
Maison >Périphériques technologiques >IA >À égalité en première place avec GPT-4, le benchmark LMSYS montre que le modèle Claude-3 est performant
À égalité en première place avec GPT-4, le benchmark LMSYS montre que le modèle Claude-3 est performant

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-28 17:26:43576parcourir

Nouvelles du 28 mars, selon le dernier rapport de référence publié par LMSYS Org, Claude-3 a dépassé de peu GPT-4 et est devenu le « meilleur » grand modèle de langage sur la plateforme.
Ce site Web présente d'abord LMSYS Org, qui est une organisation de recherche créée conjointement par l'Université de Californie à Berkeley, l'Université de Californie à San Diego et l'Université Carnegie Mellon.
Le système lance Chatbot Arena, une plateforme de référence pour les grands modèles de langage (LLM), qui utilise le crowdsourcing pour tester de manière anonyme et aléatoire des produits de grands modèles. Ses évaluations sont basées sur le système de notation Elo largement utilisé dans les jeux compétitifs tels que les échecs.
Grâce aux résultats d'évaluation générés par le vote des utilisateurs, le système sélectionnera au hasard deux robots de grand modèle différents pour discuter avec les utilisateurs à chaque fois, et permettra aux utilisateurs de choisir de manière anonyme quel produit de grand modèle est globalement le plus performant.
Chatbot Arena Depuis son lancement l'année dernière, GPT-4 occupe fermement la première place et est même devenu la référence en matière d'évaluation des grands modèles.
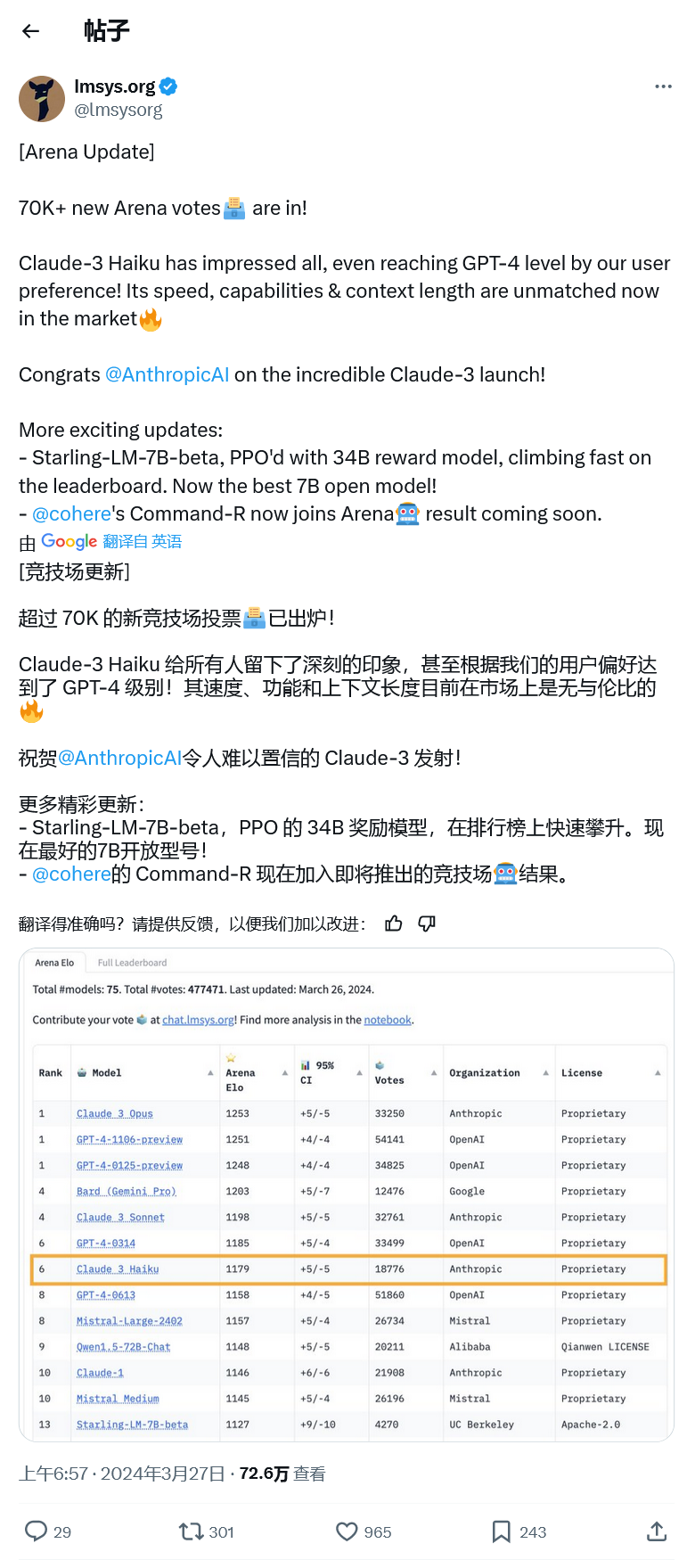
Cependant, hier, Claude 3 Opus d'Anthropic a battu GPT-4 par une faible marge de 1253 à 1251, et le LLM d'OpenAI a été repoussé de la première place. Parce que le score était trop serré, l'agence a laissé Claude 3 et GPT-4 ex æquo pour la première place en raison de considérations de taux d'erreur, et une autre version préliminaire de GPT-4 a également été ex æquo pour la première place.
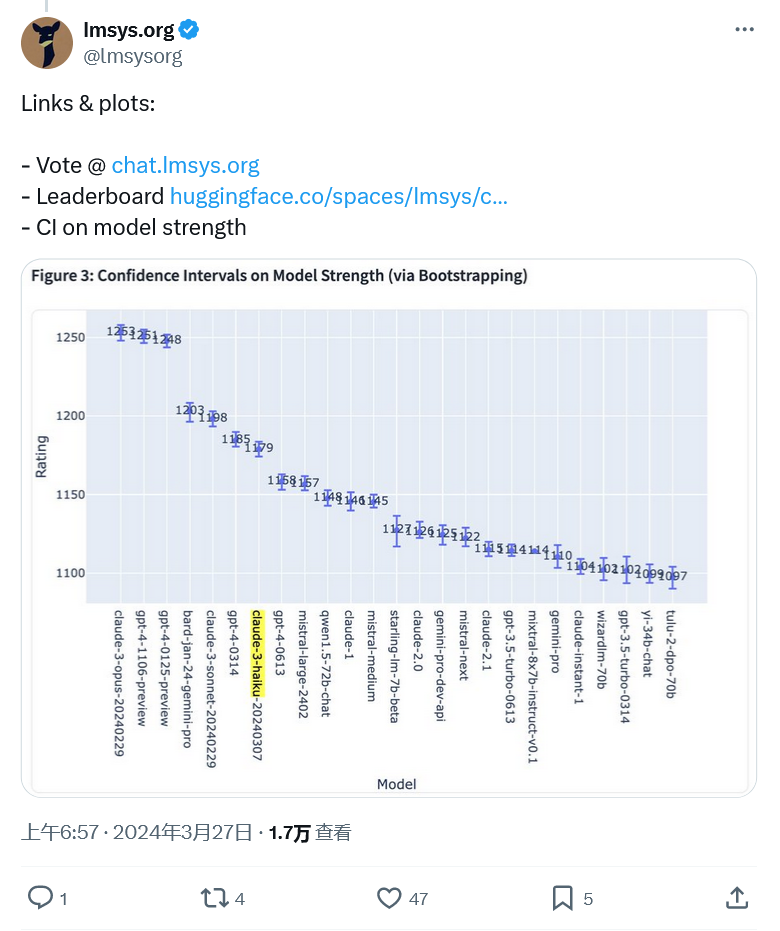
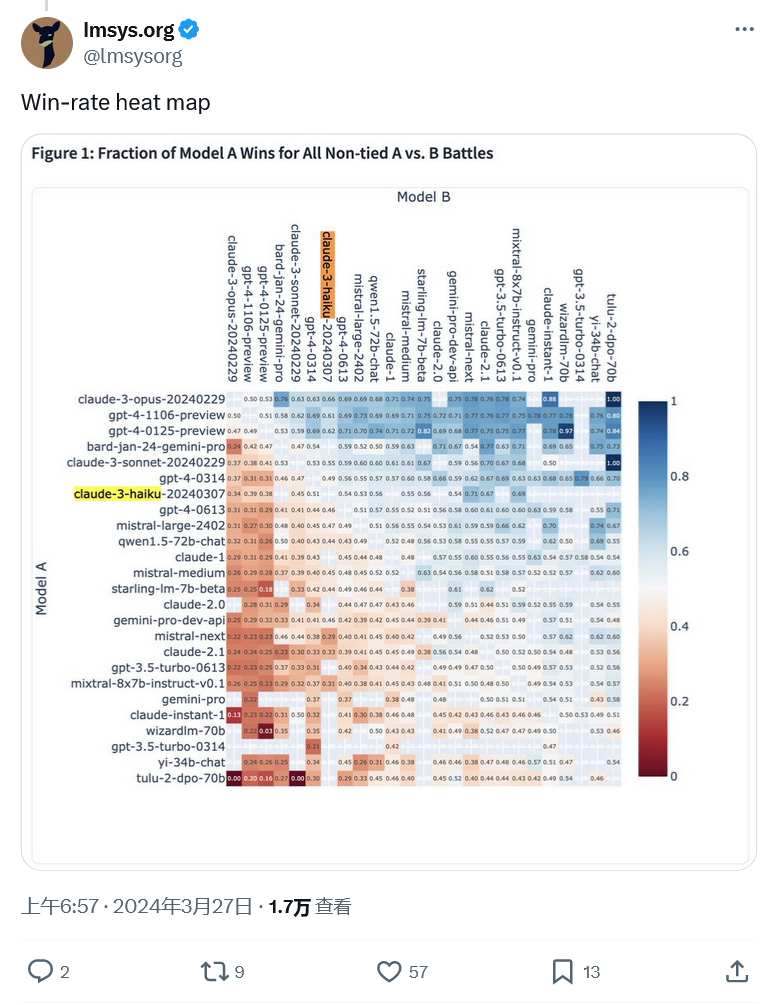
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quel langage de programmation est utilisé pour l'intelligence artificielle ?
- Quelles sont les tendances de développement de l'intelligence artificielle ?
- L'essence de l'intelligence artificielle est de simuler, voire de surpasser l'intelligence humaine, n'est-ce pas ?
- À quelle catégorie appartient l'intelligence artificielle ?
- Quelle est la relation entre l'intelligence artificielle, l'apprentissage automatique et l'apprentissage profond ?