

 tutoriels informatiquesconnaissances en informatiqueDix discussions sur la programmation réseau Linux haute performance
tutoriels informatiquesconnaissances en informatiqueDix discussions sur la programmation réseau Linux haute performanceDix discussions sur la programmation réseau Linux haute performance

Les dix blogs techniques de "Ten Talks on Linux High-Performance Network Programming" sont rédigés depuis plusieurs mois. J'ai pensé écrire un résumé pour passer en revue mon travail au cours des dernières années. a presque 8 ans Même si j'ai passé beaucoup de temps à travailler sur les vis, j'ai quand même beaucoup appris de mon expérience dans l'évolution de l'architecture haute performance, de la participation, de l'optimisation jusqu'à la conception finale de l'architecture.

1. Conception en avance ou évolution métier ?
Tout le monde devrait avoir expérimenté le processus d'un projet de 0 à 1. Je voudrais poser une question : dans de nombreux cas, l'architecture évolue-t-elle avec l'entreprise ou est-elle conçue à l'avance
?Certaines personnes ont peut-être étudié des livres d'architecture connexes. La plupart de ces livres pensent que l'architecture évolue avec le développement des affaires. Cependant, de nombreux architectes insistent également sur le fait que l’architecture doit être conçue à l’avance. Ici, je ne tirerai pas de conclusions pour l’instant, mais explorerai l’évolution de l’architecture à travers ma propre expérience.
2. Du PHP au C++
2.1 Architecture PHP simple
PHP, en tant que langage simple et pratique, devrait être présent dans tous les départements des grandes usines. A cette époque, j'utilisais deux langages pour travailler : C++ et PHP. Utiliser PHP pour développer des fonctions est très rapide, et là. Il existe de nombreuses bibliothèques matures, elles ont donc formé l'architecture classique nginx
+php-fpm+memcache.
 architecture php
architecture php
Dans l'architecture actuelle, ce n'est pas un gros problème pour une seule machine 8c8g de prendre en charge 1000qps, donc pour l'entreprise, c'est actuellement moins de 1wqps. Évidemment, quelques machines supplémentaires peuvent le prendre en charge. Concernant la conception de la couche de cache, lorsque Redis n'était pas encore bien développé, memcache était le composant de cache principal à cette époque, et il était simple pour les entreprises et s'arrimait à PHP. Cependant, avec le développement de l'activité, selon la courbe de calcul de l'époque, cela pourrait atteindre 5wqps d'ici un an. Est-il raisonnable d'utiliser l'architecture nginx + php-fpm + memcache ? Après discussion, l'objectif est la haute performance du serveur ? côté, nous avons donc commencé un voyage de découverte haute performance.
À cette époque, afin de mettre en œuvre un framework côté serveur hautes performances, les gens ont essayé certaines solutions. L'une d'entre elles consistait à utiliser la fonction de plug-in PHP pour intégrer les fonctions du serveur dans le langage de script. Cette approche atteint dans une certaine mesure l’objectif de haute performance. Par exemple, le swole de PHP est désormais un résultat de développement de cette méthode.
serveur-php
- Soyez familier avec les scénarios d'utilisation des extensions PHP pour éviter les pièges
- Problème de fuite de mémoire dans l'utilisation de PHP lui-même
- Le coût du dépannage lorsqu'un problème survient. Par exemple, lorsqu'un problème survient, nous avons parfois besoin de comprendre le code source PHP, mais avec des centaines de milliers de lignes de code, ce coût est assez élevé
- PHP est simple à utiliser. C'est en fait relativement vrai avec l'essor de Docker, l'ère du stand-alone va inévitablement passer.
- …
- Sur la base de la réflexion et de l'analyse du développement commercial ci-dessus, il est en fait plus raisonnable pour nous d'implémenter un serveur nous-mêmes ou d'utiliser le framework C++ existant pour implémenter un ensemble de serveurs de couche métier. Par conséquent, après réflexion, nous avons adopté le framework SPP de l'entreprise. , dont l'architecture est la suivante :
 On peut voir que SPP est une architecture multi-processus. Son architecture est similaire à celle de Nginx et est divisée en processus Proxy et processus Worker, parmi lesquels :
On peut voir que SPP est une architecture multi-processus. Son architecture est similaire à celle de Nginx et est divisée en processus Proxy et processus Worker, parmi lesquels :
Le processus proxy utilise handle_init pour effectuer l'initialisation, handle_route est transmis au processus de traitement du travailleur d'exécution spécifié et handle_input gère l'entrée de paquet de la requête
- Le processus de travail utilise handle_init pour effectuer l'initialisation, handle_process traite le package et la logique métier et renvoie
- Après avoir utilisé l'architecture C++, les performances sur une seule machine sont directement améliorées à 6 kqps, ce qui répond essentiellement aux exigences de performances. Il semble que l'architecture puisse être stabilisée.
2.3 Présentation des coroutines
L'utilisation de C++ répond aux exigences de performances, mais il existe de nombreux problèmes d'efficacité du développement, tels que l'accès à Redis. Afin de maintenir les hautes performances du service, la logique du code utilise des rappels asynchrones, similaires aux suivants :
... int ret = redis->GetString(k, getValueCallback) ...
GetValueCallback est la fonction de rappel.S'il y a beaucoup d'opérations io, le rappel ici sera très gênant Même s'il est encapsulé dans une méthode de synchronisation similaire, il sera très difficile à gérer à ce moment-là, std::future et. std::async n'ont pas été introduits.
D'un autre côté, étant donné que les qps suivants peuvent atteindre le niveau de 10 ~ 20w, les coroutines auront plus d'avantages dans les performances du traitement des services multi-IO, nous avons donc commencé à transformer la méthode coroutine et à remplacer tous les emplacements io avec des coroutines appelant, pour le développement commercial, le code devient comme ceci :
... int ret = redis->GetString(k, value) ...
La valeur est la valeur de retour qui peut être utilisée directement. Une fois qu'il y aura io dans le code, la couche inférieure remplacera io par l'API de la coroutine de cette façon, toutes les opérations io bloquées deviendront des primitives de synchronisation, une structure de code et. l'efficacité du développement. Les deux se sont beaucoup améliorés (pour une implémentation spécifique de coroutine, veuillez vous référer à la série d'articles "Dix discussions sur la programmation réseau haute performance Linux | Coroutines").
 Coroutine
Coroutine
Il n'y a pas encore beaucoup de changements dans l'architecture. L'approche multi-processus + coroutine soutient le développement commercial depuis plusieurs années. Bien qu'il n'y ait pas de croissance exponentielle des performances, nous avons acquis plus d'expérience dans l'exploration et la précipitation haute performance.
3. Cloud natif
Les affaires continuent de se développer et les ingénieurs recherchent toujours les concepts les plus avancés. Le cloud natif, en tant que point technologique populaire ces dernières années, ne sera naturellement pas ignoré avant de se lancer dans le cloud natif, si votre équipe n'en dispose pas. Concept de développement DevOps, ce sera un processus douloureux qui nécessitera le remboursement de la dette technique sur la conception architecturale et la sélection du cadre.
3.1 Implémenter le concept DevOps
Dans le passé, je considérais la haute performance lorsque je faisais de l'architecture. Grâce à ma compréhension de l'architecture, j'ai découvert que la haute performance n'est qu'un petit domaine de la conception d'une architecture. Si vous voulez construire une bonne architecture, vous avez besoin de processus et de processus plus agiles. concepts de gouvernance des services. Les considérations spécifiques sont résumées comme suit :
- Intégration continue : les développeurs intègrent le code dans un référentiel partagé plusieurs fois par jour, et chaque modification isolée du code est immédiatement testée pour détecter et prévenir les problèmes d'intégration
- Livraison continue : la livraison continue (CD) garantit que chaque version du code testée dans le référentiel CI est prête à être publiée
- Déploiement continu : cela inclut le déploiement en niveaux de gris, la version bleu-vert, etc. Le but est d'itérer rapidement après des tests d'intégration relativement complets, une vérification en niveaux de gris peut être réalisée .
- Découverte de services : transformez les services en microservices pour simplifier les appels entre services
- Cadre RPC : le cadre de serveur qui recherche des performances élevées doit également prendre en compte la prise en charge de composants de base tels que la limitation de courant et les disjoncteurs
- Système de surveillance : intégré à Promethues, OpenTracing et d'autres fonctions, il peut découvrir rapidement les problèmes en ligne dans le processus de développement agile
- Conteneurisation : Afin d'unifier l'environnement et d'envisager à l'avance des scénarios cloud natifs, la conteneurisation est essentielle dans le processus de développement
- …
 DevOps
DevOps
À ce stade, vous constaterez qu'un simple serveur hautes performances est devenu l'objectif de l'architecture, il est donc nécessaire de réexaminer et de concevoir l'architecture pour mettre en œuvre avec succès le concept DevOps.
3.2 Multi-threading
Basé sur DevOps, combiné au framework C++ Server ci-dessus, il s'avère que le multi-processus ne peut plus répondre aux besoins de l'architecture. Les raisons sont les suivantes :
.- Les processus multiples sont incompatibles avec le concept de processus unique des conteneurs Docker
- La charge du processus de travail est inégale, comment mieux utiliser le multicœur
- Interface efficace avec le système de surveillance
- La configuration métier est chargée à plusieurs reprises et le centre de configuration doit être réadapté
- Il n'est pas très raisonnable d'utiliser plusieurs processus pour fournir des services avec état
- …
L'activité est également passée à un million de QPS. Afin d'améliorer la gestion des services et les coûts des appels de service, nous devons envisager une autre architecture :
.(1)Recherche gRPC
 gRPC
gRPC
gRPC est un serveur RPC
multithread. Il dispose d'un écosystème mature, de divers middlewares, prend en charge plusieurs langues, etc. C'est un bon choix pour le développement commercial de 0 à 1, mais il est confronté à des défis de migration d'entreprise, tels que le développement. votre propre service d'adaptation Middleware découverte, centre de configuration, etc., protocole de transformation selon encodage et décodage personnalisé, comment combiner les coroutines, etc., pour qu'il puisse satisfaire certaines entreprises, mais il doit encore être mieux intégré au RPC
Serveur des composants de l'entreprise.
(2)Utilisez tRPC
Il se trouve que le tRPC était en cours de développement dans l'entreprise. Après des recherches, nous avons constaté qu'il répondait essentiellement aux besoins, nous avons donc essayé d'adapter la version C++ du tRPC à notre système dans les premières étapes de développement, le framework RPC haute performance a été migré et utilisé dans le système métier. Désormais, l'architecture du tRPC :
.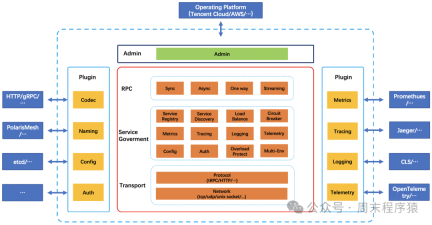
https://trpc.group/zh/docs/what-is-trpc/archtecture_design/
Sur la base des considérations ci-dessus et du développement commercial, nous avons commencé à essayer d'unifier le cadre du serveur RPC sur la base de hautes performances pour nous adapter aux scénarios diversifiés RPC ultérieurs. Nous avons donc implémenté un ensemble de base de serveur RPC
qui s'adapte au cadre de notre système d'entreprise :
 Nouvelle architecture
Nouvelle architecture
3.3. Aller aux k8s
Après avoir effectué la sélection et la transformation ci-dessus, nos services peuvent être connectés étape par étape lors de la migration vers k8s. Le service n'a pas besoin de subir trop de transformations pour fonctionner sur sa plateforme, et chaque plateforme à laquelle il est connecté peut également l'être. entièrement pris en charge.
Il semble que vous puissiez simplement rechercher des technologies plus récentes et attendre la prochaine tendance ? En fait, il y a plus de défis en ce moment en raison de la commodité du cloud et de l'expansion désordonnée de l'architecture des services de migration, les services commerciaux et les niveaux logiques sont. De plus en plus complexes. Dans le même temps, les liens en aval sur lesquels repose un service sont de plus en plus longs. Bien que notre cadre prenne en charge le suivi des liens, plus le lien est long, plus la contrôlabilité et la stabilité du service se détériorent. davantage sera gaspillé. Le soutien humain pour les opérations quotidiennes.
Que faire ?…
Devrions-nous fusionner la logique métier et simplifier l'architecture ? Le problème ici est que lorsque la logique métier est complexe, le cycle prend souvent beaucoup de temps, et du point de vue des coûts, il est relativement élevé et les avantages ne sont pas très importants
Devrions-nous re-développer une nouvelle architecture, conserver celles qui sont délabrées telles qu'elles sont ou les abandonner, et utiliser une nouvelle architecture pour s'adapter au prochain développement.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Façons universelles d'activer les onglets d'explorateur de fichiers sur Windows 10Apr 10, 2025 am 10:17 AM
Façons universelles d'activer les onglets d'explorateur de fichiers sur Windows 10Apr 10, 2025 am 10:17 AMLa fonctionnalité des onglets dans File Explorer est une fonction très pratique pour les utilisateurs de Windows, mais il n'est pas disponible sur Windows 10. Néanmoins, vous pouvez activer les onglets dans File Explorer sur Windows à l'aide d'applications tierces comme des fichiers. Dans cet article, logiciel php.cn
 La barre des tâches du lait automatique ne fonctionne-t-elle pas sur Windows 11? Voici des correctifs!Apr 10, 2025 am 10:16 AM
La barre des tâches du lait automatique ne fonctionne-t-elle pas sur Windows 11? Voici des correctifs!Apr 10, 2025 am 10:16 AMWindows offre une option pour masquer automatiquement la barre des tâches lorsque vous ne l'utilisez pas. Cependant, certains utilisateurs rapportent qu'ils répondent au problème «la barre des tâches de lait automatique ne fonctionnant pas dans Windows 11». Cet article de Php.cn fournit des solutions.
 Correction des meilleurs pour l'installation du code d'erreur de défaillance du pilote audio RealtekApr 10, 2025 am 10:15 AM
Correction des meilleurs pour l'installation du code d'erreur de défaillance du pilote audio RealtekApr 10, 2025 am 10:15 AMAvez-vous déjà rencontré le message d'erreur disant «Installer le code d'erreur de défaillance du pilote audio RealTek 0001» tout en essayant d'installer un pilote audio RealTek? Si oui, vous êtes au bon endroit. Ce message sur le logiciel php.cn explique comment obtenir ce PR
 Comment désactiver les notifications de pare-feu Windows (3 façons)Apr 10, 2025 am 10:14 AM
Comment désactiver les notifications de pare-feu Windows (3 façons)Apr 10, 2025 am 10:14 AMLa notification du pare-feu Windows continue de surgir? Comment désactiver les notifications de pare-feu Windows? Maintenant, vous pouvez obtenir trois façons éprouvées de ce post sur PHP.CN pour empêcher les notifications de pare-feu de surgir.
 Guide: comment supprimer définitivement les fichiers du disque dur externeApr 10, 2025 am 10:13 AM
Guide: comment supprimer définitivement les fichiers du disque dur externeApr 10, 2025 am 10:13 AMVous voulez vendre ou jeter votre disque externe mais vous vous inquiétez de la fuite de données? Les fichiers de disque dur externes supprimés continuent de réapparaître? Comment supprimer définitivement les fichiers du disque dur externe? Ce message sur php.cn vous montre des moyens sécurisés de supprimer
 Comment corriger le service de liste réseau CPU HIGH? Quatre solutions iciApr 10, 2025 am 10:12 AM
Comment corriger le service de liste réseau CPU HIGH? Quatre solutions iciApr 10, 2025 am 10:12 AMLes utilisateurs d'ordinateurs peuvent rencontrer des problèmes d'utilisation de CPU élevés, même s'ils n'exécutent pas trop de programmes sur les ordinateurs. Parfois, ce problème peut être résolu automatiquement, cependant, dans certains cas, vous devez résoudre le problème manuellement, comme le service de liste de réseau
 Les fichiers USB se sont transformés en fichiers EXE? Récupérer les fichiers et supprimer le virusApr 10, 2025 am 10:11 AM
Les fichiers USB se sont transformés en fichiers EXE? Récupérer les fichiers et supprimer le virusApr 10, 2025 am 10:11 AMUn lecteur flash USB fonctionne comme le périphérique de stockage de données le plus utilisé de nos jours. Cependant, il est facile d'être infecté par divers virus car vous le connectez à différents appareils pour transférer des fichiers. Lorsque vous trouvez vos fichiers USB transformés en fichiers EXE, y
 Un guide complet - l'arrière-plan de bureau Windows 11 continue de changerApr 10, 2025 am 10:10 AM
Un guide complet - l'arrière-plan de bureau Windows 11 continue de changerApr 10, 2025 am 10:10 AML'arrière-plan de bureau Windows 11 continue de changer et chaque fois que vous personnalisez les paramètres du fond d'écran, Windows 11 reviendra les modifications. C'est ennuyeux et cet article sur le site Web php.cn présentera certaines méthodes qui se sont avérées utiles F


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Télécharger la version Mac de l'éditeur Atom
L'éditeur open source le plus populaire

Adaptateur de serveur SAP NetWeaver pour Eclipse
Intégrez Eclipse au serveur d'applications SAP NetWeaver.

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Listes Sec
SecLists est le compagnon ultime du testeur de sécurité. Il s'agit d'une collection de différents types de listes fréquemment utilisées lors des évaluations de sécurité, le tout en un seul endroit. SecLists contribue à rendre les tests de sécurité plus efficaces et productifs en fournissant facilement toutes les listes dont un testeur de sécurité pourrait avoir besoin. Les types de listes incluent les noms d'utilisateur, les mots de passe, les URL, les charges utiles floues, les modèles de données sensibles, les shells Web, etc. Le testeur peut simplement extraire ce référentiel sur une nouvelle machine de test et il aura accès à tous les types de listes dont il a besoin.

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

