
Maison >Périphériques technologiques >IA >Une vidéo IA peut être générée à partir d'une seule image ! Le nouveau modèle de diffusion de Google fait bouger les personnages
Une vidéo IA peut être générée à partir d'une seule image ! Le nouveau modèle de diffusion de Google fait bouger les personnages

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-28 15:40:16701parcourir
Vous n'avez besoin que d'une photo et d'un morceau d'audio pour générer directement une vidéo du personnage en train de parler !
Récemment, des chercheurs de Google ont publié le modèle de diffusion multimodale VLOGGER, nous rapprochant encore davantage des humains numériques virtuels.

Adresse papier : https://enriccorona.github.io/vlogger/paper.pdf
Vlogger peut collecter une seule image d'entrée et utiliser du texte ou un pilote audio pour générer une vidéo de la parole humaine, y compris oral La forme, l'expression, les mouvements du corps, etc. sont tous très naturels.
Voyons d'abord quelques exemples :




Si vous pensez que l'utilisation de la voix d'autres personnes dans la vidéo est un peu incohérente, l'éditeur vous aidera à désactiver le son :

On peut voir que l'ensemble de l'effet généré est très élégant et naturel.
VLOGGER s'appuie sur le succès récent des modèles de diffusion générative, notamment un modèle qui traduit les humains en mouvement 3D, et une nouvelle architecture basée sur la diffusion pour améliorer les images générées par texte avec un contrôle temporel et spatial.

VLOGGER peut générer des vidéos de haute qualité de durée variable, et ces vidéos peuvent être facilement contrôlées avec des représentations avancées de visages et de corps.

Par exemple, nous pouvons demander à la personne dans la vidéo générée de se taire :

ou de fermer les yeux :

Par rapport aux modèles similaires précédents, VLOGGER le fait pas besoin Il est formé sur des individus, ne repose pas sur la détection des visages et le recadrage, et inclut les mouvements du corps, les torses et les arrière-plans - constituant une performance humaine normale capable de communiquer.
La voix de l'IA, l'expression de l'IA, l'action de l'IA, la scène de l'IA, la valeur de l'être humain au début est de fournir des données, mais pourrait-elle n'avoir aucune valeur à l'avenir ?


En termes de données, les chercheurs ont collecté un nouvel ensemble de données diversifié MENTOR, qui est d'un ordre de grandeur plus grand que l'ensemble de données similaire précédent. L'ensemble de formation comprend 2 200 heures et 800 000 heures différentes. individus, l’ensemble du test est de 120 heures et 4000 personnes avec des identités différentes.

Les chercheurs ont évalué VLOGGER sur trois critères différents, montrant que le modèle atteignait des performances de pointe en termes de qualité d'image, de préservation de l'identité et de cohérence temporelle.
L'objectif de
VLOGGER
VLOGGER est de générer une vidéo réaliste de longueur variable illustrant l'ensemble du processus de parole de la personne cible, y compris les mouvements de la tête et les gestes.

Comme indiqué ci-dessus, étant donné une seule image d'entrée affichée dans la colonne 1 et un exemple d'entrée audio, une série d'images composites est affichée dans la colonne de droite.
Y compris la génération de mouvements de tête, de regards, de clignements, de mouvements de lèvres et quelque chose que les modèles précédents ne pouvaient pas faire, la génération du haut du corps et des gestes, ce qui constitue une avancée majeure dans la synthèse audio.
VLOGGER adopte un pipeline en deux étapes basé sur un modèle de diffusion aléatoire pour simuler un mappage un-à-plusieurs de la parole à la vidéo.
Le premier réseau prend des formes d'onde audio en entrée pour générer des commandes de mouvements corporels responsables du regard, des expressions faciales et des gestes sur la durée de la vidéo cible.
Le deuxième réseau est un modèle de traduction temporelle d'image à image qui étend le modèle de diffusion d'images à grande échelle pour utiliser le contrôle corporel prédit pour générer les images correspondantes. Pour aligner ce processus sur une identité spécifique, le réseau obtient une image de référence de la personne cible.
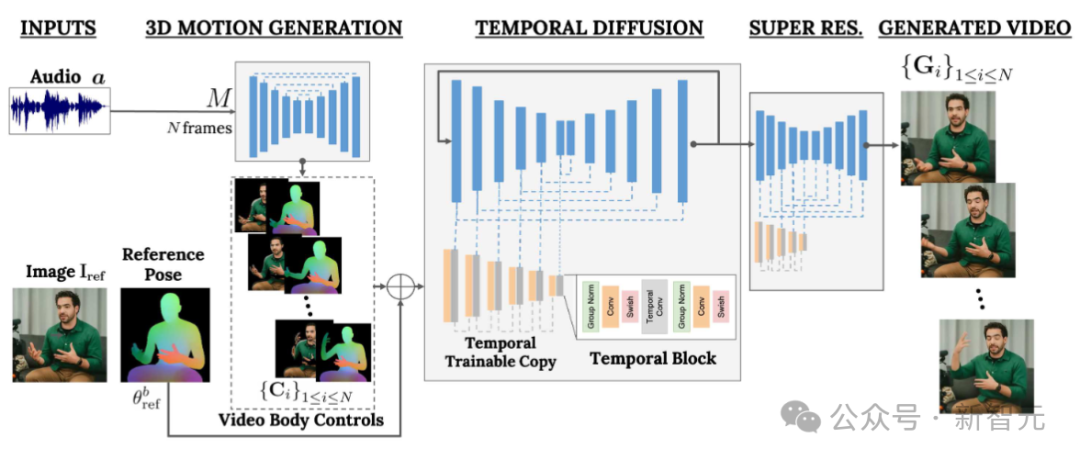
VLOGGER utilise des modèles corporels 3D basés sur des statistiques pour réguler le processus de génération vidéo. Étant donné une image d'entrée, les paramètres de forme prédits codent les propriétés géométriques de l'identité cible.
Tout d'abord, le réseau M prend la parole d'entrée et génère une série de N images d'expressions faciales et de poses corporelles en 3D.
Une représentation dense du corps 3D en mouvement est ensuite rendue pour servir de contrôle 2D pendant l'étape de génération vidéo. Ces images, ainsi que les images d'entrée, servent d'entrée au modèle de diffusion temporelle et aux modules de super-résolution.
Génération de mouvement pilotée par l'audio
Le premier réseau du pipeline est conçu pour prédire le mouvement en fonction de la parole d'entrée. De plus, le texte saisi est converti en forme d'onde via un modèle de synthèse vocale, et l'audio généré est représenté sous forme de spectrogrammes Mel standard.
Le pipeline est basé sur l'architecture Transformer et comporte quatre couches d'attention multi-têtes dans la dimension temporelle. Comprend le codage positionnel du numéro d'image et de l'étape de diffusion, ainsi que l'intégration de MLP pour l'entrée audio et l'étape de diffusion.
Dans chaque image, utilisez un masque causal pour que le modèle se concentre uniquement sur l'image précédente. Le modèle est entraîné à l'aide de vidéos de longueur variable (telles que l'ensemble de données TalkingHead-1KH) pour générer de très longues séquences.
Les chercheurs utilisent des paramètres estimés statistiquement d'un modèle de corps humain 3D pour générer des représentations de contrôle intermédiaires pour des vidéos synthétiques.
Le modèle prend en compte à la fois les expressions faciales et les mouvements du corps pour générer de meilleurs gestes expressifs et dynamiques.
De plus, les travaux de génération de visages précédents reposent généralement sur des images déformées, mais dans les architectures basées sur la diffusion, cette méthode a été ignorée.
Les auteurs suggèrent d’utiliser des images déformées pour guider le processus de génération, ce qui facilite la tâche du réseau et aide à maintenir l’identité sujet des personnages.
Générer des humains parlant et en mouvement
Le prochain objectif est d'effectuer un traitement de mouvement sur une image d'entrée d'une personne afin qu'elle suive les mouvements corporels et faciaux précédemment prédits.
Inspirés par ControlNet, les chercheurs ont gelé le modèle initialement formé et ont adopté des contrôles de temps d'entrée pour créer une copie entraînable initialisée à zéro de la couche d'encodage.
L'auteur entrelace des couches convolutionnelles unidimensionnelles dans le domaine temporel. Le réseau est formé en obtenant N images et contrôles consécutifs, et génère des vidéos d'action de personnages de référence basées sur les contrôles d'entrée.
Le modèle est entraîné à l'aide de l'ensemble de données MENTOR construit par l'auteur. Parce que pendant le processus d'entraînement, le réseau obtient une série d'images consécutives et d'images de référence arbitraires, donc en théorie n'importe quelle image vidéo peut être désignée comme référence.
En pratique, cependant, les auteurs choisissent d'échantillonner des références plus éloignées du clip cible, car des exemples plus proches offrent moins de potentiel de généralisation.
Le réseau est formé en deux étapes, d'abord l'apprentissage d'une nouvelle couche de contrôle sur une seule image, puis l'entraînement sur la vidéo en ajoutant une composante temporelle. Cela permet l’utilisation de gros lots dans la première étape et un apprentissage plus rapide des tâches de relecture en tête.
Le taux d'apprentissage utilisé par l'auteur est de 5e-5, et le modèle d'image est formé avec une taille de pas de 400 000 et une taille de lot de 128 dans les deux étapes.
Diversité
La figure ci-dessous montre la répartition diversifiée des vidéos cibles générées à partir d'une image d'entrée. La colonne la plus à droite montre la diversité de pixels obtenue à partir des 80 vidéos générées.

Tandis que l'arrière-plan reste fixe, la tête et le corps de la personne bougent considérablement (le rouge signifie une plus grande diversité de couleurs de pixels) et, malgré la diversité, toutes les vidéos se ressemblent. Très réaliste. L'une des applications de
Video Editing

consiste à éditer des vidéos existantes. Dans ce cas, VLOGGER prend une vidéo et modifie l'expression du sujet en fermant la bouche ou les yeux, par exemple.
En pratique, l'auteur profite de la flexibilité du modèle de diffusion pour réparer les parties de l'image qui doivent être modifiées, rendant ainsi le montage vidéo cohérent avec les pixels d'origine inchangés.
Traduction vidéo
L'une des principales applications du modèle est la traduction vidéo. Dans ce cas, VLOGGER prend la vidéo existante dans une langue spécifique et modifie les lèvres et les zones du visage pour les aligner sur le nouvel audio (par exemple l'espagnol).
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Décrivez brièvement quelle est l'unité de stockage des données dans un ordinateur ?
- Quelles sont les caractéristiques 4V du big data ?
- Quelles sont les caractéristiques du big data ?
- Quelle est la vitesse à laquelle un ordinateur télécharge des données ?
- Comment réparer l'éditeur vidéo Windows 11 lorsque l'audio personnalisé ne fonctionne pas correctement ?