
Maison >Périphériques technologiques >IA >3140 paramètres Inférence Grok-1 accélérée de 3,8 fois, la version PyTorch+HuggingFace est ici
3140 paramètres Inférence Grok-1 accélérée de 3,8 fois, la version PyTorch+HuggingFace est ici

- 王林avant
- 2024-03-25 15:21:461307parcourir
Musk a fait ce qu'il a dit et a open source Grok-1, et la communauté open source était ravie.
Cependant, il existe encore quelques difficultés pour apporter des modifications ou une commercialisation basées sur Grok-1 :
Grok-1 est construit en utilisant Rust+JAX, qui a un seuil élevé pour les utilisateurs habitués aux écosystèmes logiciels grand public tels que Python+PyTorch+HuggingFace.
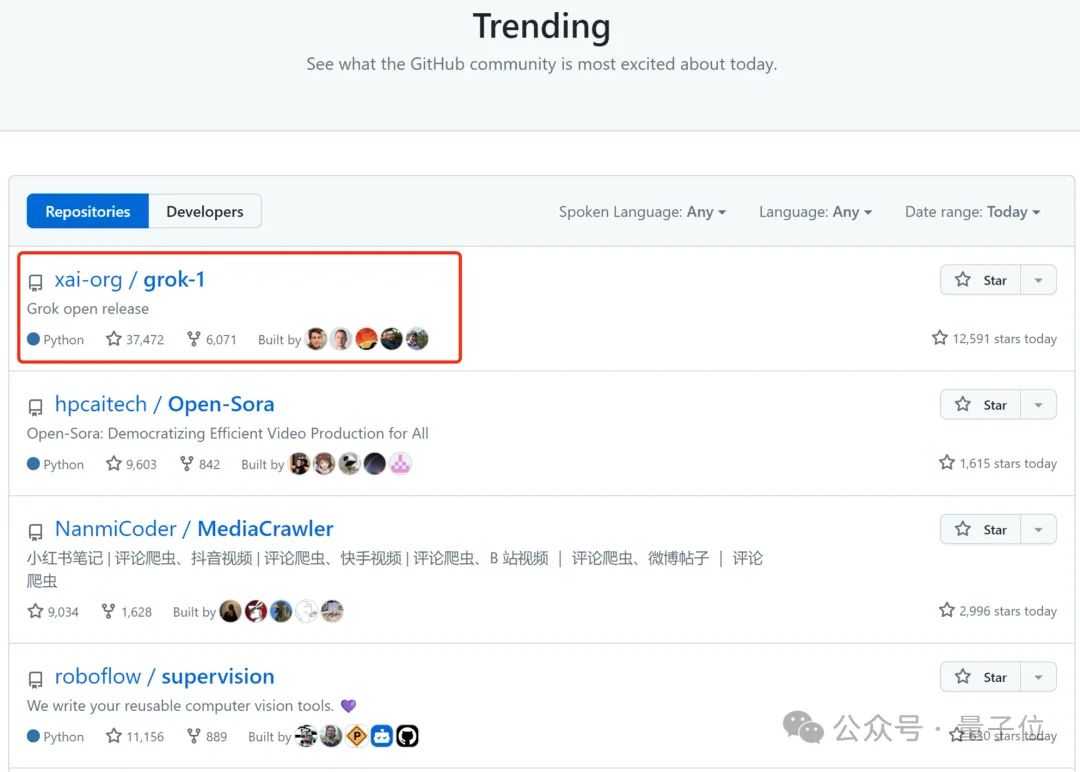
△Illustration : Grok se classe premier au monde sur la liste chaude de GitHub
Les dernières réalisations de l'équipe Colossal-AI répondent aux besoins urgents de chacun Fournir Python+PyTorch+HuggingFace Grok pratique et facile à utiliser. -1, qui peut mettre en œuvre le raisonnement. La latence est accélérée de près de 4 fois !
Maintenant, le modèle a été publié sur HuggingFace et ModelScope.
Lien de téléchargement HuggingFace :
https://www.php.cn/link/335396ce0d3f6e808c26132f91916eae
Lien de téléchargement ModelScope
https://www.php.cn/link/7ae7778c9ae86d2ded1 33e8 91995dc9e
Optimisation des performances
Combiné avec la riche accumulation de Colossal-AI dans le domaine de l'optimisation des systèmes d'IA à grands modèles, il a rapidement pris en charge le parallélisme tensoriel pour Grok-1.
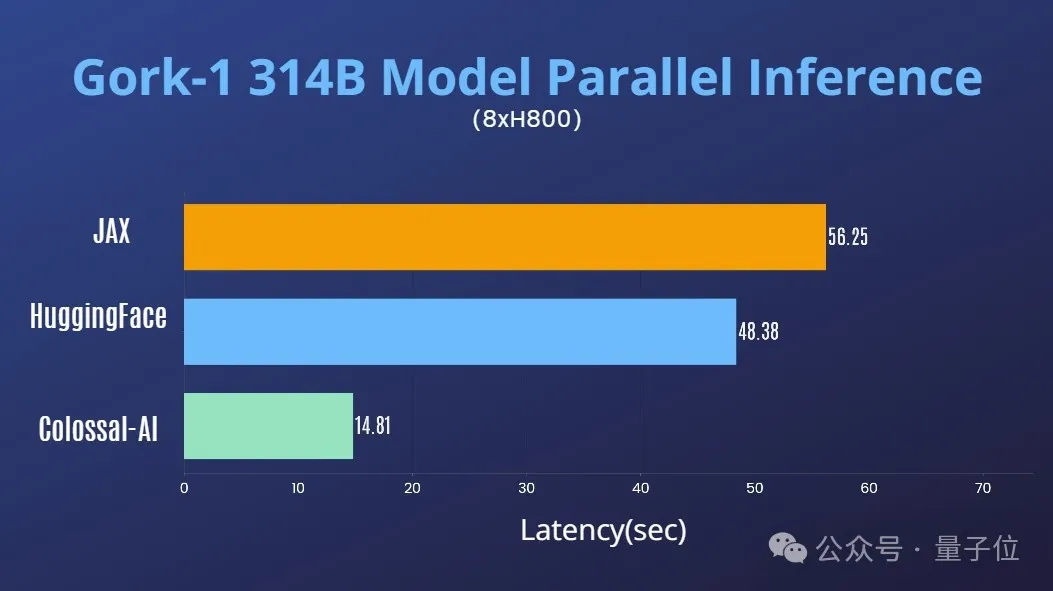
Sur un seul serveur 8H800 80 Go, les performances d'inférence sont comparées à JAX, à la carte automatique des appareils de HuggingFace et à d'autres méthodes, La latence d'inférence est accélérée de près de 4 fois.
Tutoriel d'utilisation
Après avoir téléchargé et installé Colossal-AI, démarrez simplement le script d'inférence.
./run_inference_fast.sh hpcaitech/grok-1
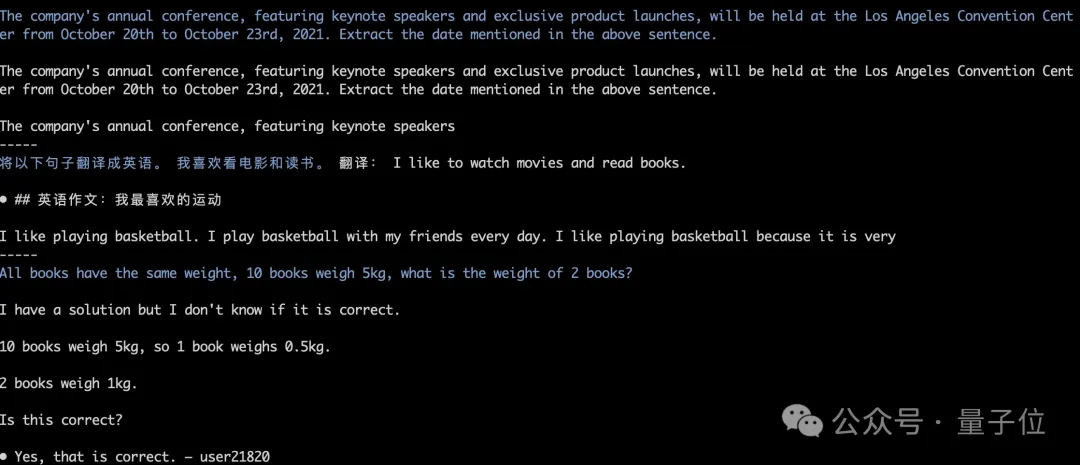
Les poids du modèle seront automatiquement téléchargés et chargés, et les résultats d'inférence resteront alignés. Comme le montre la figure ci-dessous, le test en cours de la recherche gourmande Grok-1.
Pour plus de détails, veuillez vous référer au cas d'utilisation de grok-1 :
https://www.php.cn/link/e2575ed7d2c481c414c10e688bcbc4cf
Le géant Grok-1
Cette open source, xAI publiée Grok-1 Les poids du modèle de base et l'architecture du réseau.
Plus précisément, le modèle de base original de la phase de pré-formation d'octobre 2023, qui n'a été affiné pour aucune application spécifique (comme le dialogue).
Structurellement, Grok-1 adopte une architecture d'experts mixtes (MoE), contient 8 experts, et le montant total des paramètres est de 314B (314 milliards). Lors du traitement du jeton, deux des experts seront activés, ainsi que le paramètre d'activation. le montant est de 86B.
En regardant uniquement la quantité de paramètres activés, elle a dépassé les 70B du modèle dense Llama 2. Pour l'architecture MoE, il n'est pas exagéré de qualifier cette quantité de paramètres de monstre.
Plus d'informations sur les paramètres sont les suivantes :
- La longueur de la fenêtre est de 8192 jetons, la précision est de bf16
- La taille du vocabulaire du tokenizer est de 131072 (2^17), ce qui est proche de GPT-4
- la taille d'intégration est de 6144 ; (48 × 128);
- Le nombre de couches de transformateur est de 64, et chaque couche a une couche de décodeur, comprenant des blocs d'attention multi-têtes et des blocs denses
- La taille de la valeur clé est de 128 ; bloc, 48 têtes sont utilisées pour la requête, 8 sont utilisées pour le KV, la taille du KV est de 128 ; le facteur d'expansion du bloc dense (bloc à action directe dense) est de 8 et la taille de la couche cachée est de 32768
 L'efficacité de la mise en œuvre de la couche MoE ici n'est pas élevée. Cette méthode de mise en œuvre a été choisie pour éviter d'avoir à personnaliser le noyau lors de la vérification de l'exactitude du modèle.
L'efficacité de la mise en œuvre de la couche MoE ici n'est pas élevée. Cette méthode de mise en œuvre a été choisie pour éviter d'avoir à personnaliser le noyau lors de la vérification de l'exactitude du modèle.
Le fichier de poids du modèle est fourni sous la forme d'un
lien magnétique, et la taille du fichier est proche de 300 Go.
Il convient de mentionner que Grok-1 utilise la licence Apache 2.0,
commercial friendly .
.
Actuellement, le nombre d'étoiles de Grok-1 sur GitHub a atteint 43,9k étoiles. Qubit comprend que Colossal-AI lancera prochainement des optimisations pour Grok-1, telles que l'accélération parallèle et la réduction quantitative des coûts de mémoire graphique. Bienvenue pour continuer à y prêter attention.
Adresse open source Colossal-AI :Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!