
Maison >Périphériques technologiques >IA >Améliorant les capacités d'apprentissage génératif sans tir, la méthode de prototypage sémantique dynamique visuellement améliorée a été sélectionnée pour le CVPR 2024
Améliorant les capacités d'apprentissage génératif sans tir, la méthode de prototypage sémantique dynamique visuellement améliorée a été sélectionnée pour le CVPR 2024

- 王林avant
- 2024-03-16 09:20:021023parcourir
Bien que je ne vous ai jamais rencontré, il m'est possible de vous « connaître » - c'est l'état que les gens espèrent que l'intelligence artificielle atteigne après le « premier regard ».
Afin d'atteindre cet objectif, dans les tâches traditionnelles de reconnaissance d'images, les gens entraînent des modèles d'algorithmes sur un grand nombre d'échantillons d'images avec différentes étiquettes de catégorie, afin que le modèle puisse acquérir la capacité de reconnaître ces images. Dans la tâche d'apprentissage sans tir (ZSL), les gens espèrent que le modèle pourra tirer des conclusions et identifier les catégories qui n'ont pas vu d'échantillons d'images au cours de la phase de formation.
L'apprentissage zéro-shot (GZSL) est considéré comme une méthode efficace pour l'apprentissage zéro-shot. Dans GZSL, la première étape consiste à former un générateur pour synthétiser les caractéristiques visuelles des catégories invisibles. Ce processus de génération repose sur l'exploitation de descriptions sémantiques telles que les étiquettes d'attribut en tant que conditions. Une fois ces fonctionnalités visuelles virtuelles générées, vous pouvez commencer à former un modèle de classification capable de reconnaître les classes invisibles, tout comme vous le feriez avec un classificateur traditionnel.
La formation du générateur est cruciale pour les algorithmes d'apprentissage génératif zero-shot. Idéalement, les échantillons de caractéristiques visuelles d'une catégorie invisible générés par le générateur sur la base de la description sémantique devraient avoir la même distribution que les caractéristiques visuelles des échantillons réels de cette catégorie. Cela signifie que le générateur doit être capable de capturer avec précision les relations et les modèles entre les caractéristiques visuelles afin de générer des échantillons avec un degré élevé de cohérence et de crédibilité. En entraînant le générateur, il peut apprendre efficacement les différences de caractéristiques visuelles entre les différentes catégories, et
Dans la méthode d'apprentissage générative Zero-shot existante, lorsque le générateur est entraîné et utilisé, il s'agit du bruit gaussien et de la description sémantique globale de les catégories sont conditionnelles, ce qui limite le générateur à optimiser uniquement pour la catégorie entière au lieu de décrire chaque instance d'échantillon, il est donc difficile de refléter avec précision la distribution des caractéristiques visuelles des échantillons réels, ce qui entraîne de mauvaises performances de généralisation du modèle. De plus, les informations visuelles de l'ensemble de données partagées par les classes vues et les classes invisibles, c'est-à-dire les connaissances du domaine, ne sont pas pleinement utilisées dans le processus de formation du générateur, ce qui limite le transfert de connaissances des classes vues vers les classes invisibles.
Afin de résoudre ces problèmes, des étudiants diplômés de l'Université des sciences et technologies de Huazhong et des experts techniques d'Intime Business Group, une filiale d'Alibaba, ont proposé une méthode appelée Visually Enhanced Dynamic Semantic Prototyping (VADS). Cette approche introduit plus complètement les caractéristiques visuelles des classes vues dans les conditions sémantiques, permettant au générateur push d'apprendre des mappages sémantiques-visuels précis. Ce document de recherche « Prototype sémantique dynamique augmenté visuellement pour l'apprentissage génératif Zero-Shot » a été accepté par CVPR 2024, la plus grande conférence universitaire internationale dans le domaine de la vision par ordinateur.
Plus précisément, la recherche ci-dessus présente trois points innovants :
Dans l'apprentissage zéro-shot, les fonctionnalités visuelles sont utilisées pour améliorer le générateur afin de générer des fonctionnalités visuelles fiables, ce qui est une méthode innovante.
La recherche a également introduit deux composants, VDKL et VOSU. À l'aide de ces composants, l'a priori visuel de l'ensemble de données est efficacement obtenu, et en mettant à jour dynamiquement les caractéristiques visuelles de l'image, la description sémantique de la catégorie prédéfinie est. mis à jour . Cette méthode utilise efficacement les fonctionnalités visuelles.
Les résultats expérimentaux montrent que l'effet de l'utilisation de fonctionnalités visuelles pour améliorer le générateur dans cette étude est très significatif. Non seulement cette approche plug-and-play est très polyvalente, mais elle excelle également dans l’amélioration des performances du générateur.
Détails de la recherche
VADS se compose de deux modules : (1) Le module d'apprentissage des connaissances du domaine de perception visuelle (VDKL) apprend les biais locaux et les priorités globales des caractéristiques visuelles, c'est-à-dire les connaissances visuelles du domaine, qui remplacent le bruit gaussien pur. fournit des informations de bruit préalables plus riches ; (2) Le module de mise à jour sémantique orientée vision (VOSU) apprend comment mettre à jour son prototype sémantique en fonction de la représentation visuelle de l'échantillon, et le prototype post-sémantique mis à jour contient également des connaissances visuelles du domaine.
Enfin, l'équipe de recherche a connecté les sorties des deux modules dans un vecteur prototype sémantique dynamique comme condition du générateur. Un grand nombre d'expériences montrent que la méthode VADS atteint des performances nettement meilleures que les méthodes existantes sur des ensembles de données d'apprentissage zéro-shot couramment utilisés, et peut être combinée avec d'autres méthodes d'apprentissage génératives zéro-shot pour obtenir des améliorations générales en termes de précision.
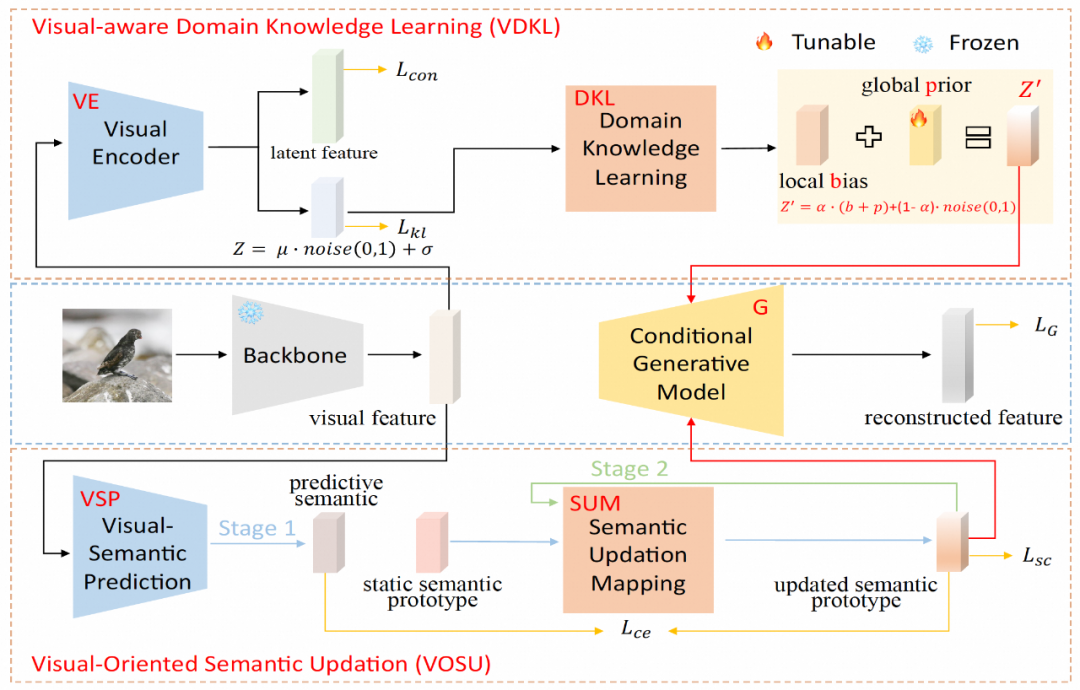
Dans le module d'apprentissage des connaissances du domaine de la perception visuelle (VDKL), l'équipe de recherche a conçu un encodeur visuel (VE) et un réseau d'apprentissage des connaissances du domaine (DKL). Parmi eux, VE code les caractéristiques visuelles en caractéristiques latentes et en codage latent. En utilisant la perte contrastive pour entraîner VE à l'aide d'échantillons d'images de classe vues pendant la phase de formation du générateur, VE peut améliorer la séparabilité de classe des caractéristiques visuelles.
Lors de la formation du classificateur ZSL, les caractéristiques visuelles invisibles générées par le générateur sont également entrées dans VE, et les caractéristiques latentes obtenues sont connectées aux caractéristiques visuelles générées en tant qu'échantillon final de caractéristiques visuelles. L'autre sortie de VE, c'est-à-dire le codage latent, forme un écart local b après la transformation DKL, qui est combiné avec l'a priori global apprenable et le bruit gaussien aléatoire en un bruit a priori visuel lié au domaine pour remplacer d'autres échantillons zéro purs génératifs. Bruit gaussien couramment utilisé en apprentissage dans le cadre des conditions de génération du générateur.
Dans le module de mise à jour sémantique orientée vision (VOSU), l'équipe de recherche a conçu un prédicteur sémantique visuel VSP et un réseau de cartographie de mise à jour sémantique SUM. Dans la phase de formation de VOSU, VSP prend les caractéristiques visuelles de l'image en entrée pour générer un vecteur sémantique prédit qui peut capturer le modèle visuel de l'image cible. En même temps, SUM prend le prototype sémantique de catégorie en entrée, le met à jour et l'obtient. le prototype sémantique mis à jour, puis VSP et SUM sont formés en minimisant la perte d'entropie croisée entre le vecteur sémantique prédit et le prototype sémantique mis à jour. Le module VOSU peut ajuster dynamiquement le prototype sémantique en fonction des fonctionnalités visuelles, permettant au générateur de s'appuyer sur des informations sémantiques plus précises au niveau de l'instance lors de la synthèse de nouvelles fonctionnalités de catégorie.
Dans la partie expérimentale, la recherche ci-dessus a utilisé trois ensembles de données ZSL couramment utilisés dans le monde universitaire : Animals with Attributes 2 (AWA2), SUN Attribute (SUN) et Caltech-USCD Birds-200-2011 (CUB), pour les méthodes traditionnelles. Les principaux indicateurs de l’apprentissage zéro-shot et de l’apprentissage zéro-shot généralisé sont comparés de manière exhaustive avec d’autres méthodes représentatives récentes.
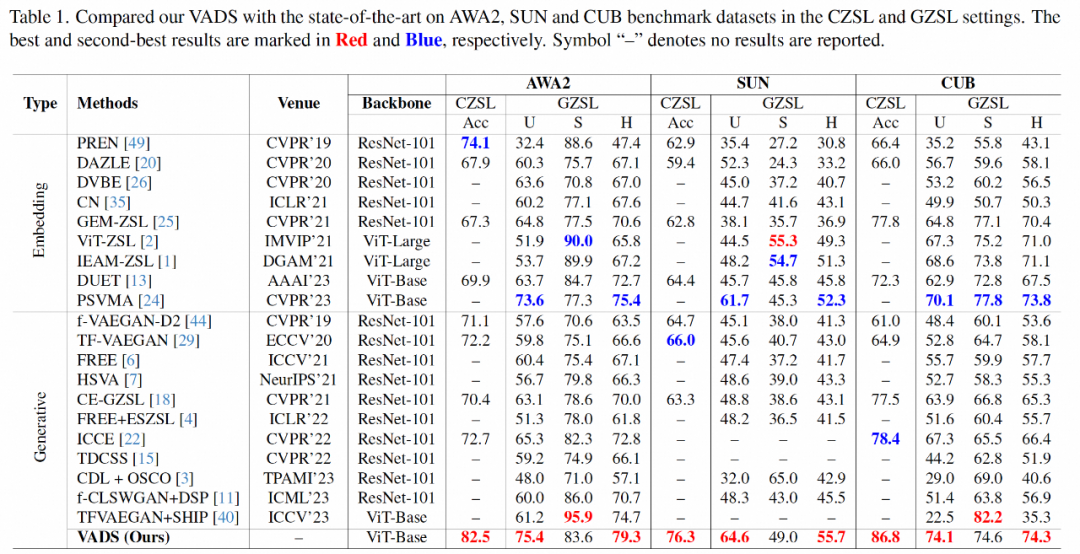
En termes d'indicateur Acc de l'apprentissage traditionnel sans tir, la méthode de cette étude a obtenu des améliorations significatives de la précision par rapport aux méthodes existantes, menant respectivement de 8,4 %, 10,3 % et 8,4 sur les trois ensembles de données. %. Dans le scénario d'apprentissage généralisé sans tir, la méthode de recherche ci-dessus occupe également une position de leader en ce qui concerne l'indice moyen harmonique H de la classe invisible et la précision de la classe vue.
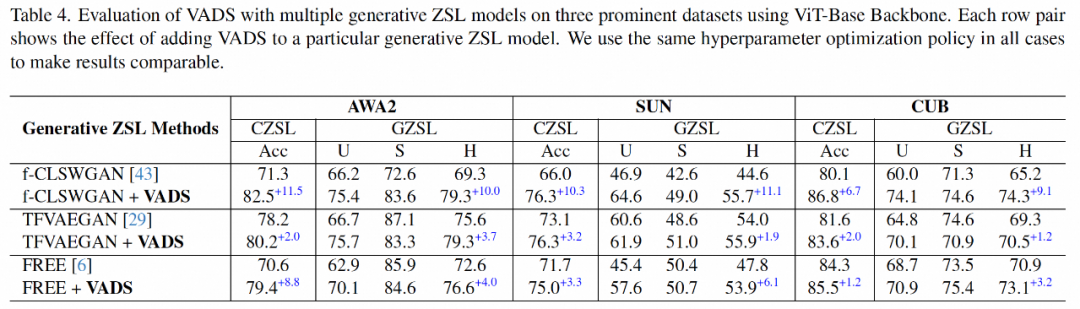
La méthode VADS peut également être combinée avec d'autres méthodes d'apprentissage génératif zero-shot. Par exemple, après combinaison avec les trois méthodes CLSWGAN, TF-VAEGAN et FREE, les indicateurs Acc et H sur les trois ensembles de données sont significativement améliorés et l'amélioration moyenne des trois ensembles de données est de 7,4 %/5,9 %, 5,6 %. /6,4% et 3,3%/4,2%.
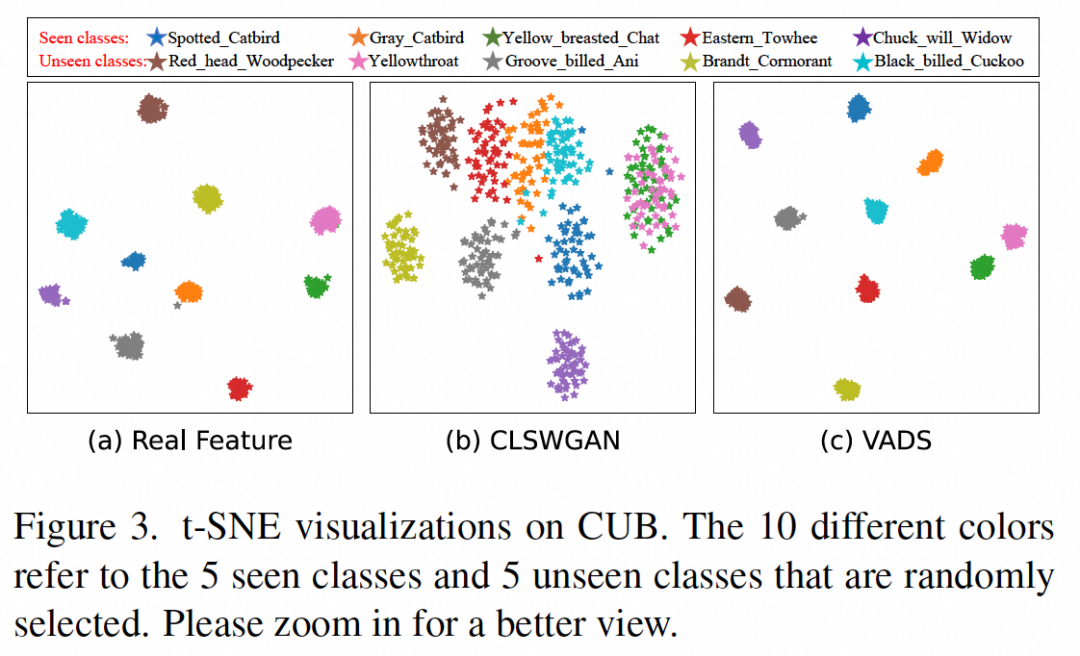
En visualisant les caractéristiques visuelles générées par le générateur, on peut voir que les caractéristiques de certaines catégories ont été à l'origine confondues, comme la classe vue "Chat à poitrine jaune" et la classe invisible affichée dans (b ) ci-dessous. Les deux types de caractéristiques « Yellowthroat » peuvent être clairement séparés en deux groupes dans la figure (c) après avoir utilisé la méthode VADS, évitant ainsi toute confusion lors de la formation du classificateur.
Peut être étendu aux domaines de la sécurité intelligente et des grands modèles
Machine Heart comprend que l'apprentissage zéro-shot axé sur l'équipe de recherche mentionnée ci-dessus vise à permettre au modèle de reconnaître de nouvelles catégories qui n'ont pas d'échantillons d'images au stade de la formation, ce qui a une valeur potentielle dans le domaine de la sécurité intelligente.
Tout d'abord, traitez les risques émergents dans les scénarios de sécurité. Étant donné que de nouveaux types de menaces ou des modèles de comportement inhabituels continueront d'apparaître dans les scénarios de sécurité, ils n'apparaissent peut-être pas dans les données de formation précédentes. L'apprentissage zéro-shot permet aux systèmes de sécurité d'identifier et de répondre rapidement aux nouveaux types de risques, améliorant ainsi la sécurité.
Deuxièmement, réduisez la dépendance à l'égard des échantillons de données : obtenir suffisamment de données annotées pour former un système de sécurité efficace est coûteux et prend du temps. L'apprentissage zéro réduit la dépendance du système à l'égard d'un grand nombre d'échantillons d'images, économisant ainsi les coûts de R&D. .
Troisièmement, améliorez la stabilité dans les environnements dynamiques : l'apprentissage sans tir utilise la description sémantique pour reconnaître des modèles de classe invisibles. Par rapport aux méthodes traditionnelles qui reposent entièrement sur les caractéristiques de l'image, il est naturellement plus résilient aux changements de stabilité de l'environnement.
En tant que technologie sous-jacente pour résoudre les problèmes de classification d'images, cette technologie peut également être mise en œuvre dans des scénarios qui s'appuient sur la technologie de classification visuelle, tels que la reconnaissance d'attributs de personnes, de biens, de véhicules et d'objets, la reconnaissance de comportement, etc. Surtout dans les scénarios où de nouvelles catégories à identifier doivent être rapidement ajoutées et où l'on n'a pas le temps de collecter des échantillons de formation, ou où il est difficile de collecter un grand nombre d'échantillons (comme l'identification des risques), la technologie d'apprentissage zéro-shot présente de grands avantages. par rapport aux méthodes traditionnelles.
Cette technologie de recherche a-t-elle une référence pour le développement des grands modèles actuels ?
Les chercheurs pensent que l'idée centrale de l'apprentissage génératif zéro-shot est d'aligner l'espace sémantique et l'espace des fonctionnalités visuelles, ce qui est cohérent avec les objectifs de recherche des modèles de langage visuel (tels que CLIP) dans les multi- grands modèles modaux.
La plus grande différence entre eux est que l'apprentissage génératif sans tir est formé et utilisé sur des catégories limitées prédéfinies d'ensembles de données, tandis que les grands modèles de langage visuel sont polyvalents grâce à l'apprentissage des capacités de représentation sémantique et visuelle. à des catégories limitées. En tant que modèle de base, ils ont une gamme d’applications plus large.
Si le scénario d'application de la technologie se situe dans un domaine spécifique, vous pouvez choisir d'adapter et d'affiner le grand modèle à ce domaine. Dans ce processus, travaillez dans la même direction de recherche ou dans une direction similaire à celle que cet article peut théoriquement. apporter une inspiration utile.
Présentation de l'auteur
Hou Wenjin, étudiant en master à l'Université des Sciences et Technologies de Huazhong, s'intéresse à la vision par ordinateur, à la modélisation générative, à l'apprentissage en quelques coups, etc. Il a réalisé cette thèse lors de son stage à Alibaba-Intime Business.
Wang Yan, directeur de la technologie commerciale d'Alibaba-Intime, chef des algorithmes de l'équipe intelligente de Shenzhen Xiang.
Feng Xuetao, expert senior en algorithmes chez Alibaba-Intime Business, se concentre principalement sur l'application d'algorithmes visuels et multimodaux dans le commerce de détail hors ligne et dans d'autres secteurs.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quels sont respectivement les logiciels Ai, Ae et Ps ?
- Comment faire apparaître la barre d'attributs AI
- Qu'est-ce que la technologie de l'IA ?
- L'annonce officielle du Haimo Supercomputing Center : un grand modèle avec 100 milliards de paramètres, une échelle de données de 1 million de clips et une réduction de 200 fois des coûts de formation
- Musk annonce qu'il poursuivra Microsoft pour avoir utilisé les données de Twitter pour entraîner un système d'intelligence artificielle