur utilise également des tableaux sous forme de Markdown comme cible d'analyse des graphiques naturels, sémantiques ; la description et le texte de la scène sont tout aussi importants, donc la forme de description de l'image associée au texte de la scène est utilisée comme cible d'analyse. Dans la tâche « Reconnaissance et positionnement de texte », afin de mieux s'adapter à la compréhension des images de documents, l'auteur a conçu la reconnaissance et le positionnement de texte selon quatre granularités de mots, phrases, lignes et blocs. Le cadre de délimitation utilise des nombres entiers discrétisés. pour représenter la plage 0-999. Afin de prendre en charge l'apprentissage d'une structure unifiée, l'auteur a construit un ensemble de formation complet DocStruct4M, couvrant différents types d'images telles que des documents/pages Web, des tableaux, des graphiques, des images naturelles, etc. Après un apprentissage de structure unifié, DocOwl 1.5 possède les capacités d'analyse structurée et de positionnement de texte d'images de documents dans plusieurs domaines. △Figure 4 : Analyse de texte structuré Comme le montrent les figures 4 et 5 : △Figure 5 : Reconnaissance et positionnement de texte multi-granularité "Instruction Follow"(Instruction Follow) nécessite que le modèle soit basé sur des capacités de base de compréhension de documents et effectue différentes tâches selon les instructions de l'utilisateur, telles que l'extraction d'informations, les questions et réponses, la description d'images, etc. Poursuivant la pratique de mPLUG-DocOwl, DocOwl 1.5 unifie plusieurs tâches en aval sous la forme de questions et réponses de commande. Après un apprentissage de structure unifié, un modèle général dans le domaine du document est obtenu grâce à une formation conjointe multi-tâches (généraliste). . (DocReason25K) via GPT3.5 et GPT4V basées sur les problèmes des tâches en aval. En combinant les tâches de document en aval et DocReason25K pour la formation, DocOwl 1.5-Chat peut obtenir de meilleurs résultats sur le benchmark : △ Figure 6 : Évaluation du benchmark de compréhension des documents et donner des explications détaillées : △Figure 7 : Explication détaillée de la compréhension du document Image du document En raison de la richesse des informations, la compréhension nécessite souvent l'introduction de connaissances supplémentaires, telles que des termes professionnels et leur signification dans des domaines particuliers, etc. Afin d'étudier comment introduire des connaissances externes pour une meilleure compréhension des documents, l'équipe mPLUG a débuté dans le domaine du papier et a proposé mPLUG-PaperOwl, créant un ensemble de données d'analyse de cartes papier de haute qualité M-Paper, impliquant 447 000 papiers haute définition. graphiques. Ces données fournissent un contexte aux graphiques du document en tant que source externe de connaissances et conçoivent des « points clés » (contour) comme signaux de contrôle pour l'analyse des graphiques afin d'aider le modèle à mieux saisir l'intention de l'utilisateur. Sur la base de UReader, l'auteur a affiné mPLUG-PaperOwl sur M-Paper, qui a démontré des capacités préliminaires d'analyse de cartes papier, comme le montre la figure 8. △Figure 8 : Analyse des graphiques papier mPLUG-PaperOwl n'est actuellement qu'une première tentative d'introduction de connaissances externes dans la compréhension des documents. Il est encore confronté à des problèmes tels que les limitations de domaine et les sources de connaissances uniques qui doivent être résolus davantage. En général, cet article part du 7B le plus puissant de compréhension de documents multimodaux récemment publié, mPLUG-DocOwl 1.5, et résume les quatre défis clés de la compréhension de documents multimodaux sans s'appuyer sur l'OCR ("Texte d'image haute résolution reconnaissance", "Compréhension de la structure universelle des documents", "Suivi des instructions", "Introduction aux connaissances externes") et la solution proposée par l'équipe Alibaba mPLUG. Bien que mPLUG-DocOwl 1.5 ait considérablement amélioré les performances de compréhension des documents du modèle open source, il est encore loin du grand modèle fermé et des besoins pratiques. Il y a encore place à l'amélioration dans la reconnaissance de texte, les calculs mathématiques, l'usage général, etc. dans des scènes naturelles. L'équipe mPLUG optimisera davantage les performances de DocOwl et l'ouvrira en source libre. Tout le monde est invité à continuer à y prêter attention et à avoir des discussions amicales ! Lien GitHub : https://github.com/X-PLUG/mPLUG-DocOwl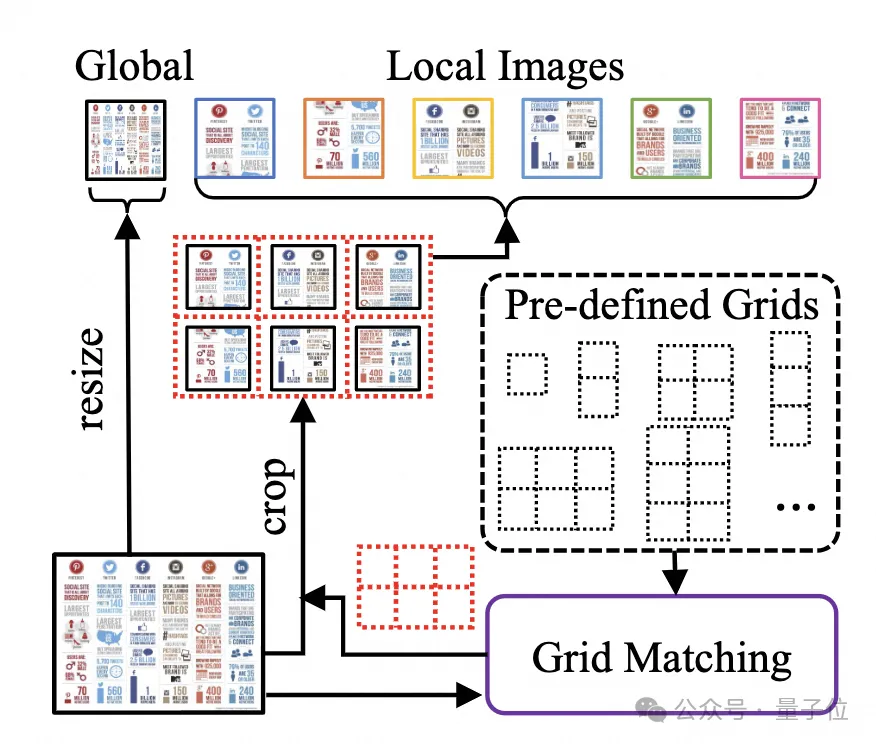
△Figure 2 : Module de découpe adaptable à la forme.
Défi 2 : Compréhension générale de la structure des documents

Défi 3 : Instruction suivante

Défi 4 : Introduction de connaissances externes
Lien papier : https://arxiv.org/abs/2403.12895
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les résultats Mybatis génèrent des paires clé-valeur
- Comment enregistrer des images PS au format AI
- Les étapes de base de l'utilisation de l'IA pour décrire des images
- CMS open source bien connu : Dreamweaver CMS dira adieu au gratuit, et l'ère de l'open source décline progressivement !
- JavaScript : Comment supprimer la paire clé-valeur correspondant à une clé donnée d'un objet ?