
Maison >Périphériques technologiques >IA >Comment écrire du code LoRA à partir de zéro, voici un tutoriel
Comment écrire du code LoRA à partir de zéro, voici un tutoriel

- 王林avant
- 2024-03-20 15:06:45709parcourir
LoRA (Low-Rank Adaptation) est une technique populaire conçue pour affiner les grands modèles de langage (LLM). Cette technologie a été initialement proposée par des chercheurs de Microsoft et incluse dans l'article « LORA : LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS ». LoRA diffère des autres techniques en ce sens qu'au lieu d'ajuster tous les paramètres du réseau neuronal, elle se concentre sur la mise à jour d'un petit nombre de matrices de bas rang, réduisant ainsi considérablement la quantité de calcul requise pour entraîner le modèle.
Étant donné que la qualité du réglage fin de LoRA est comparable à celle du réglage fin du modèle complet, de nombreuses personnes appellent cette méthode un artefact de réglage fin. Depuis sa sortie, de nombreuses personnes sont curieuses de connaître cette technologie et souhaitent écrire du code pour mieux comprendre la recherche. Dans le passé, le manque de documentation appropriée était un problème, mais nous disposons désormais de didacticiels pour vous aider.
L'auteur de ce tutoriel est Sebastian Raschka, un chercheur bien connu en apprentissage automatique et en IA. Il a déclaré que parmi les diverses méthodes efficaces de réglage fin du LLM, LoRA reste son premier choix. À cette fin, Sebastian a écrit un blog "Code LoRA From Scratch" pour construire LoRA à partir de zéro. Selon lui, c'est une bonne méthode d'apprentissage.
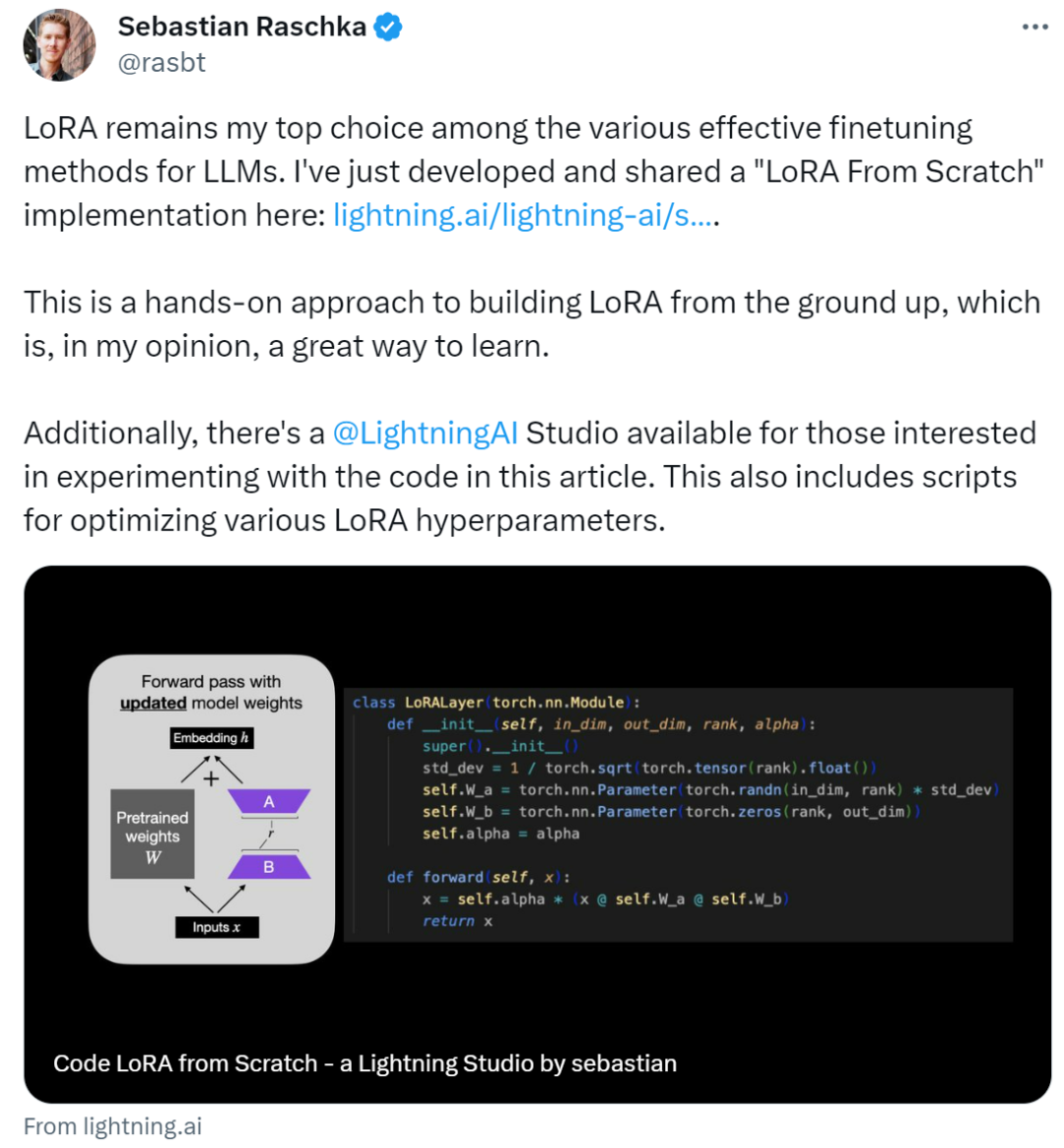
Cet article présente l'adaptation de bas rang (LoRA) en écrivant du code à partir de zéro. Sebastian a affiné le modèle DistilBERT dans l'expérience et l'a appliqué à la tâche de classification.
Les résultats de comparaison entre la méthode LoRA et la méthode de réglage fin traditionnelle montrent que la méthode LoRA atteint 92,39 % en précision de test, ce qui est supérieur au réglage fin uniquement des dernières couches du modèle (précision de test de 86,22 % ) performance. Cela montre que la méthode LoRA présente des avantages évidents dans l'optimisation des performances du modèle et peut mieux améliorer la capacité de généralisation et la précision de prévision du modèle. Ce résultat souligne l'importance d'adopter des techniques et des méthodes avancées lors de la formation et du réglage du modèle pour obtenir de meilleures performances et de meilleurs résultats. En comparant comment
Sebastian y parvient, jetons un coup d'œil ci-dessous.
Écrivez LoRA à partir de zéro
Expliquer une couche LoRA dans le code est comme ceci :
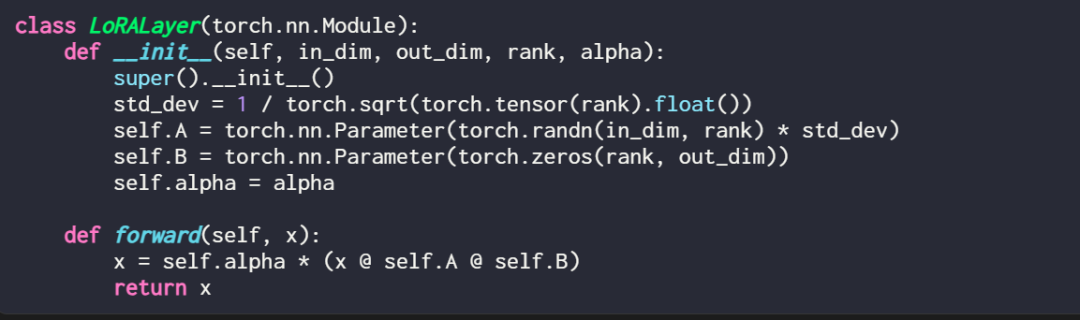
où in_dim est la dimension d'entrée de la couche que vous souhaitez modifier à l'aide de LoRA, correspondant à ce out_dim est la dimension de sortie de la couche. Un hyperparamètre, le facteur d'échelle alpha, est également ajouté au code. Des valeurs alpha plus élevées signifient des ajustements plus importants du comportement du modèle, et des valeurs plus faibles signifient le contraire. De plus, cet article initialise la matrice A avec des valeurs plus petites provenant d'une distribution aléatoire et initialise la matrice B avec des zéros.
Il convient de mentionner que là où LoRA entre en jeu, c'est généralement la couche linéaire (feedforward) d'un réseau neuronal. Par exemple, pour un simple modèle ou module PyTorch avec deux couches linéaires (par exemple, il peut s'agir d'un module feedforward du bloc Transformer), la méthode forward peut être exprimée comme suit :

Lors de l'utilisation de LoRA, elle Il est courant d'ajouter des mises à jour LoRA à la sortie de ces couches linéaires, et le code résultant est le suivant :

Si vous souhaitez implémenter LoRA en modifiant un modèle PyTorch existant, un moyen simple consiste à chaque couche linéaire est remplacé par une couche LinearWithLoRA :
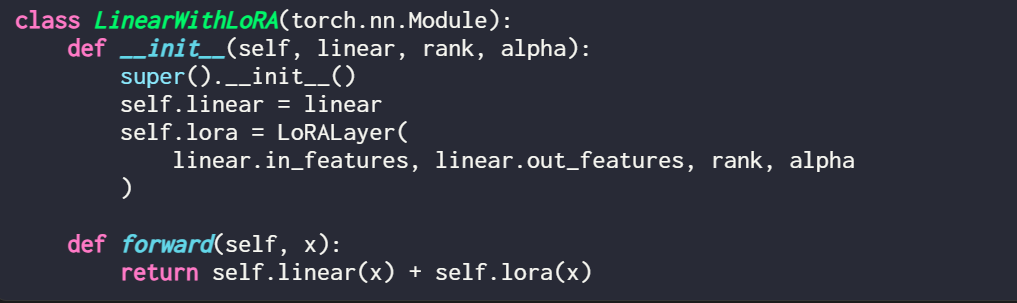
Les concepts ci-dessus sont résumés dans la figure ci-dessous :
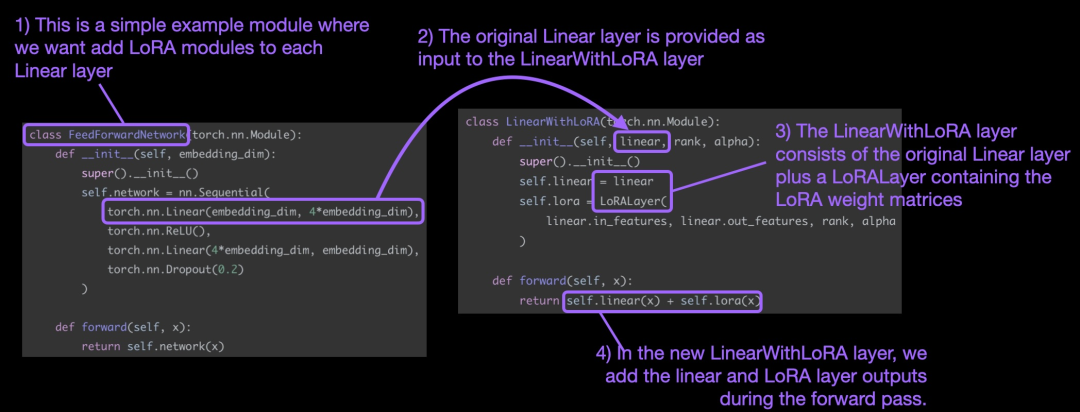
Afin d'appliquer LoRA, cet article remplace les couches linéaires existantes dans le réseau neuronal par une combiné La couche linéaire d'origine et la couche LinearWithLoRA de LoRALayer.
Comment commencer à utiliser LoRA pour un réglage précis
LoRA peut être utilisé pour des modèles tels que GPT ou la génération d'images. Pour une explication simple, cet article utilise un petit modèle BERT (DistilBERT) pour la classification de texte.

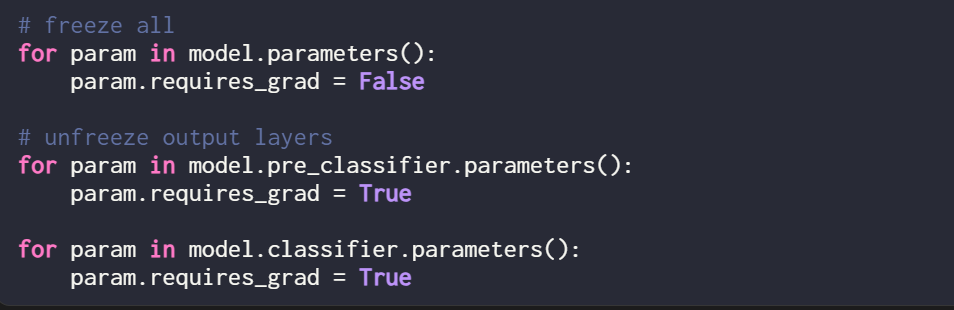
Étant donné que cet article entraîne uniquement de nouveaux poids LoRA, vous devez définir require_grad de tous les paramètres entraînables sur False pour geler tous les paramètres du modèle :

Ensuite, utilisez print (model) pour vérifier le modèle. structure de :

On peut voir sur la sortie que le modèle se compose de 6 couches de transformateur, dont des couches linéaires :

De plus, le modèle a deux couches de sortie linéaires :

LoRA peut éventuellement être activé pour ces couches linéaires en définissant la fonction d'affectation et la boucle suivantes :
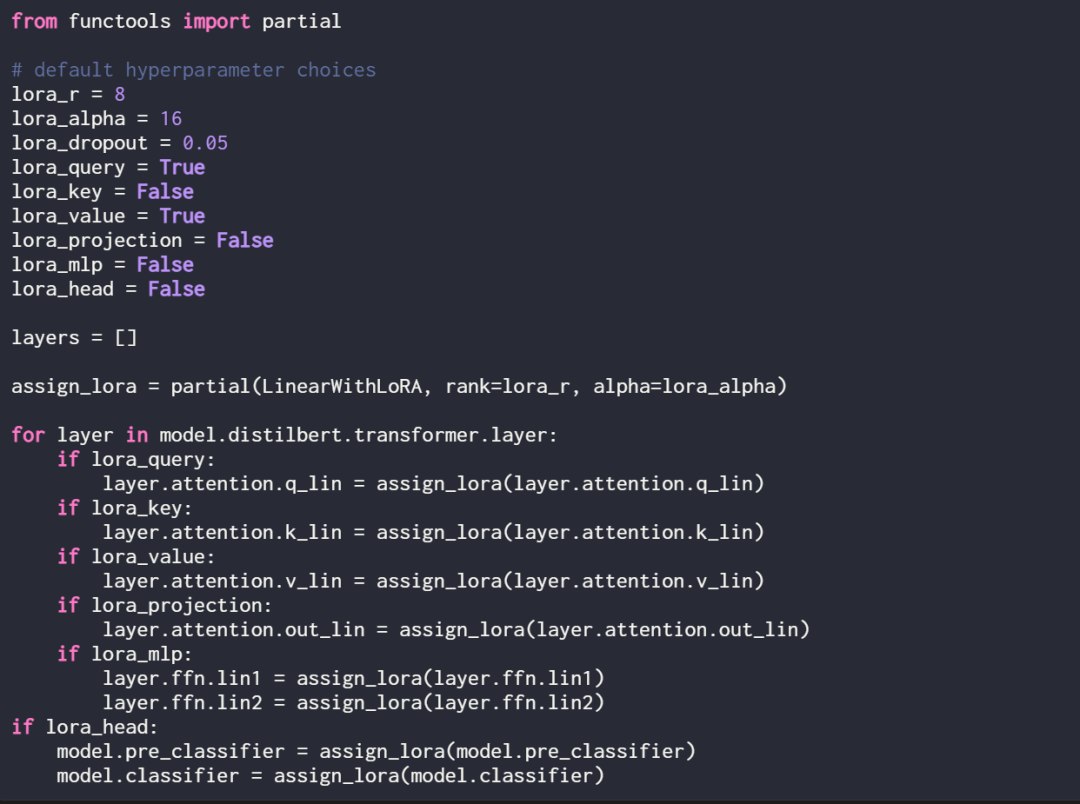
Vérifiez à nouveau le modèle en utilisant print (model) pour vérifier sa structure mise à jour :
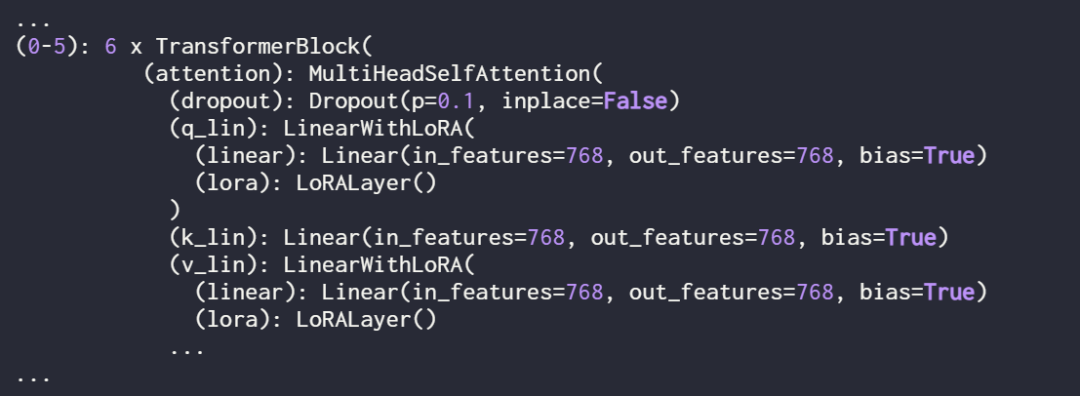
Comme vous pouvez le voir ci-dessus, le calque Linear a été remplacé avec succès par le calque LinearWithLoRA. 92,15 %
Précision du test : 89,44 %
- Dans la section suivante, cet article compare ces résultats de réglage fin LoRA avec les résultats de réglage fin traditionnels.
- Comparaison avec les méthodes de réglage fin traditionnelles
- Dans la section précédente, LoRA a atteint une précision de test de 89,44 % avec les paramètres par défaut. Comment cela se compare-t-il aux méthodes de réglage fin traditionnelles ?
La performance de classification obtenue en entraînant uniquement les deux dernières couches est la suivante :
Précision de l'entraînement : 86,68 %
Précision de la validation : 87,26 %
Précision du test : 86,22 %
- Les résultats montrent que LoRA fonctionne mieux que la méthode traditionnelle de réglage fin des deux dernières couches, mais elle utilise 4 fois moins de paramètres . Le réglage fin de toutes les couches a nécessité la mise à jour de 450 fois plus de paramètres que la configuration LoRA, mais n'a amélioré la précision des tests que de 2 %.
- Optimiser la configuration LoRA
- Les résultats mentionnés ci-dessus sont tous effectués par LoRA avec les paramètres par défaut. Les hyperparamètres sont les suivants :
Si l'utilisateur souhaite essayer différentes configurations d'hyperparamètres, vous pouvez. utilisez la commande suivante :
Cependant, la configuration optimale des hyperparamètres est la suivante :

Sous cette configuration, le résultat est :
- Précision de validation : 92,96 %
- Précision du test : 92,39 %
Il convient de noter que même s'il n'y a qu'un petit ensemble de paramètres entraînables dans le réglage LoRA (500k VS 66M), la précision est encore légèrement supérieure à la précision obtenue avec un réglage fin complet.
Lien original : https://lightning.ai/lightning-ai/studios/code-lora-from-scratch?cnotallow=f5fc72b1f6eeeaf74b648b2aa8aaf8b6
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment convertir ai en ps
- Comment faire apparaître la barre d'attributs AI
- qu'est-ce que l'IA
- Retour vers le futur ! En utilisant des journaux d'enfance pour entraîner l'IA, ce programmeur a utilisé GPT-3 pour établir un dialogue avec son « moi passé »
- Formation personnalisée de modèles d'apprentissage profond à l'aide de techniques d'apprentissage par transfert