
Maison >Périphériques technologiques >IA >Nouveaux travaux sur la prédiction de séries chronologiques + grand modèle NLP : générer automatiquement des invites implicites pour la prédiction de séries chronologiques
Nouveaux travaux sur la prédiction de séries chronologiques + grand modèle NLP : générer automatiquement des invites implicites pour la prédiction de séries chronologiques

- 王林avant
- 2024-03-18 09:20:101141parcourir
Aujourd'hui, je souhaite partager un travail de recherche récent de l'Université du Connecticut qui propose une méthode pour aligner les données de séries chronologiques avec de grands modèles de traitement du langage naturel (NLP) sur l'espace latent afin d'améliorer l'effet de prévision des séries chronologiques. La clé de cette méthode consiste à utiliser des indices spatiaux latents (invites) pour améliorer la précision des prévisions de séries chronologiques.

Titre de l'article : S2IP-LLM : Semantic Space Informed Prompt Learning with LLM for Time Series Forecasting
Adresse de téléchargement : https://www.php.cn/link/3695d85c350d924e662ea2cd3b760d40
1. Contexte du problème
Les grands modèles sont de plus en plus utilisés dans les séries chronologiques, principalement divisés en deux catégories : la première catégorie utilise diverses données de séries chronologiques pour former son propre grand modèle dans le domaine des séries chronologiques ; la deuxième catégorie utilise directement des textes formés dans le domaine de la PNL. les modèles sont appliqués aux séries chronologiques. Étant donné que les séries chronologiques sont différentes des images et des textes, différents ensembles de données ont des formats d'entrée et des distributions différents, et il existe des problèmes tels que le changement de distribution, ce qui rend difficile la formation d'un modèle unifié utilisant toutes les données de séries chronologiques. Par conséquent, de plus en plus de travaux ont commencé pour essayer d'utiliser directement les grands modèles de PNL pour résoudre les problèmes liés aux séries chronologiques.
Cet article se concentre également sur la deuxième méthode de résolution de problèmes de séries chronologiques, qui consiste à utiliser de grands modèles NLP. La pratique actuelle utilise souvent une description de la série chronologique comme indice, mais tous les ensembles de données de séries chronologiques ne contiennent pas cette information. De plus, la méthode de traitement des données de séries chronologiques basée sur des correctifs ne peut pas conserver complètement toutes les informations des données de séries chronologiques.
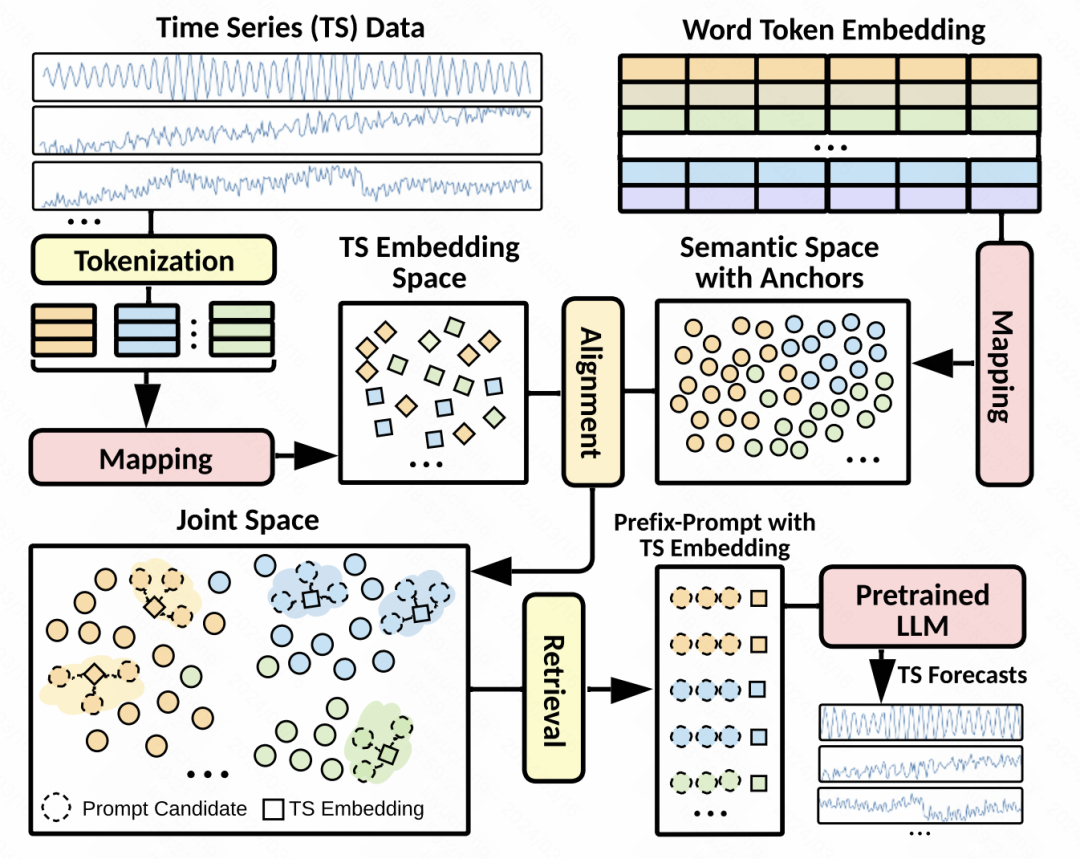
Sur la base des problèmes ci-dessus, cet article propose une nouvelle méthode de modélisation, l'idée de base de la modélisation, d'une part, la série temporelle est mappée en intégration après le traitement de tokenisation, d'autre part, la représentation de ces espaces de séries temporelles est aligné sur un grand Sur le mot intégration dans le modèle. De cette manière, pendant le processus de prédiction de séries chronologiques, les informations liées à l'intégration de mots alignés peuvent être trouvées comme une incitation à améliorer l'effet de prédiction.
 Images
Images
2. Méthode de mise en œuvre
Ce qui suit présente la méthode de mise en œuvre de ce travail sous trois aspects : le traitement des données, l'alignement de l'espace latent et les détails du modèle.
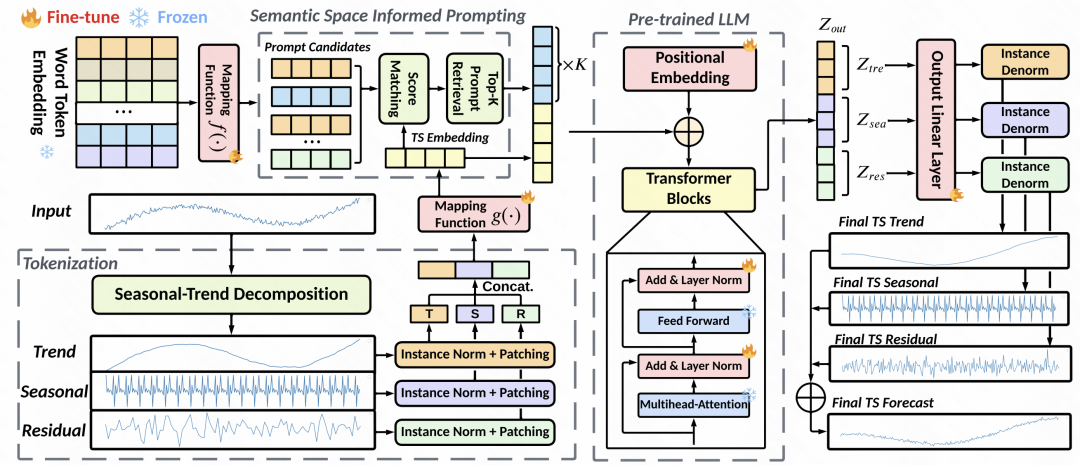
Traitement des données : en raison de problèmes tels que le changement de distribution des séries chronologiques, cet article effectue une décomposition en une étape des éléments de tendance et des éléments saisonniers sur la série d'entrée. Chaque série chronologique décomposée est standardisée séparément puis divisée en patchs qui se chevauchent. Chaque ensemble de correctifs correspond au correctif de terme de tendance, au correctif de terme saisonnier et au correctif résiduel. Ces trois ensembles de correctifs sont assemblés et entrés dans le MLP pour obtenir la représentation d'intégration de base de chaque ensemble de correctifs.
Alignement de l'espace latent : c'est l'étape principale de cet article. La conception des invites a un impact important sur les performances des grands modèles, et les invites de séries chronologiques sont difficiles à concevoir. Par conséquent, cet article propose d'aligner la représentation patch de la série chronologique avec l'intégration de mots du grand modèle dans l'espace latent, puis de récupérer les intégrations de mots topK sous forme d'invites implicites. La méthode spécifique consiste à utiliser l'intégration de correctifs générée à l'étape précédente pour calculer la similarité cosinus avec l'intégration de mots dans le modèle de langage, à sélectionner les intégrations de mots topK, puis à utiliser ces intégrations de mots comme invites pour les coller au début du intégrations de correctifs de séries chronologiques. Comme il existe de nombreuses intégrations de mots dans les grands modèles, afin de réduire la quantité de calcul, nous mappons d'abord les intégrations de mots sur un petit nombre de centres de cluster.
Détails du modèle : en termes de détails du modèle, GPT2 est utilisé comme partie du modèle de langage. À l'exception des paramètres des parties d'intégration de position et de normalisation des couches, le reste est gelé. En plus du MSE, l'objectif d'optimisation introduit également la similitude entre l'intégration du patch et l'intégration du cluster topK récupéré comme contrainte, exigeant que la distance entre les deux soit aussi petite que possible. Les résultats finaux de prédiction sont également des
 images
images
3. Résultats expérimentaux
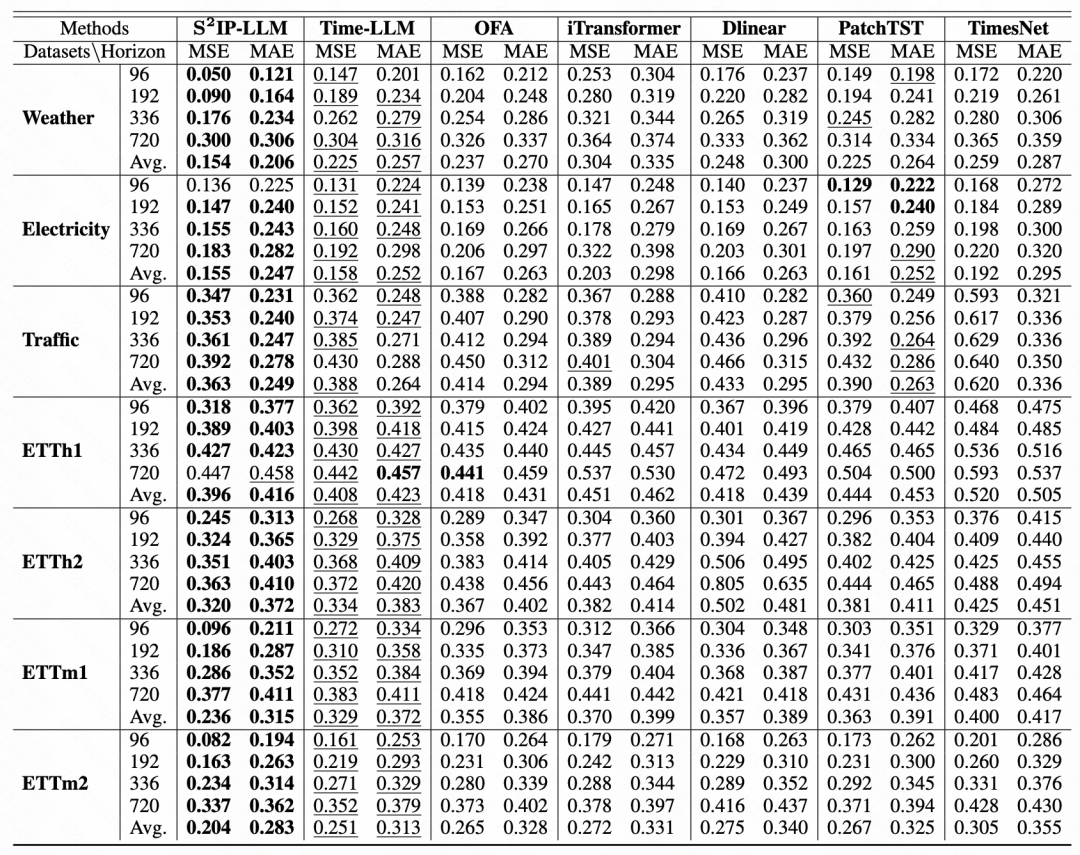
L'article compare les effets de certains modèles de grandes séries chronologiques, iTransformer, PatchTST et autres modèles SOTA, et les prédictions dans différentes fenêtres temporelles de la plupart des données. ensembles Les deux ont obtenu des résultats relativement bons.
 Photo
Photo
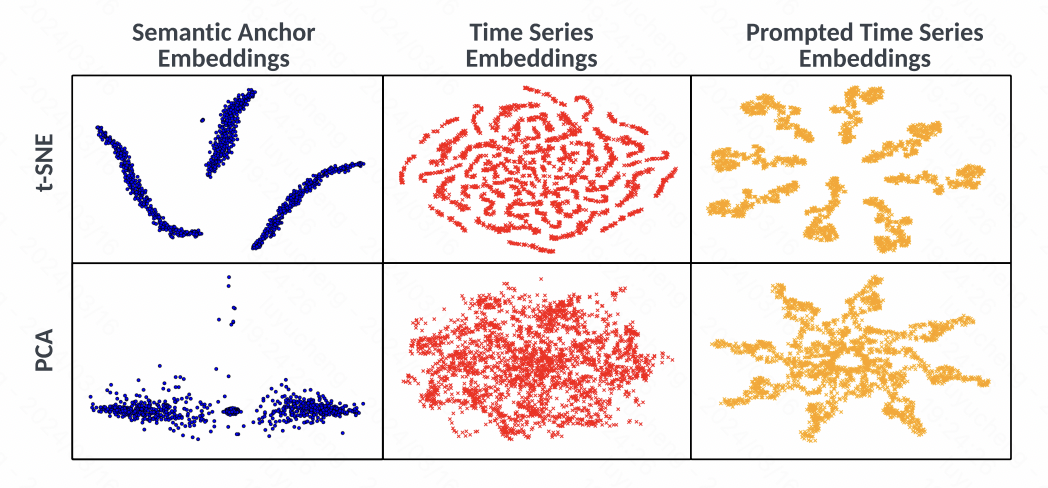
Dans le même temps, l'article analyse également visuellement l'intégration via t-SNE. Comme le montre la figure, l'intégration de la série chronologique ne présente pas de phénomène de regroupement évident avant l'alignement, tandis que l'intégration. généré via l'invite has Les changements évidents dans les clusters indiquent que la méthode proposée dans cet article utilise efficacement l'alignement spatial du texte et des séries chronologiques, ainsi que les invites correspondantes, pour améliorer la qualité de la représentation des séries chronologiques.
 Photos
Photos
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Qu'est-ce qu'un tas ? Quel est le domaine de la méthode ? Introduction à la zone de tas et de méthode dans le modèle de mémoire JVM
- Comment exporter un modèle dans Navicat
- À quel type de modèle de données appartient le serveur SQL ?
- Idées techniques pour implémenter la recherche et l'agrégation de données de séries chronologiques à l'aide de RiSearch PHP