
Maison >Périphériques technologiques >IA >L'astuce d'amplification de Pika : à partir d'aujourd'hui, les effets vidéo et sonores peuvent être produits « dans un seul pot » !
L'astuce d'amplification de Pika : à partir d'aujourd'hui, les effets vidéo et sonores peuvent être produits « dans un seul pot » !

- WBOYavant
- 2024-03-11 13:00:15802parcourir
Tout à l'heure, Pika a publié une nouvelle fonctionnalité :
Désolé, nous avons déjà été mis en sourdine.
À partir d'aujourd'hui, tout le monde peut générer de manière transparente des effets sonores pour les vidéos——Effets sonores !
Il existe deux façons de le générer :
- Soit vous donnez une invite pour décrire le son souhaité, soit vous laissez simplement Pika le générer automatiquement en fonction du contenu vidéo ;
- Et Pika a dit avec beaucoup d'assurance : "Si vous pensez que l'effet sonore sonne bien, c'est parce que c'est le cas".
Le bruit des voitures, des radios, des aigles, des épées, des acclamations... on peut dire que le son est infini, et en termes d'effet, il correspond également parfaitement à l'image vidéo.
Non seulement la vidéo promotionnelle a été publiée, mais le site officiel de Pika a également publié plusieurs démos.
Par exemple,
sans aucune invite, AI vient de regarder la vidéo du bacon rôti et peut faire correspondre les effets sonores sans aucun sentiment de violation. Autre invite :
Couleur super saturée, feu d'artifice sur un champ au coucher du soleil.
Couleur super saturée, feu d'artifice sur un champ au coucher du soleil.
Pika peut ajouter du son lors de la génération de vidéo. Il n'est pas difficile de voir à partir de l'effet que le son bloqué au moment où le feu d'artifice fleurit est également assez précis.
Une telle nouvelle fonctionnalité a été publiée pendant le grand week-end. Tandis que les internautes criaient à Pika
"C'est tellement volumineux et génial", certaines personnes pensaient également :
Il rassemble toutes les "gemmes infinies" pour la création d'IA multimodale. . Continuons donc à examiner comment utiliser les effets sonores de Pika.
Continuons donc à examiner comment utiliser les effets sonores de Pika.
"faire du bruit" pour les vidéos
L'opération de Pika consistant à générer des effets sonores pour les vidéos est également
super géniale ! Que! simple! un!Par exemple, une seule invite, des effets vidéo et sonores peuvent
"sortir d'un même pot" :
Trompettiste médiéval.Trompettiste médiéval.
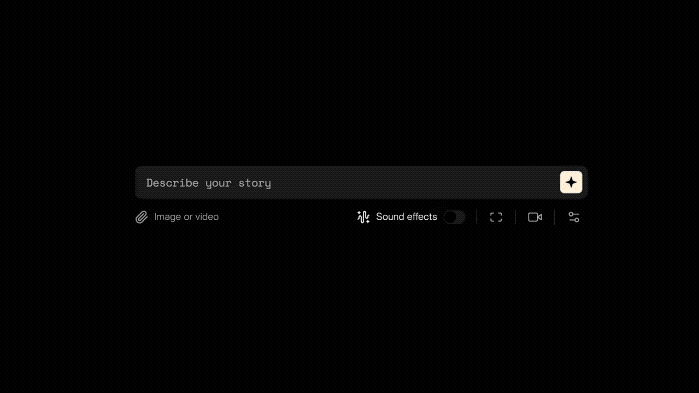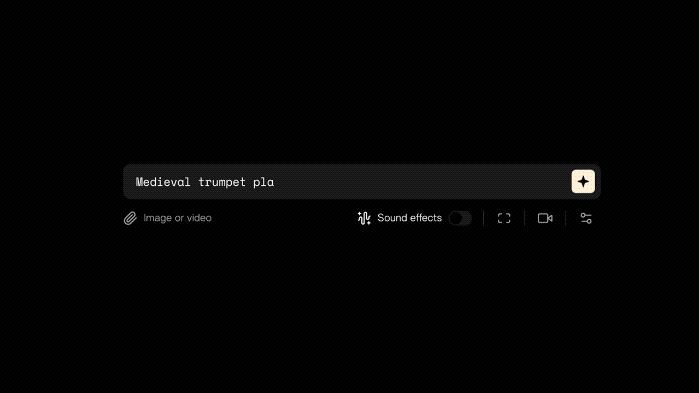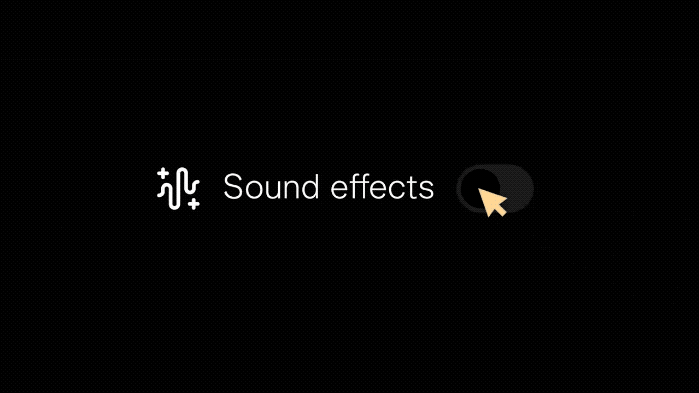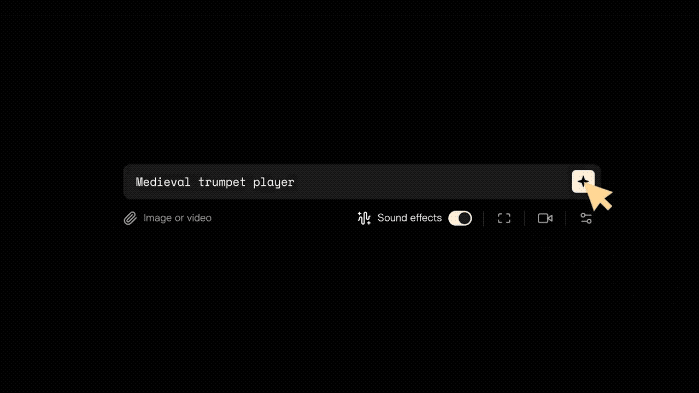 Par rapport à l'opération précédente de génération de vidéos, il vous suffit désormais d'activer le bouton "Effets sonores" ci-dessous.
Par rapport à l'opération précédente de génération de vidéos, il vous suffit désormais d'activer le bouton "Effets sonores" ci-dessous.
La deuxième méthode de fonctionnement consiste à le doubler séparément après avoir généré la vidéo.
Par exemple, dans la vidéo ci-dessous, cliquez sur
"Modifier" ci-dessous, puis sélectionnez "Effets sonores" :
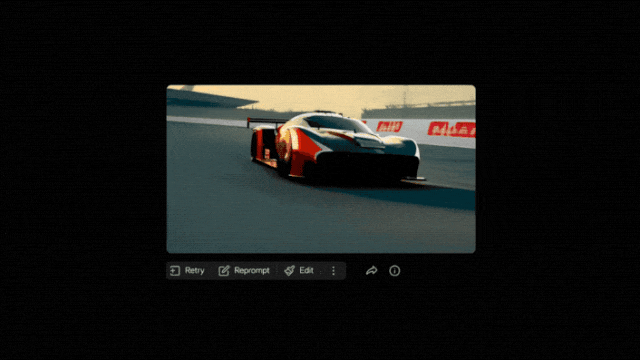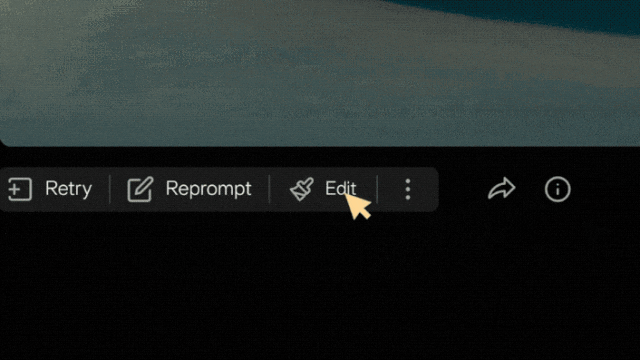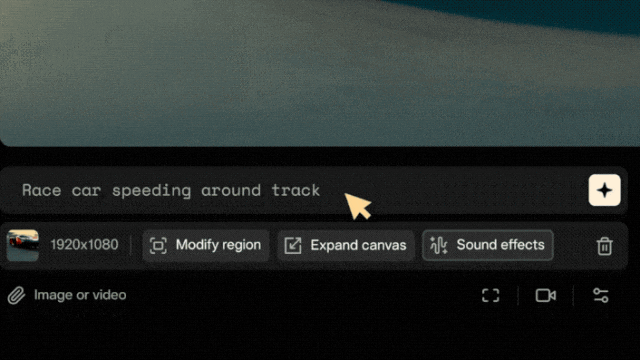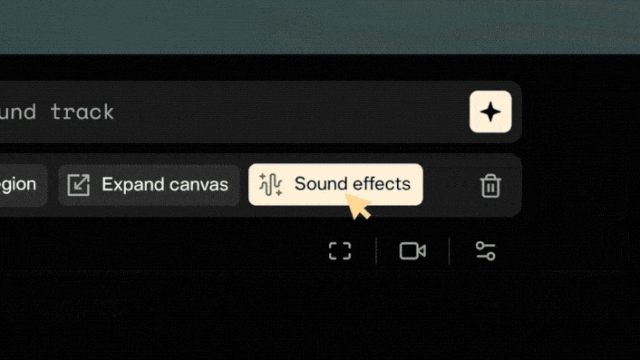 Ensuite, vous pouvez décrire le son que vous souhaitez, par exemple :
Ensuite, vous pouvez décrire le son que vous souhaitez, par exemple :
La voiture de course fait tourner son moteur.Ensuite, en quelques secondes seulement, Pika peut générer des effets sonores basés sur la description et la vidéo, et il y a
6 sons parmi lesquels choisir ! Il convient de mentionner que la fonction Effets sonores n'est actuellement ouverte aux tests qu'aux utilisateurs Super Collaborator
(Super Collaborator)et Pro. Cependant, Pika a également déclaré : "Nous lancerons bientôt cette fonctionnalité à tous les utilisateurs !"
Et maintenant, un groupe d'internautes a commencé à tester cette version bêta et a déclaré :
Les effets sonores sonnent très bien pour la vidéo et ajoutent beaucoup d'ambiance.
Quel est le principe ?
Quant au principe des effets sonores, bien que Pika ne l'ait pas rendu public cette fois, après que Sora soit devenu populaire, la start-up vocale ElevenLabs a produit une fonction de doublage similaire.
À cette époque, le scientifique principal de NVIDIA Jim Fan a effectué une analyse plus approfondie à ce sujet.
Il estime que l'apprentissage par l'IA d'un mapping vidéo-audio précis nécessite également de modéliser une physique "implicite" dans l'espace latent.

Il a détaillé les problèmes que le transformateur de bout en bout doit résoudre lors de la simulation d'ondes sonores :
- Identifier la catégorie, le matériau et l'emplacement spatial de chaque objet.
- Reconnaître les interactions d'ordre supérieur entre les objets : par exemple, s'agit-il d'un bâton, d'un métal ou d'une peau de tambour ? A quelle vitesse est-il frappé ?
- Identifier l'environnement : s'agit-il d'un restaurant, d'une station spatiale ou du parc de Yellowstone ?
- Récupérez les modèles sonores typiques des objets et des environnements à partir de la mémoire interne du modèle.
- Utilisez des règles physiques « douces » apprises pour combiner et ajuster les paramètres des modèles sonores, et même créer des sons entièrement nouveaux à la volée. C'est un peu comme "l'audio procédural" dans les moteurs de jeux.
- Si la scène est complexe, le modèle doit superposer plusieurs pistes sonores en fonction de la position spatiale de l'objet.
Tout cela n'est pas un module explicite, mais est réalisé par apprentissage par descente de gradient sur un grand nombre de paires (vidéo, audio) qui sont naturellement alignées temporellement dans la plupart des vidéos Internet. Les couches d'attention implémenteront ces algorithmes dans leurs pondérations pour atteindre l'objectif de diffusion.
De plus, Jim Fan a déclaré à l'époque que les travaux connexes de Nvidia ne disposaient pas d'un moteur audio AI d'une telle qualité, mais il a recommandé un article du MIT il y a cinq ans The Sound of Pixels :

Intéressé les amis peuvent cliquer sur le lien à la fin de l’article pour en savoir plus.
One More Thing
Sur la question du multi-modal, LeCun a également une opinion très chaude dans la dernière interview. Il estime :
La langue (texte) a une faible bande passante : moins de. 12 octets/seconde. Les LLM modernes utilisent généralement 1x10^13 jetons à double octet (c'est-à-dire 2x10^13 octets) pour la formation. Il faudrait environ 100 000 ans à un être humain pour lire (12 heures par jour).
La bande passante visuelle est beaucoup plus élevée : environ 20 Mo/s. Chacun des deux nerfs optiques possède 1 million de fibres nerveuses, chacune transportant environ 10 octets par seconde. Un enfant de 4 ans passe environ 16 000 heures à l'état éveillé, ce qui représente environ 1x10^15 une fois converti en octets.
La bande passante des données de perception visuelle est environ 16 millions de fois supérieure à celle des données du langage textuel.
Les données vues par un enfant de 4 ans représentent 50 fois les données LLM les plus volumineuses de toutes les formations textuelles publiées sur Internet.

Ainsi, LeCun a conclu :
Il n'y a absolument aucun moyen d'atteindre une intelligence artificielle au niveau humain sans laisser les machines apprendre à partir d'entrées sensorielles à large bande passante (telles que la vision).
Alors, êtes-vous d’accord avec ce point de vue ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les deux domaines de recherche de l'intelligence artificielle sont
- Quelle est la relation entre l'intelligence artificielle, l'apprentissage automatique et l'apprentissage profond ?
- Quelle est la différence entre l'apprentissage profond et l'apprentissage automatique
- Comment utiliser l'apprentissage automatique et l'intelligence artificielle en cybersécurité
- Comment implémenter des fonctions d'intelligence artificielle et d'apprentissage automatique via le développement C++ ?