
Maison >Périphériques technologiques >IA >Pour protéger la confidentialité des clients, exécutez localement des modèles d'IA open source à l'aide de Ruby
Pour protéger la confidentialité des clients, exécutez localement des modèles d'IA open source à l'aide de Ruby

- 王林avant
- 2024-03-18 21:40:03693parcourir
Traducteur | Chen Jun
Chonglou
Récemment, nous avons mis en œuvre un projet d'intelligence artificielle (IA) personnalisé. Étant donné que la partie A détient des informations client très sensibles, pour des raisons de sécurité, nous ne pouvons pas les transmettre à OpenAI ou à d'autres modèles propriétaires. Par conséquent, nous avons téléchargé et exécuté un modèle d'IA open source dans une machine virtuelle AWS, en le gardant entièrement sous notre contrôle. Dans le même temps, les applications Rails peuvent effectuer des appels API à l'IA dans un environnement sûr. Bien entendu, si des problèmes de sécurité ne doivent pas être pris en compte, nous préférerions coopérer directement avec OpenAI.

Ci-dessous, je vais partager avec vous comment télécharger le modèle d'IA open source localement, le laisser s'exécuter et comment exécuter le script Ruby dessus.
Pourquoi personnaliser ?
La motivation de ce projet est simple : la sécurité des données. Lors du traitement d’informations client sensibles, l’approche la plus fiable consiste généralement à le faire au sein de l’entreprise. Par conséquent, nous avons besoin de modèles d’IA personnalisés pour jouer un rôle en fournissant un niveau plus élevé de contrôle de sécurité et de protection de la vie privée.
Modèle Open source
Au cours des 6 derniers mois, de nouveaux produits sont apparus sur le marché tels que : Mistral, Mixtral et Lamaetc. Un grand nombre de modèles d'IA open source. Bien qu'ils ne soient pas aussi puissants que GPT-4, les performances de beaucoup d'entre eux ont dépassé GPT-3.5, et ils deviendront de plus en plus puissants au fil du temps. Bien entendu, le modèle que vous choisissez dépend entièrement de vos capacités de traitement et de ce que vous devez réaliser.
Étant donné que nous exécuterons le modèle d'IA localement, nous avons sélectionné le Mistral qui fait environ 4 Go. Il surpasse GPT-3.5 sur la plupart des métriques. Bien que Mixtral soit plus performant que Mistral, il s'agit d'un modèle volumineux qui nécessite au moins 48 Go de mémoire pour fonctionner.
Paramètres
Quand on parle de grands modèles de langage (LLM), nous avons tendance à penser à mentionner la taille de leurs paramètres. Ici, le modèle Mistral que nous exécuterons localement est un modèle de 7 milliards de paramètres (bien sûr, Mixtral a 700 milliards de paramètres, et GPT-3.5 Il y a environ 1750 milliards de paramètres).
En règle générale, les grands modèles de langage utilisent des techniques basées sur les réseaux neuronaux. Les réseaux de neurones sont constitués de neurones et chaque neurone est connecté à tous les autres neurones de la couche suivante.
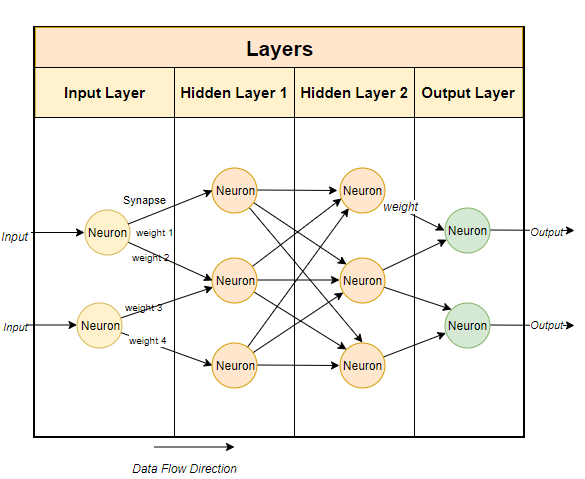
Le but du réseau neuronal est « d'apprendre » un algorithme avancé, un algorithme de correspondance de modèles. En étant formé sur de grandes quantités de texte, il apprendra progressivement la capacité de prédire les modèles de texte et de répondre de manière significative aux signaux que nous lui donnons. En termes simples, les paramètres sont le nombre de poids et de biais dans le modèle. Cela nous donne une idée du nombre de neurones présents dans un réseau neuronal. Par exemple, pour un modèle de
7 milliards de paramètres, il y a environ 100 couches, chacune contenant des milliers de neurones. Exécutez le modèle localement
Pour exécuter le modèle open source localement, vous devez d'abord télécharger l'application appropriée. Bien qu'il existe de nombreuses options sur le marché, celle que je trouve la plus simple et la plus simple à exécuter sur Intel
Macest Ollama. Bien que
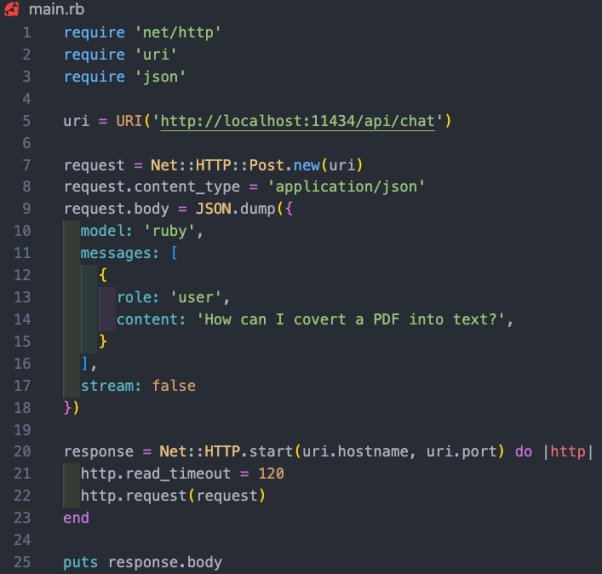
Ollama ne fonctionne actuellement que sur Mac et Linux, il fonctionnera également sur Windows à l'avenir. Bien sûr, vous pouvez utiliser WSL (sous-système Windows pour Linux) pour exécuter Linux shell sur Windows. Ollama vous permet non seulement de télécharger et d'exécuter divers modèles open source, mais ouvre également le modèle sur un port local, vous permettant de passer des appels API via le code Ruby. Cela permet aux développeurs Ruby d'écrire des applications Ruby qui peuvent être intégrées aux modèles locaux. puisque Olllama est principalement basé sur la ligne de commande, il est très simple d'installer Olllama sur les systèmes Mac et Linux. Il vous suffit de télécharger Ollama via le lien https://www.php.cn/link/04c7f37f2420f0532d7f0e062ff2d5b5, de consacrer environ 5 minutes pour installer le progiciel, puis d'exécuter le modèle. Après avoir configuré et exécuté Ollama, vous verrez l'icône Ollama dans la barre des tâches de votre navigateur. Cela signifie qu'il s'exécute en arrière-plan et peut exécuter votre modèle. Pour télécharger le modèle, vous pouvez ouvrir un terminal et exécuter la commande suivante : Puisque Mistral a une taille d'environ 4 Go, cela vous prendra un certain temps pour terminer le téléchargement. Une fois le téléchargement terminé, il ouvrira automatiquement l'invite Ollama pour que vous puissiez interagir et communiquer avec Mistral. La prochaine fois que vous exécuterez mistral via Ollama, vous pourrez exécuter directement le modèle correspondant. Similaire à la façon dont nous créons un GPT personnalisé dans OpenAI, via Ollama, vous pouvez personnaliser le modèle de base. Ici, nous pouvons simplement créer un modèle personnalisé. Pour des cas plus détaillés, veuillez vous référer à la documentation en ligne d'Ollama. Tout d'abord, vous pouvez créer un Modelfile (fichier modèle) et y ajouter le texte suivant : Le message système qui apparaît ci-dessus est la base de la réponse spécifique de l'IA. modèle. Ensuite, vous pouvez exécuter la commande suivante sur le terminal pour créer un nouveau modèle : Dans notre cas de projet, j'ai nommé le modèle Ruby . En même temps, vous pouvez utiliser la commande suivante pour lister et afficher vos modèles existants : Bien qu'Ollama ne dispose pas encore de gem dédiée, les développeurs Ruby peuvent utiliser des méthodes de requête HTTP de base pour interagir avec les modèles. Ollama fonctionnant en arrière-plan peut ouvrir le modèle via le port 11434, vous pouvez donc y accéder via "https://www.php.cn/link/dcd3f83c96576c0fd437286a1ff6f1f0". De plus, la documentation de l'API OllamaAPI fournit également différents points de terminaison pour les commandes de base telles que les conversations de chat et la création d'intégrations. Dans ce cas de projet, nous souhaitons utiliser le point de terminaison /api/chat pour envoyer des invites au modèle d'IA. L'image ci-dessous montre un Rubycode de base pour interagir avec le modèle : Fonctionnalité de ce qui précède Rubyl'extrait de code comprend : Comme mentionné ci-dessus, la véritable valeur de l'exécution de modèles d'IA locaux est d'aider les entreprises qui détiennent des données sensibles, traitent des données non structurées telles que des e-mails ou des documents et extraient des informations structurées précieuses. . Dans le cas du projet auquel nous avons participé, nous avons effectué une formation modèle sur toutes les informations client dans le système de gestion de la relation client (CRM). À partir de là, les utilisateurs peuvent poser toutes les questions qu’ils ont sur leurs clients sans avoir à parcourir des centaines d’enregistrements. Introduction du traducteur Julian Chen, rédacteur de communauté 51CTO, a plus de dix ans d'expérience dans la mise en œuvre de projets informatiques, est doué pour contrôler les ressources et les risques internes et externes et se concentre sur la communication Connaissance et expérience en matière de sécurité des réseaux et de l’information. Titre original : Comment exécuter des modèles d'IA open source localement avec Ruby, auteur : Kane Hooper
Obtenez ollama
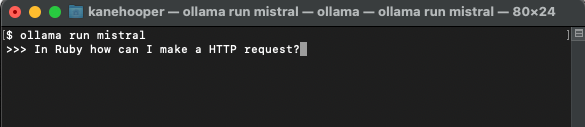
Installation de votre premier modèle
ollama run mistral
Modèle personnalisé
FROM mistral# Set the temperature set the randomness or creativity of the responsePARAMETER temperature 0.3# Set the system messageSYSTEM ”””You are an excerpt Ruby developer. You will be asked questions about the Ruby Programminglanguage. You will provide an explanation along with code examples.”””
ollama create <model-name> -f './Modelfile</model-name>
ollama create ruby -f './Modelfile'
ollama list
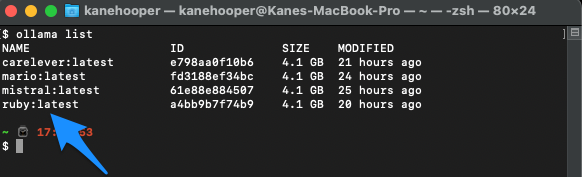
Ollama run ruby
Intégré à Ruby
Résumé du cas
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!