
Maison >Périphériques technologiques >IA >Le nouveau cadre de l'Université Jiao Tong de Shanghai débloque les capacités de texte long CLIP, saisit les détails de la génération multimodale et améliore considérablement les capacités de récupération d'images
Le nouveau cadre de l'Université Jiao Tong de Shanghai débloque les capacités de texte long CLIP, saisit les détails de la génération multimodale et améliore considérablement les capacités de récupération d'images

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-04-01 09:26:33593parcourir
La capacité de texte long CLIP est déverrouillée et les performances des tâches de récupération d'images sont considérablement améliorées !
Certains détails clés peuvent également être capturés. L'Université Jiao Tong de Shanghai et le Shanghai AI Laboratory ont proposé un nouveau cadre Long-CLIP.
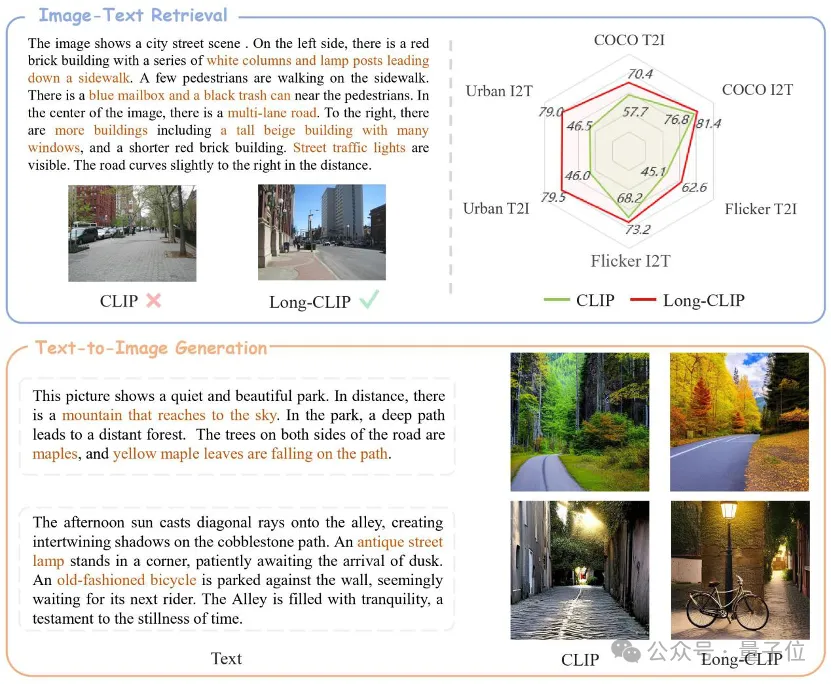
△Le texte marron est le détail clé qui distingue les deux images
Long-CLIP est basé sur le maintien de l'espace de fonctionnalités d'origine de CLIP et est plug-and-play dans les tâches en aval telles que la génération d'images pour obtenir de bons résultats. génération d'images à granularité de texte long.
La récupération de texte-image longue a augmenté de 20 %, la récupération de texte-image courte a augmenté de 6 %.
Débloquez les capacités de texte long de CLIP
CLIP aligne les modalités visuelles et textuelles et dispose de puissantes capacités de généralisation sans tir. Par conséquent, CLIP est largement utilisé dans diverses tâches multimodales, telles que la classification d'images, la récupération d'images texte, la génération d'images, etc.
Mais un inconvénient majeur de CLIP est le manque de capacités de texte long.
Tout d'abord, en raison de l'utilisation du codage de position absolue, la longueur de saisie du texte de CLIP est limitée à 677 jetons. De plus, des expériences ont prouvé que la longueur effective réelle de CLIP est même inférieure à 20 jetons, ce qui est loin d'être suffisant pour représenter des informations précises. Cependant, pour surmonter cette limitation, des chercheurs ont proposé une solution. En introduisant des balises spécifiques dans la saisie de texte, le modèle peut se concentrer sur les parties importantes. La position et le nombre de ces jetons dans l'entrée sont déterminés à l'avance et ne dépasseront pas 20 jetons. De cette manière, CLIP est capable de gérer la saisie de texte. L'absence de texte long côté texte limite également les capacités du côté visuel. Puisqu'il ne contient que du texte court, l'encodeur visuel de CLIP n'extrairea que les composants les plus importants d'une image, tout en ignorant divers détails. Ceci est très préjudiciable aux tâches plus fines telles que la
récupération multimodale. Dans le même temps, l'absence de texte long amène également CLIP à adopter une méthode de modélisation simple similaire au bag-of-feature (BOF), qui n'a pas de capacités complexes telles que le raisonnement causal.
Pour résoudre ce problème, les chercheurs ont proposé le modèle Long-CLIP.
Propose spécifiquement deux stratégies : l'étirement de l'intégration positionnelle préservant les connaissances et une stratégie de réglage fin qui ajoute l'alignement des composants de base (correspondance des composants primaires). 
Extension du codage positionnel préservant les connaissances
Une méthode simple pour étendre la longueur d'entrée et améliorer la capacité du texte long consiste d'abord à interpoler le codage positionnel à un rapport fixe λ
1, puis à l'affiner au fil du temps. texte. Les chercheurs ont découvert que le degré de formation des différents encodages de position du CLIP est différent. Étant donné que le texte d'apprentissage est susceptible d'être principalement un texte court, le codage de position inférieure est entraîné de manière plus complète et peut représenter avec précision la position absolue, tandis que le codage de position supérieure ne peut représenter que sa position relative approximative. Par conséquent, le coût de l’interpolation des codes à différentes positions est différent.
Sur la base des observations ci-dessus, le chercheur a retenu les 20 premiers codes de position, et pour les 57 codes de position restants, interpolés avec un rapport plus grand λ
2 La formule de calcul peut être exprimée comme suit :
Expérience Cela montre que. par rapport à l'interpolation directe, cette stratégie peut améliorer considérablement les performances de diverses tâches tout en prenant en charge une longueur totale plus longue. 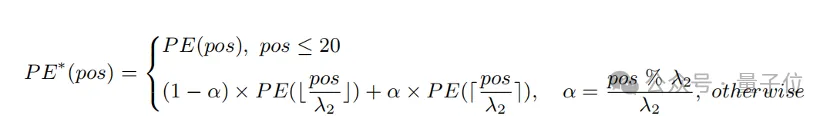
Ajouter un réglage fin de l'alignement des attributs de base
Seule l'introduction d'un réglage fin du texte long conduira le modèle à un autre malentendu, qui consiste à inclure tous les détails de la même manière. Pour résoudre ce problème, les chercheurs ont introduit la stratégie d’alignement des attributs de base lors du réglage fin.
Plus précisément, les chercheurs ont utilisé l'algorithme d'analyse en composantes principales (ACP) pour extraire les attributs de base des caractéristiques d'image à granularité fine, ont filtré les attributs restants pour reconstruire les caractéristiques d'image à granularité grossière et les ont comparés à des textes courts résumés. Cette stratégie nécessite que le modèle contienne non seulement plus de détails (alignement à granularité fine), mais qu'il identifie et modélise également la plupart des attributs essentiels (extraction des composants principaux et alignement à granularité grossière).
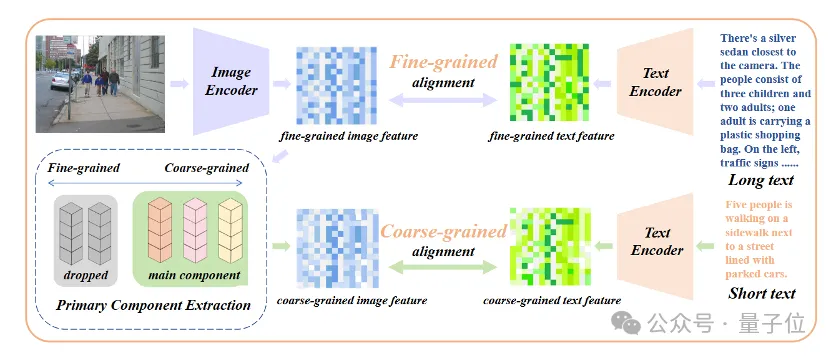 △Ajoutez le processus de réglage fin de l'alignement des attributs de base
△Ajoutez le processus de réglage fin de l'alignement des attributs de base
Plug and play dans diverses tâches multimodales
Dans les domaines de la récupération d'images et de texte, de la génération d'images et d'autres domaines, Long-CLIP peut brancher et jouer pour remplacer CLIP.
Par exemple, dans la récupération d'images et de texte, Long-CLIP peut capturer des informations plus fines en modes image et texte, améliorant ainsi la capacité de distinguer des images et du texte similaires et améliorant considérablement les performances de récupération d'images et de texte.
Qu'il s'agisse de tâches traditionnelles de récupération de texte court (COCO, Flickr30k) ou de tâches de récupération de texte long, Long-CLIP a considérablement amélioré le taux de rappel.
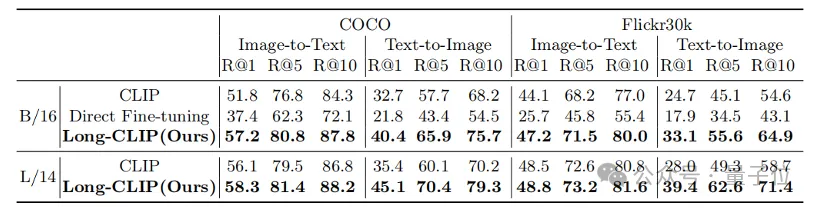
△Résultats expérimentaux de récupération de texte-image courte
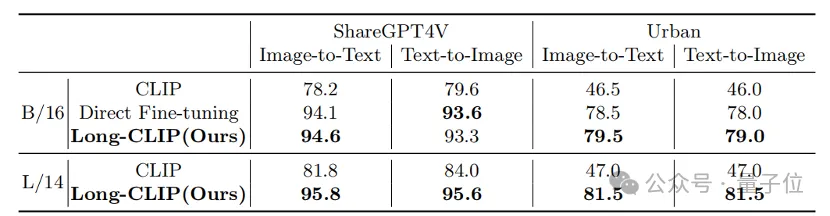
△Résultats expérimentaux de récupération de texte-image longue

△Visualisation de récupération de texte-image longue, le texte marron est le détail clé qui distingue les deux images
De plus, l'encodeur de texte de CLIP est souvent utilisé dans les modèles de génération de texte en image, tels que la série de diffusion stable, etc. Cependant, en raison du manque de fonctionnalités de texte long, les descriptions textuelles utilisées pour générer des images sont généralement très courtes et ne peuvent pas être personnalisées avec divers détails.
Long-CLIP peut dépasser la limite de 77 jetons et réaliser une génération d'images au niveau du chapitre (en bas à droite).
Vous pouvez également modéliser plus de détails dans 77 jetons pour obtenir une génération d'images plus fines (en haut à droite).

Lien papier :https://arxiv.org/abs/2403.15378
Lien code :https://github.com/beichenzbc/Long-CLIP
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!