

 Périphériques technologiquesIANouvelle œuvre de Yan Shuicheng/Cheng Mingming ! La formation DiT, le composant principal de Sora, est accélérée 10 fois et Masked Diffusion Transformer V2 est open source
Périphériques technologiquesIANouvelle œuvre de Yan Shuicheng/Cheng Mingming ! La formation DiT, le composant principal de Sora, est accélérée 10 fois et Masked Diffusion Transformer V2 est open source
En tant que l'une des technologies de base convaincantes de Sora, DiT utilise le transformateur de diffusion pour faire évoluer le modèle génératif à une plus grande échelle afin d'obtenir des effets de génération d'images exceptionnels.
Cependant, les modèles de plus grande taille font monter en flèche les coûts de formation.
L'équipe de recherche de Yan Shuicheng et Cheng Mingming du Sea AI Lab, de l'Université de Nankai et de l'Institut de recherche Kunlun Wanwei 2050 a proposé un nouveau modèle appelé Masked Diffusion Transformer lors de la conférence ICCV 2023. Ce modèle utilise la technologie de modélisation de masques pour accélérer la formation de Diffusion Transformer en apprenant les informations de représentation sémantique et réalise des effets SoTA dans le domaine de la génération d'images. Cette innovation apporte de nouvelles avancées dans le développement de modèles de génération d’images et offre aux chercheurs une méthode de formation plus efficace. En combinant expertise et technologie de différents domaines, l’équipe de recherche a proposé avec succès une solution qui augmente la vitesse de formation et améliore les résultats de génération. Leurs travaux ont apporté d'importantes idées innovantes au développement du domaine de l'intelligence artificielle et ont fourni une source d'inspiration utile pour la recherche et la pratique futures. , Masked Diffusion Transformer V2 a encore une fois actualisé SoTA, augmentant la vitesse d'entraînement de plus de 10 fois par rapport à DiT et atteignant le score FID de 1,58.
La dernière version du document et du code est open source. 
Par exemple, comme le montre l'image ci-dessus, DiT a appris à générer la texture des poils d'un chien à la 50ème étape d'entraînement, puis a appris à générer l'un des yeux du chien à la 200ème étape. marche d'entraînement et bouche, mais il manquait un autre œil.
Même au pas d'entraînement de 300k, la position relative des deux oreilles du chien générée par DiT n'est pas très précise.
Ce processus de formation et d'apprentissage révèle que le modèle de diffusion ne parvient pas à apprendre efficacement la relation sémantique entre les différentes parties de l'objet dans l'image, mais n'apprend que les informations sémantiques de chaque objet de manière indépendante. 
Comme le montre la figure ci-dessus, MDT introduit une stratégie d'apprentissage de la modélisation de masques tout en maintenant le processus de formation par diffusion. En masquant le jeton d'image bruyante, MDT utilise une architecture de transformateur de diffusion asymétrique (Asymétrique Diffusion Transformer) pour prédire le jeton d'image masqué à partir du jeton d'image bruyante qui n'a pas été masqué, réalisant ainsi simultanément les processus de modélisation de masque et de formation à la diffusion.
Pendant le processus d'inférence, MDT maintient toujours le processus de génération de diffusion standard. La conception de MDT permet à Diffusion Transformer de bénéficier à la fois de la capacité d'expression d'informations sémantiques apportée par l'apprentissage de la représentation par modélisation de masque et de la capacité du modèle de diffusion à générer des détails d'image.
Plus précisément, MDT mappe les images sur l'espace latent via l'encodeur VAE et les traite dans l'espace latent pour réduire les coûts de calcul.
Pendant le processus de formation, MDT masque d'abord une partie des jetons d'image après avoir ajouté du bruit, et envoie les jetons restants au transformateur de diffusion asymétrique pour prédire tous les jetons d'image après le débruitage.
Architecture du transformateur de diffusion asymétrique
 Image
Image
Comme le montre la figure ci-dessus, l'architecture du transformateur de diffusion asymétrique comprend un encodeur, un interpolateur latéral (interpolateur auxiliaire) et un décodeur.
 Images
Images
Pendant le processus de formation, l'encodeur traite uniquement les jetons qui ne sont pas masqués pendant le processus d'inférence, puisqu'il n'y a pas d'étape de masque, il traite tous les jetons ;
Par conséquent, afin de garantir que le décodeur puisse toujours traiter tous les jetons pendant la phase de formation ou d'inférence, les chercheurs ont proposé une solution : pendant le processus de formation, via un interpolateur auxiliaire composé de blocs DiT (comme le montre la figure ci-dessus), interpoler et prédire le jeton masqué à partir de la sortie de l'encodeur, et le supprimer pendant l'étape d'inférence sans ajouter de surcharge d'inférence.
L'encodeur et le décodeur de MDT insèrent des informations de codage de position globale et locale dans le bloc DiT standard pour aider à prédire le jeton dans la partie masque.
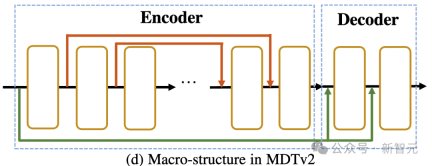
Transformateur de diffusion asymétrique V2
 Photos
Photos
Comme le montre l'image ci-dessus, MDTv2 optimise davantage la diffusion et le masque en introduisant une structure de macro-réseau plus efficace conçue pour le processus de diffusion masquée. processus de modélisation.
Cela inclut l'intégration d'un raccourci long de style U-Net dans l'encodeur et d'un raccourci d'entrée dense dans le décodeur.
Parmi eux, un raccourci d'entrée dense envoie le jeton masqué après avoir ajouté du bruit au décodeur, conservant les informations de bruit correspondant au jeton masqué, facilitant ainsi l'apprentissage du processus de diffusion.
De plus, MDT a également introduit de meilleures stratégies d'entraînement, notamment l'utilisation d'un optimiseur Adan plus rapide, des poids de perte liés au pas de temps et des ratios de masques élargis pour accélérer davantage le processus d'entraînement du modèle de diffusion masquée.
Résultats expérimentaux
Comparaison de la qualité de la génération de référence ImageNet 256
 images
images
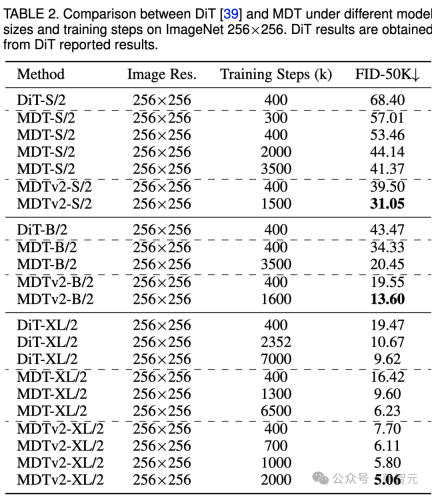
Le tableau ci-dessus compare les performances de MDT et DiT sous le benchmark ImageNet 256 sous différentes tailles de modèles.
Il est évident que MDT obtient des scores FID plus élevés avec moins de coûts de formation, quelle que soit la taille du modèle.
Les paramètres et les coûts d'inférence de MDT sont fondamentalement les mêmes que ceux de DiT, car comme mentionné ci-dessus, le processus de diffusion standard compatible avec DiT est toujours maintenu dans le processus d'inférence MDT.
Pour le plus grand modèle XL, MDTv2-XL/2, entraîné avec 400 000 pas, surpasse significativement DiT-XL/2, entraîné avec 7 000 000 pas, avec une amélioration du score FID de 1,92. Dans ce paramètre, les résultats montrent que MDT a un entraînement environ 18 fois plus rapide que DiT.
Pour les petits modèles, MDTv2-S/2 atteint toujours des performances nettement meilleures que DiT-S/2 avec beaucoup moins d'étapes de formation. Par exemple, avec la même formation de 400 000 étapes, MDTv2 a un indice FID de 39,50, ce qui est nettement supérieur à l'indice FID de DiT de 68,40.
Plus important encore, ce résultat dépasse également les performances du plus grand modèle DiT-B/2 à 400 000 pas d'entraînement (39,50 contre 43,47).
Comparaison de la qualité de génération CFG de référence ImageNet 256
 images
images
Nous avons également comparé les performances de génération d'images de MDT avec les méthodes existantes sous guidage sans classificateur dans le tableau ci-dessus.
MDT surpasse les précédentes méthodes SOTA DiT et autres avec un score FID de 1,79. MDTv2 améliore encore les performances, poussant le score SOTA FID pour la génération d'images à un nouveau plus bas de 1,58 avec moins d'étapes de formation.
Semblable à DiT, nous n'avons pas observé de saturation du score FID du modèle pendant l'entraînement alors que nous poursuivions l'entraînement.
 MDT actualise SoTA sur le classement de PaperWithCode
MDT actualise SoTA sur le classement de PaperWithCode
Comparaison de la vitesse de convergence
 image
image
L'image ci-dessus compare 8 × A100 sous le benchmark ImageNet 256 DiT-S/ sur GPU 2 FID performances de la ligne de base, MDT-S/2 et MDTv2-S/2 sous différentes étapes/temps de formation.
Grâce à de meilleures capacités d'apprentissage contextuel, MDT surpasse DiT en termes de performances et de vitesse de génération. La vitesse de convergence de formation de MDTv2 est plus de 10 fois supérieure à celle de DiT.
MDT est environ 3 fois plus rapide que DiT en termes d'étapes et de temps d'entraînement. MDTv2 améliore encore la vitesse d'entraînement d'environ 5 fois par rapport à MDT.
Par exemple, MDTv2-S/2 affiche de meilleures performances en seulement 13 heures (15 000 pas) que DiT-S/2 qui prend environ 100 heures (1 500 000 pas) pour s'entraîner, ce qui révèle que l'apprentissage de la représentation contextuelle est important pour Un apprentissage génératif plus rapide des modèles de diffusion est crucial.
Résumé et discussion
MDT introduit un schéma d'apprentissage de représentation de modélisation de masque similaire au MAE dans le processus de formation par diffusion, qui peut utiliser les informations contextuelles des objets image pour reconstruire les informations complètes de l'image d'entrée incomplète, apprenant ainsi la sémantique dans l'image La corrélation entre les pièces, améliorant ainsi la qualité de la génération d'images et la vitesse d'apprentissage.
Les chercheurs pensent qu'améliorer la compréhension sémantique du monde physique grâce à l'apprentissage de la représentation visuelle peut améliorer l'effet de simulation du modèle génératif sur le monde physique. Cela coïncide avec la vision de Sora de construire un simulateur du monde physique grâce à des modèles génératifs. Espérons que ce travail inspirera davantage de travaux sur l’unification de l’apprentissage des représentations et de l’apprentissage génératif.
Référence :
https://arxiv.org/abs/2303.14389
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Le développement du jeu AI entre dans son ère agentique avec le portail de rêveur de bouleversementMay 02, 2025 am 11:17 AM
Le développement du jeu AI entre dans son ère agentique avec le portail de rêveur de bouleversementMay 02, 2025 am 11:17 AMJeux de bouleversement: révolutionner le développement de jeux avec les agents de l'IA Les bouleversements, un studio de développement de jeux composé d'anciens combattants de géants de l'industrie comme Blizzard et Obsidian, est sur le point de révolutionner la création de jeux avec son plat innovant alimenté par AI
 Uber veut être votre boutique de robotaxi, les fournisseurs les laisseront-ils?May 02, 2025 am 11:16 AM
Uber veut être votre boutique de robotaxi, les fournisseurs les laisseront-ils?May 02, 2025 am 11:16 AMStratégie de robotaxi d'Uber: un écosystème de co-hail pour les véhicules autonomes Lors de la récente conférence Curbivore, Richard Willder d'Uber a dévoilé sa stratégie pour devenir la plate-forme de co-hail pour les fournisseurs de robotaxi. Tirant parti de leur position dominante dans
 Les agents de l'IA jouant aux jeux vidéo transformeront les futurs robotsMay 02, 2025 am 11:15 AM
Les agents de l'IA jouant aux jeux vidéo transformeront les futurs robotsMay 02, 2025 am 11:15 AMLes jeux vidéo s'avèrent être des terrains de test inestimables pour la recherche de pointe de l'IA, en particulier dans le développement d'agents autonomes et de robots du monde réel, contribuant même potentiellement à la quête de l'intelligence générale artificielle (AGI). UN
 Le complexe industriel de startup, le VC 3.0 et le manifeste de James CurrierMay 02, 2025 am 11:14 AM
Le complexe industriel de startup, le VC 3.0 et le manifeste de James CurrierMay 02, 2025 am 11:14 AML'impact de l'évolution du paysage du capital-risque est évident dans les médias, les rapports financiers et les conversations quotidiennes. Cependant, les conséquences spécifiques pour les investisseurs, les startups et les fonds sont souvent négligées. Venture Capital 3.0: un paradigme
 Adobe met à jour Creative Cloud and Firefly chez Adobe Max London 2025May 02, 2025 am 11:13 AM
Adobe met à jour Creative Cloud and Firefly chez Adobe Max London 2025May 02, 2025 am 11:13 AMAdobe Max London 2025 a fourni des mises à jour importantes au Creative Cloud and Firefly, reflétant un changement stratégique vers l'accessibilité et l'IA générative. Cette analyse intègre des idées à partir d'informations pré-événement avec Adobe Leadership. (Remarque: Adob
 Tout ce que Meta a annoncé à LlamaconMay 02, 2025 am 11:12 AM
Tout ce que Meta a annoncé à LlamaconMay 02, 2025 am 11:12 AMLes annonces de Llamacon de Meta présentent une stratégie complète d'IA conçue pour rivaliser directement avec des systèmes d'IA fermés comme celles d'OpenAI, tout en créant simultanément de nouveaux flux de revenus pour ses modèles open-source. Cette approche multiforme cible BO
 La controverse du brassage sur la proposition que l'IA n'est rien de plus que la technologie normaleMay 02, 2025 am 11:10 AM
La controverse du brassage sur la proposition que l'IA n'est rien de plus que la technologie normaleMay 02, 2025 am 11:10 AMIl existe de graves différences dans le domaine de l'intelligence artificielle sur cette conclusion. Certains insistent sur le fait qu'il est temps d'exposer les "nouveaux vêtements de l'empereur", tandis que d'autres s'opposent fortement à l'idée que l'intelligence artificielle n'est que une technologie ordinaire. Discutons-en. Une analyse de cette percée d'IA innovante fait partie de ma colonne Forbes en cours qui couvre les dernières avancées dans le domaine de l'IA, y compris l'identification et l'explication d'une variété de complexités d'influence influentes (cliquez ici pour voir le lien). L'intelligence artificielle en tant que technologie commune Premièrement, certaines connaissances de base sont nécessaires pour jeter les bases de cette discussion importante. Il existe actuellement une grande quantité de recherches dédiées au développement de l'intelligence artificielle. L'objectif global est d'atteindre l'intelligence générale artificielle (AGI) et même la super intelligence artificielle (AS) possible (AS)
 Modèles de citoyens, pourquoi la valeur de l'IA est le prochain critère commercialMay 02, 2025 am 11:09 AM
Modèles de citoyens, pourquoi la valeur de l'IA est le prochain critère commercialMay 02, 2025 am 11:09 AML'efficacité du modèle d'IA d'une entreprise est désormais un indicateur de performance clé. Depuis le boom de l'IA, l'IA générative a été utilisée pour tout, de la composition des invitations d'anniversaire à l'écriture du code logiciel. Cela a conduit à une prolifération du mod de langue


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Listes Sec
SecLists est le compagnon ultime du testeur de sécurité. Il s'agit d'une collection de différents types de listes fréquemment utilisées lors des évaluations de sécurité, le tout en un seul endroit. SecLists contribue à rendre les tests de sécurité plus efficaces et productifs en fournissant facilement toutes les listes dont un testeur de sécurité pourrait avoir besoin. Les types de listes incluent les noms d'utilisateur, les mots de passe, les URL, les charges utiles floues, les modèles de données sensibles, les shells Web, etc. Le testeur peut simplement extraire ce référentiel sur une nouvelle machine de test et il aura accès à tous les types de listes dont il a besoin.

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

DVWA
Damn Vulnerable Web App (DVWA) est une application Web PHP/MySQL très vulnérable. Ses principaux objectifs sont d'aider les professionnels de la sécurité à tester leurs compétences et leurs outils dans un environnement juridique, d'aider les développeurs Web à mieux comprendre le processus de sécurisation des applications Web et d'aider les enseignants/étudiants à enseigner/apprendre dans un environnement de classe. Application Web sécurité. L'objectif de DVWA est de mettre en pratique certaines des vulnérabilités Web les plus courantes via une interface simple et directe, avec différents degrés de difficulté. Veuillez noter que ce logiciel

Dreamweaver CS6
Outils de développement Web visuel

MinGW - GNU minimaliste pour Windows
Ce projet est en cours de migration vers osdn.net/projects/mingw, vous pouvez continuer à nous suivre là-bas. MinGW : un port Windows natif de GNU Compiler Collection (GCC), des bibliothèques d'importation et des fichiers d'en-tête librement distribuables pour la création d'applications Windows natives ; inclut des extensions du runtime MSVC pour prendre en charge la fonctionnalité C99. Tous les logiciels MinGW peuvent fonctionner sur les plates-formes Windows 64 bits.

