
Maison >Périphériques technologiques >IA >Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU

- 王林avant
- 2024-04-01 19:46:111419parcourir
JAX, promu par Google, a surpassé Pytorch et TensorFlow lors de récents tests de référence, se classant premier sur 7 indicateurs.

Et le test n'a pas été fait sur le TPU avec les meilleures performances JAX.

Bien que Pytorch soit toujours plus populaire que Tensorflow parmi les développeurs.
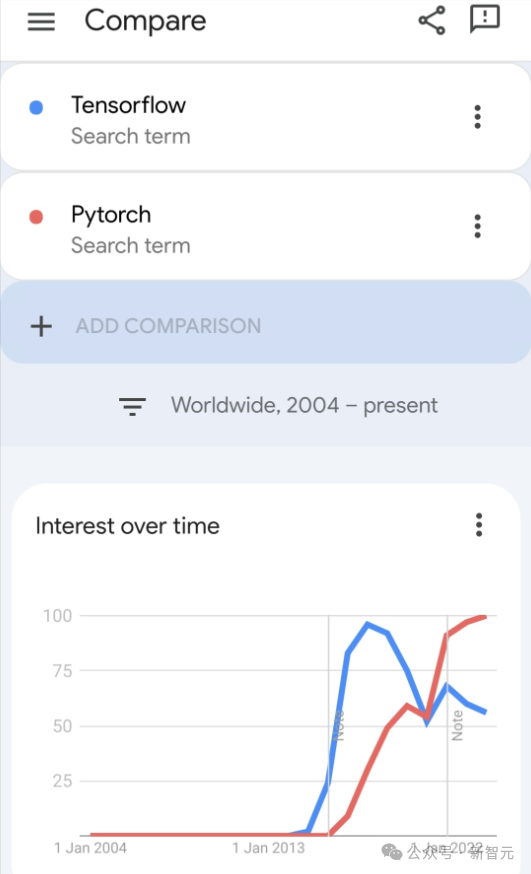
Mais à l'avenir, peut-être que davantage de modèles volumineux seront formés et exécutés sur la base de la plate-forme JAX.
Model
Récemment, l'équipe Keras a effectué des benchmarks pour trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras 2 avec TensorFlow.
Tout d'abord, ils ont sélectionné un ensemble de modèles traditionnels de vision par ordinateur et de traitement du langage naturel pour les tâches d'intelligence artificielle génératives et non génératives :

Pour la version Keras du modèle, il a adopté KerasCV et KerasNLP Build sur la mise en œuvre existante. Pour la version native de PyTorch, nous avons choisi les options les plus populaires sur Internet :
- BERT, Gemma, Mistral de HuggingFace Transformers
- StableDiffusion de HuggingFace Diffusers
- SegmentN'importe quoi de Meta
Ils appellent cet ensemble de modèles "Native PyTorch" pour le distinguer de la version Keras 3 qui utilise le backend PyTorch.
Ils ont utilisé des données synthétiques pour tous les benchmarks et ont utilisé la précision bfloat16 dans toutes les formations et inférences LLM, tout en utilisant LoRA (réglage fin) dans toutes les formations LLM.
Selon la suggestion de l'équipe PyTorch, ils ont utilisé torch.compile(model, mode="reduce-overhead") dans l'implémentation native de PyTorch (sauf pour la formation Gemma et Mistral en raison d'une incompatibilité).
Pour mesurer les performances prêtes à l'emploi, ils utilisent des API de haut niveau (telles que HuggingFace's Trainer(), des boucles de formation PyTorch standard et Keras model.fit()) avec le moins de configuration possible.
Configuration matérielle
Tous les tests de référence ont été effectués à l'aide de Google Cloud Compute Engine, configuré comme : un GPU NVIDIA A100 avec 40 Go de mémoire vidéo, 12 processeurs virtuels et 85 Go de mémoire hôte.
Résultats de référence
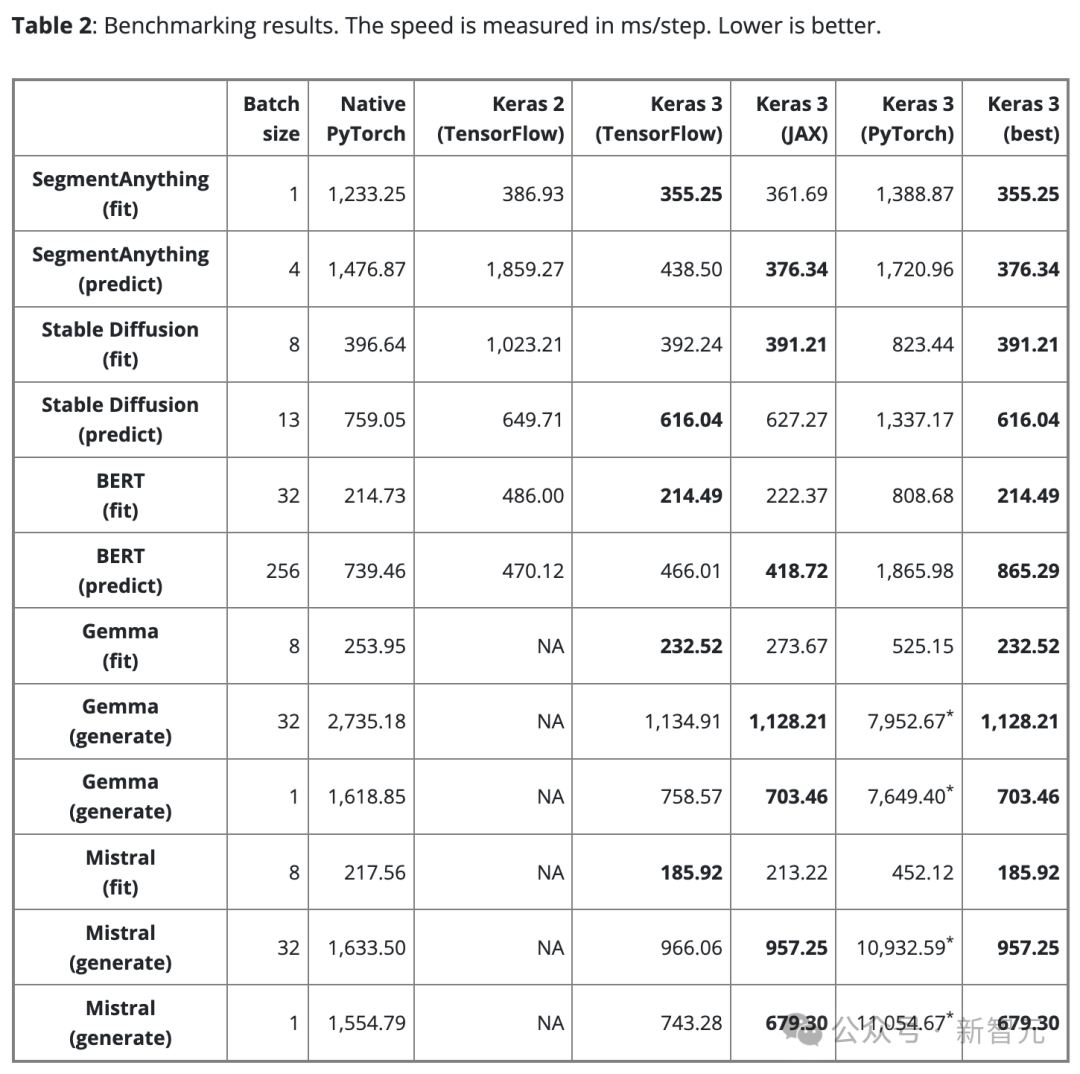
Le tableau 2 montre les résultats de référence en étapes/ms. Chaque étape implique un entraînement ou une prédiction sur un seul lot de données.
Le résultat est la moyenne de 100 étapes, mais la première étape est exclue car la première étape comprend la création et la compilation du modèle, ce qui prend plus de temps.
Pour garantir une comparaison équitable, la même taille de lot est utilisée pour le même modèle et la même tâche (qu'il s'agisse de formation ou d'inférence).
Cependant, pour différents modèles et tâches, en raison de leurs différentes échelles et architectures, la taille du lot de données peut être ajustée si nécessaire pour éviter un débordement de mémoire dû à une trop grande taille ou une utilisation du GPU due à des lots trop petits et insuffisants.
Une taille de lot trop petite peut également ralentir PyTorch car elle augmente la surcharge de Python.
Pour les grands modèles de langage (Gemma et Mistral), la même taille de lot a également été utilisée lors des tests puisqu'il s'agit du même type de modèle avec un nombre similaire de paramètres (7B).
Compte tenu des besoins des utilisateurs en matière de génération de texte en un seul lot, nous avons également effectué un test de référence sur la génération de texte avec une taille de lot de 1.
Principales conclusions
Découverte 1
Il n'y a pas de backend "optimal".
Les trois backends de Keras ont chacun leurs propres atouts. L'important est qu'en termes de performances, aucun backend ne peut toujours gagner.
Le choix du backend le plus rapide dépend souvent de l'architecture du modèle.
Ce point souligne l'importance de choisir différents frameworks dans la recherche de performances optimales. Keras 3 facilite le changement de backend pour trouver la meilleure solution pour votre modèle.
Found 2
Keras 3 surpasse généralement l'implémentation standard de PyTorch.
Par rapport à PyTorch natif, Keras 3 présente une amélioration significative du débit (pas/ms).
En particulier, dans 5 des 10 tâches de test, la vitesse a augmenté de plus de 50 %. Parmi eux, le plus élevé atteint 290 %.
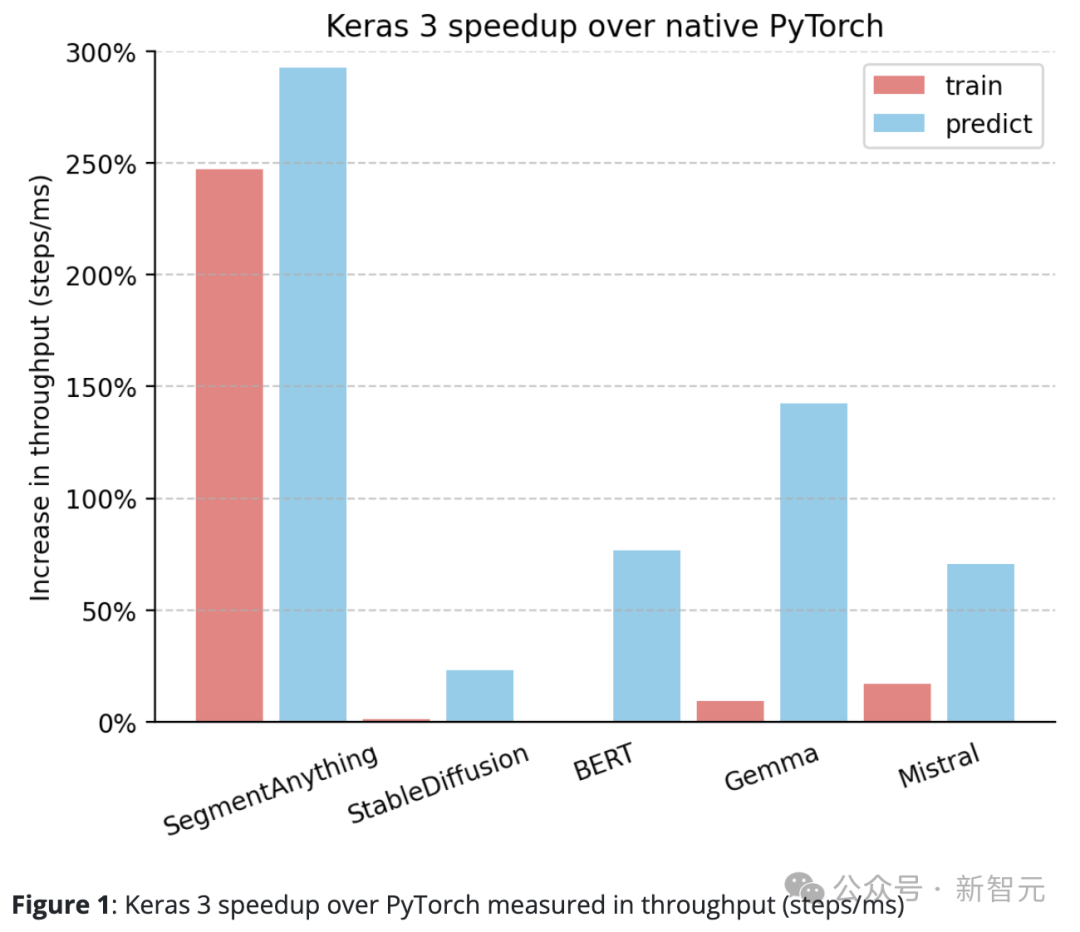
Si c'est 100%, ça veut dire que Keras 3 est 2 fois plus rapide que PyTorch si c'est 0%, ça veut dire que les performances des deux sont équivalentes
Découvrez 3
Keras 3 offre les meilleures performances « prêtes à l'emploi » de sa catégorie.
C'est-à-dire que tous les modèles Keras participant au test n'ont été optimisés d'aucune façon. En revanche, lorsqu’ils utilisent l’implémentation native de PyTorch, les utilisateurs doivent généralement effectuer eux-mêmes davantage d’optimisations de performances.
En plus des données partagées ci-dessus, il a également été remarqué lors du test que les performances de la fonction d'inférence StableDiffusion des diffuseurs HuggingFace ont augmenté de plus de 100 % lors de la mise à niveau de la version 0.25.0 vers la version 0.3.0.
De même, dans HuggingFace Transformers, la mise à niveau de Gemma de la version 4.38.1 à la version 4.38.2 a également considérablement amélioré les performances.
Ces améliorations de performances mettent en évidence l'attention et les efforts de HuggingFace en matière d'optimisation des performances.
Pour certains modèles avec moins d'optimisation manuelle, comme SegmentAnything, l'implémentation fournie par l'auteur de l'étude est utilisée. Dans ce cas, l’écart de performances par rapport au Keras est plus important que celui de la plupart des autres modèles.
Cela montre que Keras est capable de fournir d'excellentes performances prêtes à l'emploi et que les utilisateurs peuvent profiter de vitesses d'exécution rapides du modèle sans avoir à se plonger dans toutes les techniques d'optimisation.
Trouvé 4
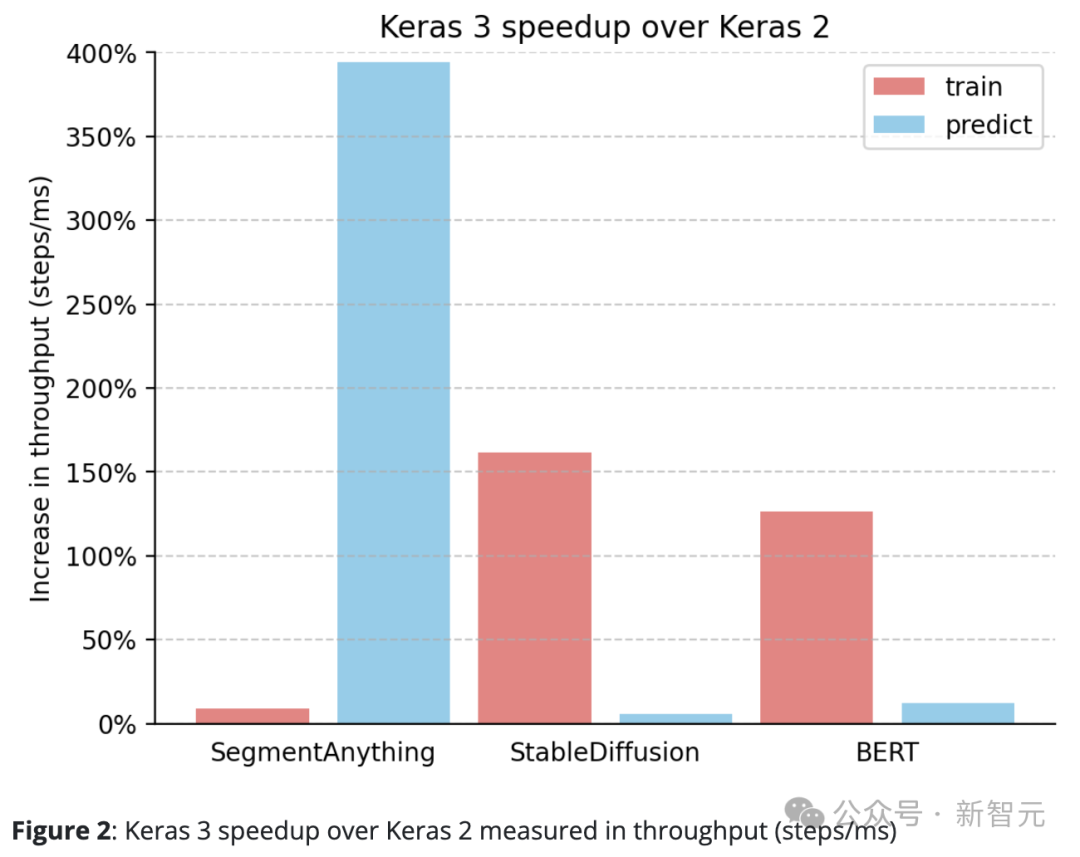
Keras 3 surpasse systématiquement Keras 2.
Par exemple, la vitesse d'inférence de SegmentAnything a augmenté d'un étonnant 380 %, la vitesse de traitement de formation de StableDiffusion a augmenté de plus de 150 % et la vitesse de traitement de formation de BERT a également augmenté de plus de 100 %.
Cela est principalement dû au fait que Keras 2 utilise directement davantage d'opérations de fusion TensorFlow dans certains cas, ce qui n'est peut-être pas le meilleur choix pour la compilation XLA.
Il convient de noter que même la simple mise à niveau vers Keras 3 et la poursuite de l'utilisation du backend TensorFlow ont entraîné des améliorations significatives des performances.
Conclusion
Les performances du framework dépendent fortement du modèle spécifique utilisé.
Keras 3 peut aider à choisir le framework le plus rapide pour la tâche, et ce choix surpassera presque toujours les implémentations de Keras 2 et PyTorch.
Plus important encore, les modèles Keras 3 offrent d'excellentes performances prêtes à l'emploi sans optimisations sous-jacentes complexes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- À quel type de modèle de données appartient le serveur SQL ?
- Comment additionner une colonne de données dans Excel
- Comment calculer la taille du modèle de boîte CSS
- Quels sont les quatre modèles courants de développement de logiciels ?
- Qu'est-ce que le modèle de données utilisant la structure arborescente ?