
Maison >Périphériques technologiques >IA >WorldGPT est là : créez un agent d'IA vidéo de type Sora, 'ressuscitez' les graphiques et le texte
WorldGPT est là : créez un agent d'IA vidéo de type Sora, 'ressuscitez' les graphiques et le texte

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-22 08:30:441399parcourir
Sora d'OpenAI a fait des débuts époustouflants en février de cette année, apportant une nouvelle percée dans les vidéos générées par texte. Il peut créer des vidéos incroyablement réalistes et imaginatives basées sur la saisie de texte qui semblent provenir d'Hollywood. De nombreuses personnes ont été émerveillées par cette innovation et pensent que les performances d'OpenAI ont atteint le summum.
L'engouement provoqué par Sora se poursuit sans relâche. Dans le même temps, les chercheurs ont commencé à prendre conscience de l'énorme potentiel de la technologie de génération vidéo IA, et ce domaine attire de plus en plus d'attention.
Cependant, dans le domaine actuel de la génération de vidéos IA, la plupart des recherches sur les algorithmes se concentrent sur la génération de vidéos via des invites de texte, en particulier les scénarios dans lesquels des images et du texte sont combinés, n'ont pas été discutés en profondeur ni largement appliqués. Ce biais réduit la variété et la contrôlabilité des vidéos générées et limite la capacité de convertir des images statiques en vidéos dynamiques.
D'un autre côté, la plupart des modèles de génération vidéo existants ne prennent pas en charge la possibilité de modification du contenu vidéo généré et ne peuvent pas répondre aux besoins des utilisateurs en matière d'ajustements personnalisés des vidéos générées.


Astuces : Transformez le panda en ours et faites-le danser. (Changez le panda en ours et faites-le danser.)
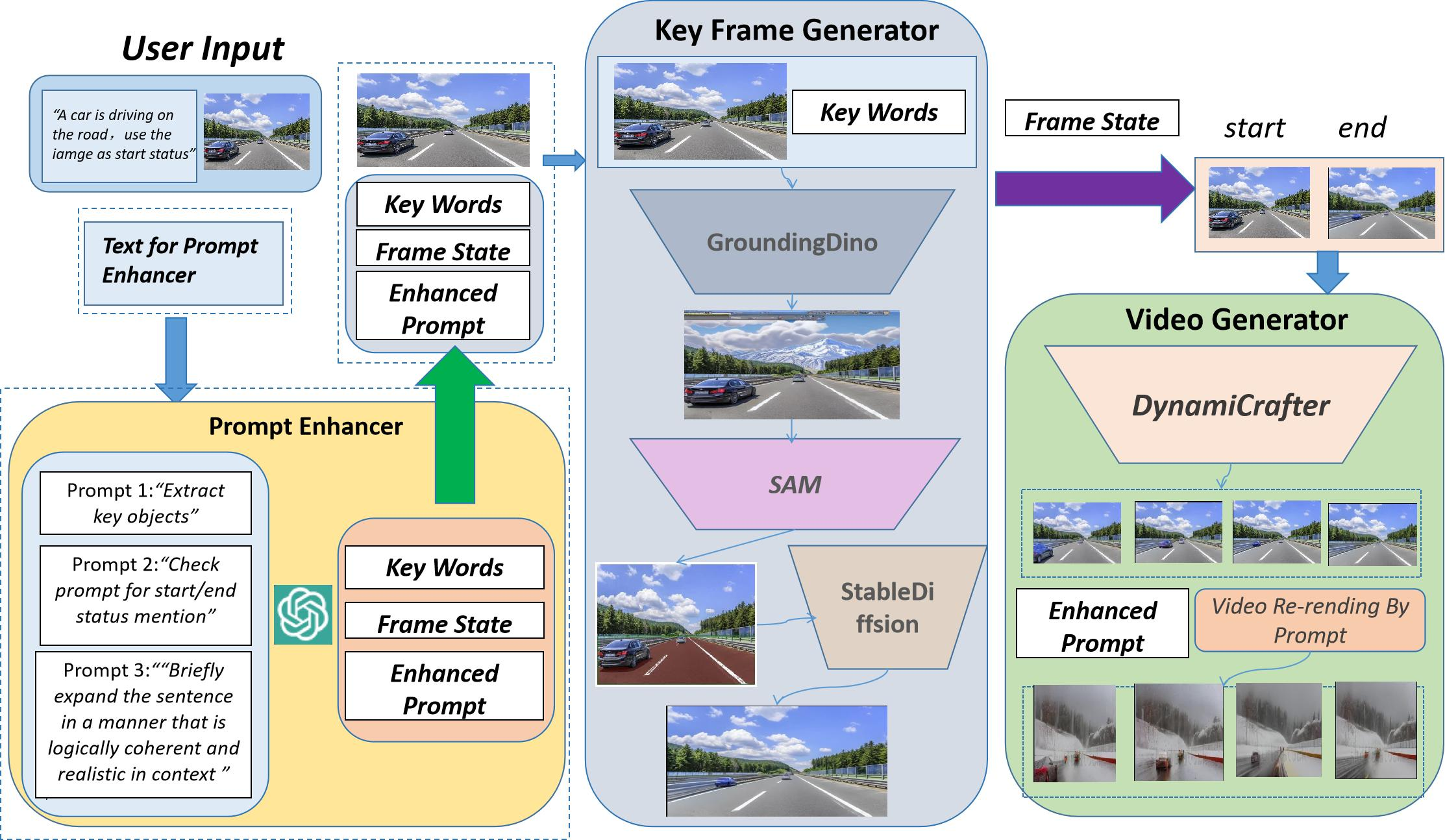
Dans cet article, des chercheurs de SEEKING AI, de l'Université Harvard, de l'Université Stanford et de l'Université de Pékin ont proposé conjointement un cadre unifié innovant pour la génération et l'édition de vidéos basées sur des images et du texte. nommé WorldGPT. Ce cadre est construit sur le cadre VisionGPT développé conjointement par SEEKING AI et les meilleures universités mentionnées ci-dessus. Il peut non seulement réaliser la fonction de génération directe de vidéos à partir d'images et de texte, mais également prendre en charge le transfert de style et le remplacement de l'arrière-plan des vidéos générées. des invites de texte simples (invite) et une série d'opérations d'édition d'apparence vidéo.
Un autre avantage important de ce framework est qu'il ne nécessite pas de formation, ce qui abaisse considérablement le seuil technique et rend également le déploiement et l'utilisation très pratiques. Les utilisateurs peuvent utiliser directement le modèle pour créer sans prêter attention au processus de formation fastidieux qui le sous-tend.

- Adresse de l'article : https://arxiv.org/pdf/2403.07944.pdf
- Titre de l'article : WorldGPT : un agent d'IA vidéo inspiré de Sora en tant que modèles du monde riche à partir d'entrées de texte et d'images
Ensuite jetez un œil aux exemples de démonstrations de WorldGPT dans divers scénarios complexes de contrôle de génération vidéo.
Remplacement de l'arrière-plan + Générer une vidéo
Invite : "Une flotte de navires avançait à travers la tempête hurlante, leurs voiles naviguant sur les énormes vagues de la tempête impitoyable, leurs voiles gonflées alors qu'ils naviguaient sur les vagues imposantes de la tempête incessante.)》


Remplacement de l'arrière-plan + Stylisation + Générer une vidéo
Invite : "Un dragon mignon dans les rues de la ville qui respire du feu. (Un dragon mignon crache du feu dans une rue urbaine.) "


Remplacement d'objet + Remplacement d'arrière-plan + Générer une vidéo
Conseils : "Un robot de style cyberpunk éclairé par des néons Un automate de style cyberpunk a couru à travers le paysage urbain dystopique éclairé par des néons, des reflets de des hologrammes imposants et une dégradation numérique projetés sur son corps métallique élégant.)》


Comme le montre l'exemple ci-dessus, WorldGPT présente les avantages suivants face à une vidéo complexe. instructions de génération :
1) Il conserve mieux la structure et l'environnement de l'image d'origine ;
2) Génère une vidéo générée conforme à la description du texte de l'image, montrant de puissantes capacités de personnalisation de la génération vidéo ; la vidéo générée peut être personnalisée et modifiée via une invite.
Pour en savoir plus sur les principes, les expériences et les cas d'utilisation de WorldGPT, veuillez consulter l'article original.
VisonGPT
Comme mentionné précédemment, le framework WorldGPT est construit sur le framework VisionGPT. Ensuite, nous présentons brièvement des informations sur VisionGPT.
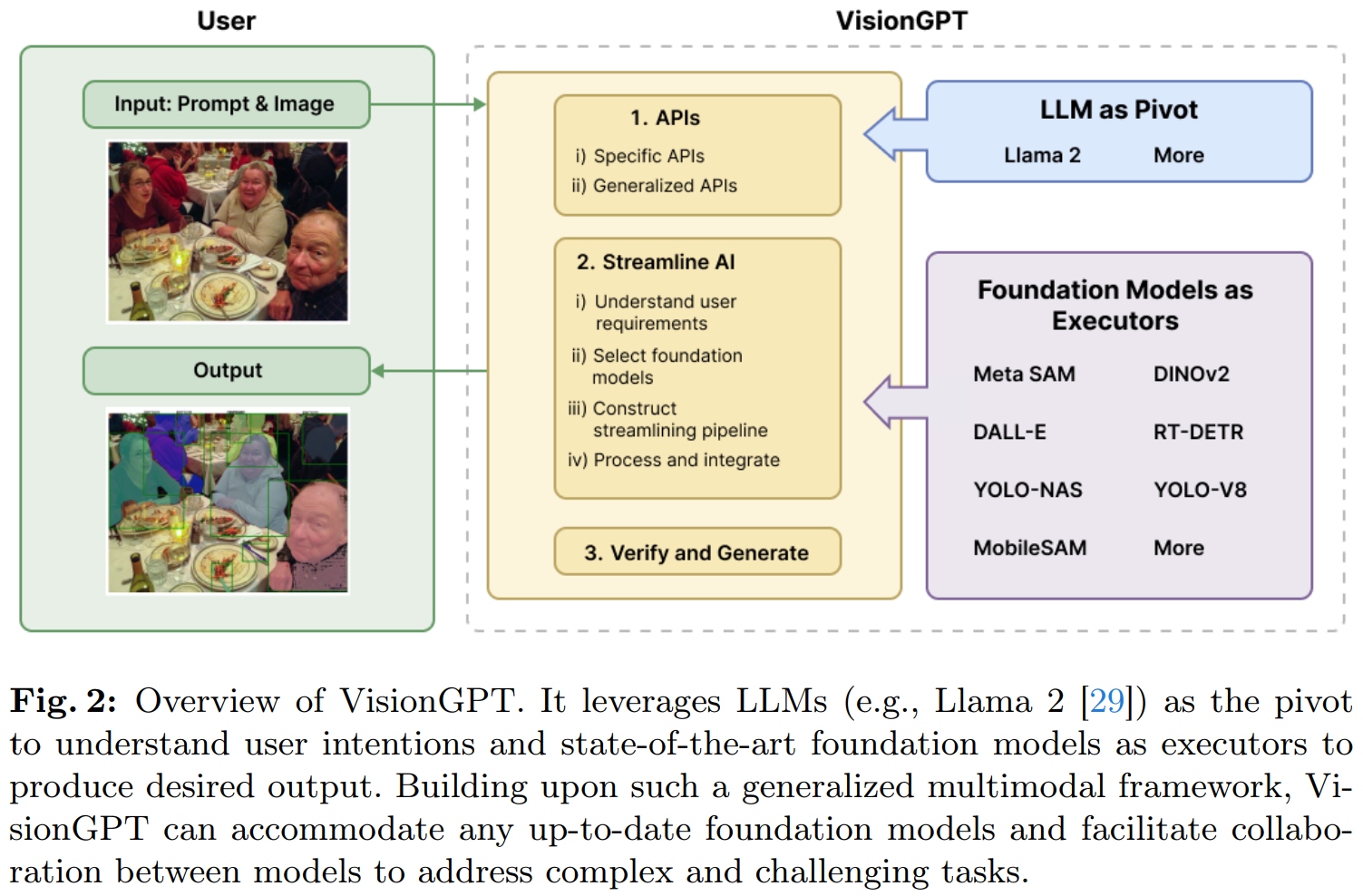
VisionGPT est développé conjointement par SeekingAI, l'Université de Stanford, l'Université Harvard, l'Université de Pékin et d'autres institutions de renommée mondiale. Il s'agit d'un cadre de grand modèle révolutionnaire de perception visuelle en monde ouvert. Le cadre offre de puissantes capacités de traitement d'images multimodales d'IA grâce à une intégration intelligente et à une sélection décisionnelle de grands modèles SOTA de pointe.
L'innovation de VisionGPT se reflète principalement dans trois aspects :
- Premièrement, il prend un grand modèle de langage (tel que LLaMA-2) comme noyau, décompose la demande rapide de l'utilisateur en exigences d'étape détaillées et appelle automatiquement le plus Les grands modèles appropriés sont traités ;
- Deuxièmement, VisionGPT accepte et fusionne automatiquement la sortie multimodale générée à partir de plusieurs grands modèles SOTA pour générer des résultats de traitement d'image adaptés aux besoins de l'utilisateur.
- Enfin, VisionGPT a une flexibilité et une polyvalence extrêmement élevées, sans avoir besoin ; permettant aux utilisateurs d'affiner le modèle, peut prendre en charge un large éventail de scénarios d'application, notamment la compréhension, la génération et l'édition d'images basées sur le texte.

- Adresse de l'article : https://arxiv.org/pdf/2403.09027.pdf
- Titre de l'article : VisionGPT : Vision-Language Understanding Agent utilisant un cadre multimodal généralisé
Cas d'utilisation de VisionGPT

Comme le montre ce qui précède, VisionGPT peut facilement réaliser 1) une segmentation d'instances de monde ouvert sans réglage fin ; 2) des fonctions de génération et d'édition d'images basées sur des invites, etc. Le flux de travail de VisionGPT est illustré dans la figure ci-dessous.
Pour plus de détails, veuillez vous référer au journal.
VisionGPT-3D
De plus, les chercheurs ont également lancé VisionGPT-3D, qui vise à résoudre un défi majeur dans la conversion de texte en éléments visuels : comment convertir efficacement et précisément des images 2D en représentations 3D. Dans ce processus, nous sommes souvent confrontés au problème de l’inadéquation entre l’algorithme et les besoins réels, affectant ainsi la qualité du résultat final. VisionGPT-3D propose un cadre multimodal qui optimise ce processus de conversion en intégrant plusieurs grands modèles de vision SOTA de pointe. Sa principale innovation réside dans sa capacité à sélectionner automatiquement le modèle visuel SOTA et l'algorithme de création de nuages de points 3D les plus appropriés, et à générer une sortie qui répond le mieux aux besoins des utilisateurs sur la base d'entrées multimodales telles que des invites textuelles.

- Adresse de l'article : https://arxiv.org/pdf/2403.09530v1.pdf
- Titre de l'article : VisionGPT-3D : un agent multimodal généralisé pour une compréhension améliorée de la vision 3D
Pour plus d'informations, veuillez consulter au papier original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tutoriel d'auto-apprentissage h5 : 6 didacticiels d'auto-apprentissage html5 à base zéro recommandés, adaptés aux débutants
- Tutoriel d'introduction à l'utilisation du système Linux
- Tutoriel de démarrage rapide phpstudy v8
- Mise en route : découvrez comment ajouter des effets de dégradé aux images dans PS (partage de connaissances)
- La stabilité de l'IA s'est encore améliorée à pas de géant : une étonnante démonstration de nouvelle génération vidéo, unanimement reconnue par les internautes