
Maison >Périphériques technologiques >IA >'C'est difficile de faire la distinction entre le vrai et le faux' ! Utilisation intelligente des données de simulation de conduite autonome générées par NeRF
'C'est difficile de faire la distinction entre le vrai et le faux' ! Utilisation intelligente des données de simulation de conduite autonome générées par NeRF

- PHPzavant
- 2024-04-01 11:31:16671parcourir
Écrit avant et compréhension personnelle de l'auteur
Le champ de rayonnement neuronal (NeRF) est devenu un outil qui fait progresser le prélude à la recherche sur la conduite autonome (AD), offrant des capacités évolutives de simulation en boucle fermée et d'amélioration des données. Cependant, afin de faire confiance aux résultats obtenus dans la simulation, il est nécessaire de s'assurer que le système AD perçoit les données réelles et les données restituées de la même manière. Bien que les performances des méthodes de rendu s’améliorent, de nombreuses scènes restent intrinsèquement difficiles à reconstruire fidèlement. À cette fin, nous proposons une nouvelle perspective pour combler l’écart entre les données réelles et simulées. Nous ne nous concentrons pas uniquement sur l'amélioration de la fidélité du rendu, mais explorons des méthodes simples mais efficaces pour améliorer la robustesse des modèles de perception face aux artefacts NeRF sans affecter les performances des données réelles. En outre, nous menons la première enquête à grande échelle sur l'écart entre les données réelles et simulées dans les paramètres AD en utilisant des techniques de rendu neuronal de pointe. Plus précisément, notre étude évalue les détecteurs d'objets et les modèles de cartographie en ligne sur des données réelles et simulées et étudie les effets de différentes stratégies de pré-formation. Nos résultats montrent une précision du modèle considérablement améliorée sur les données simulées, améliorant même les performances réelles dans certains cas. Enfin, nous approfondissons les similitudes entre le réel et le simulé, en identifiant le FID et le LPIPS comme des indicateurs puissants.
Dans cet article, nous proposons une nouvelle perspective pour combler le fossé entre les systèmes de conduite intelligents et les modules de perception. Notre objectif n'est pas d'améliorer la qualité du rendu mais de rendre le modèle perceptuel plus robuste aux artefacts NeRF sans dégrader les performances sur les données réelles. Nous pensons que cette orientation est complémentaire à l’amélioration des performances NeRF et est essentielle pour permettre les tests audiovisuels virtuels. Comme premier pas dans cette direction, nous montrons que même des techniques simples d'augmentation des données peuvent avoir un impact important sur la robustesse du modèle aux artefacts NeRF.
Nous menons la première étude approfondie real2sim+gap sur un ensemble de données AD à grande échelle et évaluons les performances de plusieurs détecteurs d'objets ainsi que des modèles de cartographie en ligne sur des données réelles et des données de la méthode de rendu neuronal de pointe (SOTA). . Notre étude inclut l'impact de différentes techniques d'augmentation des données lors de la formation et la fidélité du rendu NeRF lors de l'inférence. Nous avons constaté que lors du réglage fin du modèle, ces données montraient l'impact de la technique d'augmentation et que la fidélité du rendu NeRF améliorait même les performances sur des données réelles dans certains cas. Enfin, nous étudions la corrélation entre les métriques de reconstruction d'image implicites et communes dans real2sim et obtenons un aperçu de l'importance de l'utilisation des NeRF pour les simulateurs de données CAO. Nous constatons que LPIPS et FID sont de puissants indicateurs de disparité real2sim et vérifions en outre que l'amélioration proposée réduit la sensibilité de la composition visuelle à faible contraste.

Explication détaillée de la méthode
Pour tester et valider les capacités AD du moteur de simulation piloté par NeRF, ils peuvent utiliser les données collectées pour explorer de nouveaux scénarios virtuels. Cependant, pour que les résultats utilisant de tels modèles soient fiables, le système AD doit se comporter de la même manière lors du traitement des données et des données réelles. Dans ce travail, nous proposons une approche alternative et complémentaire pour adapter les systèmes AD afin de les rendre moins sensibles aux différences entre les données réelles et simulées. De cette façon, nous pouvons régler le système AD pour qu'il soit moins sensible aux différences entre les données réelles et simulées et ainsi mieux gérer les différences entre les données réelles et simulées.
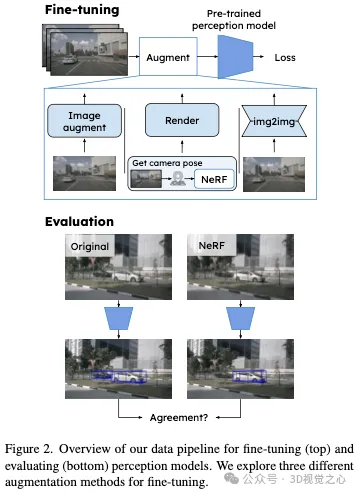
Dans une première étape dans l'exploration de la façon dont les stratégies de réglage fin peuvent rendre les modèles de perception plus robustes aux artefacts dans les données rendues, nous avons utilisé différentes stratégies de réglage fin. Plus précisément, étant donné un modèle déjà entraîné, nous affinons le modèle perceptuel à l'aide d'images qui se concentrent sur l'amélioration des performances des images rendues tout en maintenant les performances sur les données réelles, voir Figure 2. En plus de réduire l'écart entre real2SIM, cela pourrait également réduire les exigences en matière de réalisme des capteurs, ouvrir la voie à une application plus large des méthodes de rendu neuronal et réduire les exigences de calcul pour la formation et l'évaluation des méthodes de description. Notez que même si nous nous concentrons sur les modèles perceptuels, notre approche peut également être facilement étendue aux modèles de bout en bout.
Enfin, nous pouvons imaginer plusieurs façons d'atteindre l'objectif de rendre les modèles plus robustes, par exemple en s'inspirant de la littérature sur l'adaptation de domaine et l'apprentissage multitâche. Cependant, le réglage fin nécessite des ajustements minimes spécifiques au modèle, ce qui nous permet d'étudier facilement une gamme de modèles.
Augmentations d'images
L'augmentation d'image est une méthode couramment utilisée, et la stratégie classique pour améliorer la robustesse contre les artefacts consiste à utiliser l'augmentation d'image. Ici, nous choisissons des améliorations pour représenter les différentes distorsions présentes dans l'image rendue. Plus précisément, nous ajoutons du bruit gaussien aléatoire et convoluons l'image avec un noyau de flou gaussien, en appliquant une distorsion photométrique similaire à celle trouvée dans SimCLR. Enfin, l’image est sous-échantillonnée et suréchantillonnée. Les augmentations sont appliquées séquentiellement et chaque augmentation a une certaine probabilité.
Réglage fin avec des images rendues mélangées
NeRF est un modèle d'apprentissage en profondeur pour le rendu de scènes 3D. Lors du réglage fin, le modèle peut s'adapter à une autre forme naturelle, c'est-à-dire inclure ces données lors du réglage fin. Cela facilite la capacité de former des modèles NeRF afin que les méthodes NeRF puissent être formées sur le même ensemble de données que le modèle prenant en compte la surveillance. Cependant, la formation NeRF sur de grands ensembles de données peut s'avérer coûteuse, dont certaines peuvent nécessiter des étiquettes pour des tâches telles que la détection d'objets 3D, la segmentation sémantique ou plusieurs étiquettes de catégories. De plus, le NeRF d'AD augmente souvent les exigences en matière d'ordre des données. Afin de s'adapter à ces exigences, les étiquettes peuvent nécessiter des traitements plus particuliers, comme la détection d'objets 3D, la segmentation sémantique ou les étiquettes de catégories multiples, etc.
Ensuite, nous divisons les images de la séquence sélectionnée en un ensemble d'entraînement NeRF et un ensemble d'exclusion. Le réglage fin des modèles perceptuels est effectué sur l'ensemble de leur ensemble de données d'entraînement D, et pour les images avec des correspondances de rendu en D, nous utilisons l'image rendue avec une probabilité p. Cela signifie que les images utilisées pour le réglage fin ne sont pas vues par le modèle NeRF.
Traduction d'image à image
Comme mentionné précédemment, le rendu des données NeRF est une technique coûteuse d'augmentation des données. De plus, en plus des données nécessaires à la tâche de perception, elle nécessite également des données séquentielles et potentiellement des marqueurs supplémentaires. Autrement dit, pour une approche évolutive, nous souhaitons idéalement une stratégie efficace pour obtenir des données NeRF pour une seule image. À cette fin, nous proposons d'utiliser une approche image à image pour apprendre à générer des images de type NeRF. Étant donné une image réelle, le modèle convertit l'image dans le domaine NeRF, introduisant ainsi des artefacts typiques de NeRF. Cela nous permet d’augmenter considérablement le nombre d’images de type NeRF lors du réglage fin, avec un coût de calcul limité. Nous entraînons le modèle image à image en utilisant les images rendues Dnerf et leurs images réelles correspondantes. Des exemples visuels de différentes stratégies d’amélioration sont présentés dans la figure 3.

Résultat
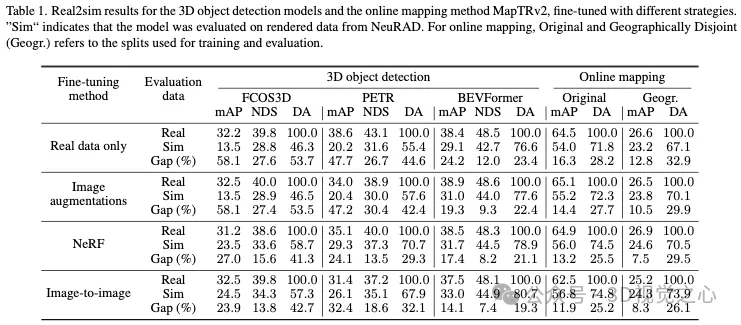
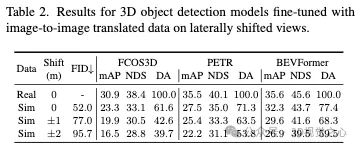
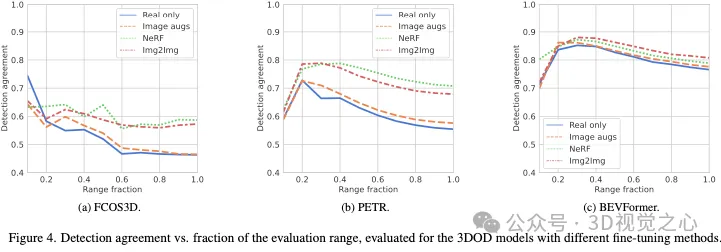

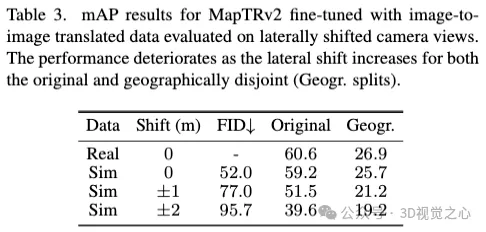
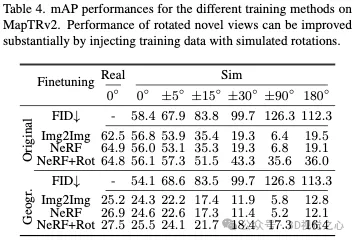
Le champ de rayonnement neuronal (NeRF) fait désormais partie de la simulation de conduite autonome (AD) données, une approche prometteuse. Cependant, pour être pratique, il est nécessaire de comprendre comment les actions effectuées par le système AD sur des données simulées se traduisent en données réelles. Notre enquête à grande échelle révèle un écart de performance entre les modèles perceptuels exposés à des images simulées et réelles.
Contrairement aux approches antérieures axées sur l'amélioration de la qualité du rendu, cet article étudie comment modifier le modèle perceptuel pour le rendre plus robuste aux données de simulation NeRF. Nous montrons qu'un réglage fin avec des données NeRF ou de type NeRF réduit considérablement l'écart real2sim pour la détection d'objets et les méthodes de cartographie en ligne sans sacrifier les performances sur les données réelles. De plus, nous montrons que la génération de nouveaux scénarios en dehors des distributions de trains existantes, comme la simulation de sorties de voie, peut améliorer les performances sur des données réelles. Une étude des métriques d'images couramment utilisées au sein de la communauté NeRF montre que les scores LPIPS et FID présentent la plus forte corrélation avec les performances perceptuelles. Cela suggère que la similarité perceptuelle a une plus grande importance pour les modèles perceptuels que la simple qualité de la reconstruction. En conclusion, nous pensons que les données de simulation NeRF sont précieuses pour la MA, en particulier lorsque nous utilisons la méthode proposée pour améliorer la robustesse du modèle de perception. De plus, les données NeRF aident non seulement à tester les systèmes AD sur des données simulées, mais contribuent également à améliorer les performances des modèles de perception sur des données réelles.Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!