
Maison >Périphériques technologiques >IA >ICLR 2024 | Offrant une nouvelle perspective pour la séparation audio et vidéo, l'équipe Hu Xiaolin de l'Université Tsinghua a lancé RTFS-Net
ICLR 2024 | Offrant une nouvelle perspective pour la séparation audio et vidéo, l'équipe Hu Xiaolin de l'Université Tsinghua a lancé RTFS-Net

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-06 18:28:13637parcourir
L'objectif principal de la technologie de séparation audiovisuelle de la parole (AVSS) est d'identifier et de séparer la voix du locuteur cible dans le signal mixte, en utilisant les informations faciales pour atteindre cet objectif. Cette technologie a de nombreuses applications dans de nombreux domaines, notamment les assistants intelligents, les conférences à distance et la réalité augmentée. Grâce à la technologie AVSS, la qualité des signaux vocaux dans les environnements bruyants peut être considérablement améliorée, améliorant ainsi les effets de la reconnaissance vocale et de la communication. Le développement de cette technologie a apporté plus de commodité à la vie quotidienne et au travail des gens, facilitant ainsi la tâche.
Les méthodes traditionnelles de séparation de la parole audiovisuelle nécessitent généralement des modèles complexes et une grande quantité de ressources informatiques, en particulier lorsqu'il y a des arrière-plans bruyants ou de nombreux les gens parlent. Dans ce cas, ses performances sont facilement limitées. Pour surmonter ces problèmes, les chercheurs ont commencé à explorer des méthodes basées sur l’apprentissage profond. Cependant, la technologie d’apprentissage profond existante présente des défis liés à une grande complexité informatique et à des difficultés d’adaptation à des environnements inconnus.
Plus précisément, les méthodes actuelles de séparation de la parole audiovisuelle présentent les problèmes suivants :
Méthode du domaine temporel : elle peut fournir des effets de séparation audio de haute qualité, mais en raison de davantage de paramètres, d'une complexité de calcul plus élevée et d'une vitesse de traitement plus lente.
Méthodes du domaine temps-fréquence : plus efficaces sur le plan informatique, mais historiquement moins performantes que les méthodes du domaine temporel. Ils sont confrontés à trois défis principaux :
1. Manque de modélisation indépendante des dimensions temporelles et fréquentielles.
2. Les signaux visuels provenant de plusieurs champs récepteurs ne sont pas pleinement utilisés pour améliorer les performances du modèle.
3. Un traitement inapproprié de caractéristiques complexes entraîne la perte d'informations clés sur l'amplitude et la phase.
Afin de relever ces défis, des chercheurs de l'équipe du professeur agrégé Hu Xiaolin de l'Université Tsinghua ont proposé un nouveau modèle de séparation de la parole audiovisuelle appelé RTFS-Net. Le modèle adopte une méthode de compression-reconstruction, qui réduit considérablement la complexité de calcul et le nombre de paramètres du modèle tout en améliorant les performances de séparation. RTFS-Net est la première méthode de séparation de la parole audiovisuelle utilisant moins d'un million de paramètres, et c'est également la première méthode à surpasser tous les modèles du domaine temporel en matière de séparation multimodale dans le domaine temps-fréquence.

Adresse papier : https://arxiv.org/abs/2309.17189
Page d'accueil papier : https://cslikai.cn/RTFS-Net/AV-Model-Demo.html
-
Adresse du code : https://github.com/spkgyk/RTFS-Net (à venir)
Introduction à la méthode
L'architecture réseau globale de RTFS-Net est présentée dans la figure 1 ci-dessous :
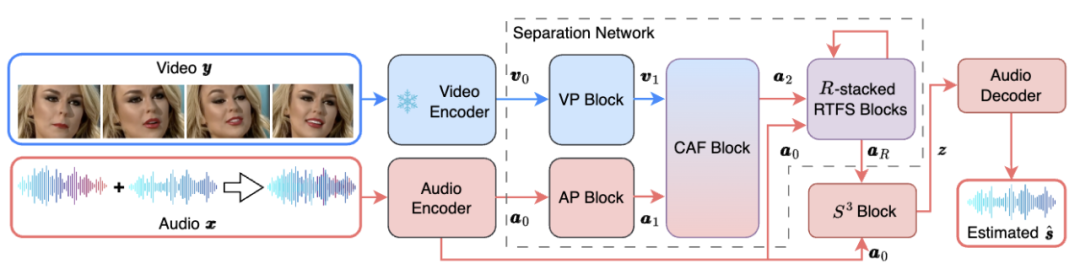
Figure 1. Structure du réseau RTFS-Net
Parmi eux, le bloc RTFS (illustré sur la figure 2) compresse et modélise indépendamment les dimensions acoustiques (temps et fréquence), tout en créant un sous-espace de faible complexité autant que possible Réduire la perte d’informations. Plus précisément, le bloc RTFS utilise une architecture à double chemin pour un traitement efficace des signaux audio dans les dimensions temporelle et fréquentielle. Grâce à cette approche, les blocs RTFS sont capables de réduire la complexité des calculs tout en conservant une sensibilité et une précision élevées aux signaux audio. Voici le flux de travail spécifique du bloc RTFS :
1. Compression temps-fréquence : le bloc RTFS compresse d'abord les caractéristiques audio d'entrée dans les dimensions temporelles et fréquentielles.
2. Modélisation dimensionnelle indépendante : une fois la compression terminée, le bloc RTFS modélise indépendamment les dimensions temporelles et fréquentielles.
3. Fusion dimensionnelle : Après avoir traité indépendamment les dimensions temporelles et fréquentielles, le bloc RTFS fusionne les informations des deux dimensions via un module de fusion.
4. Reconstruction et sortie : Enfin, les caractéristiques fusionnées sont reconstruites dans l'espace temps-fréquence d'origine à travers une série de couches de déconvolution.
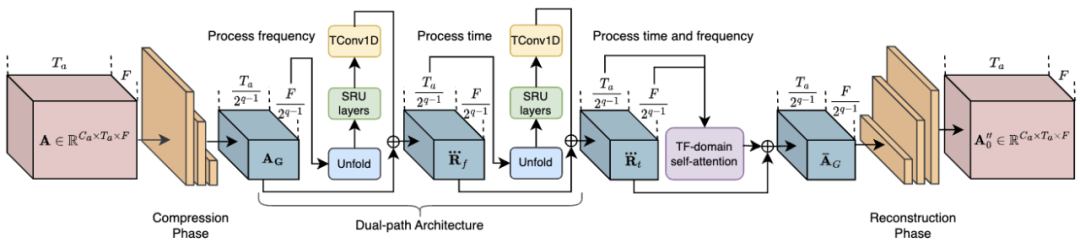
Figure 2. Structure du réseau du bloc RTFS
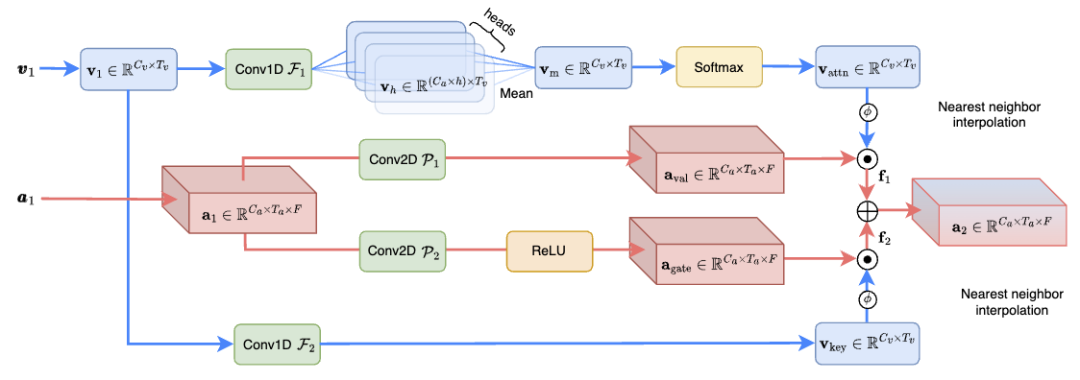
Le module de fusion d'attention interdimensionnelle (CAF) (illustré dans la figure 3) fusionne efficacement les informations audio et visuelles, améliore l'effet de séparation de la parole et réduit la complexité informatique Cela ne représente que 1,3% de la méthode SOTA précédente. Plus précisément, le module CAF génère d’abord des poids d’attention à l’aide d’opérations de profondeur et de convolution groupée. Ces pondérations s'ajustent dynamiquement en fonction de l'importance des caractéristiques d'entrée, permettant au modèle de se concentrer sur les informations les plus pertinentes. Ensuite, en appliquant les pondérations d'attention générées aux caractéristiques visuelles et auditives, le module CAF est capable de se concentrer sur les informations clés dans plusieurs dimensions. Cette étape implique de pondérer et de fusionner des fonctionnalités de différentes dimensions pour produire une représentation complète des fonctionnalités. En plus du mécanisme d'attention, le module CAF peut également adopter un mécanisme de contrôle pour contrôler davantage le degré de fusion des fonctionnalités provenant de différentes sources. Cette approche peut améliorer la flexibilité du modèle et permettre un contrôle plus fin du flux d'informations.
nombres complexes pour extraire efficacement le discours du haut-parleur cible à partir de la fonction audio mixte. Cette méthode utilise pleinement les informations de phase et d'amplitude du signal audio et améliore la précision et l'efficacité de la séparation des sources. Et l'utilisation d'un réseau complexe permet au bloc S^3 de traiter le signal avec plus de précision lors de l'isolation de la parole du locuteur cible, notamment en préservant les détails et en réduisant les artefacts, comme indiqué ci-dessous. De même, la conception du bloc S^3 permet une intégration facile dans différents cadres de traitement audio, convient à une variété de tâches de séparation de sources et possède de bonnes capacités de généralisation.
Résultats expérimentaux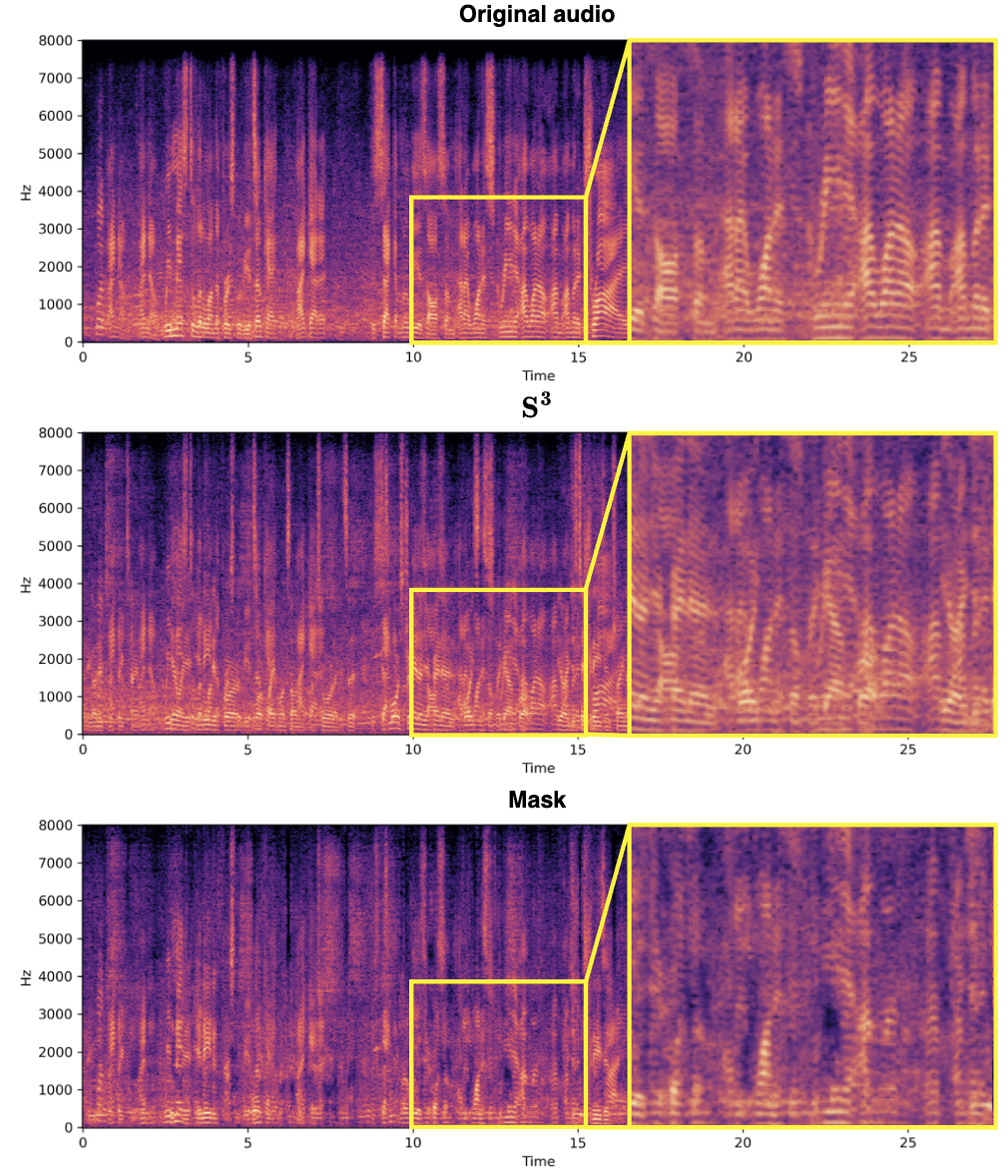
Effet de séparation
Sur trois ensembles de données de référence sur la séparation de la parole multimodale (LRS2, LRS3 et VoxCeleb2), comme indiqué ci-dessous, RTFS-Net réduit considérablement les paramètres du modèle et les calculs. complexité, approchant ou dépassant les performances de pointe actuelles. Le compromis entre efficacité et performances est démontré par des variantes avec différents nombres de blocs RTFS (4, 6, 12 blocs), où RTFS-Net-6 offre un bon équilibre entre performances et efficacité. RTFS-Net-12 a obtenu les meilleurs résultats sur tous les ensembles de données testés, prouvant les avantages des méthodes du domaine temps-fréquence dans la gestion de tâches complexes de séparation de synchronisation audio et vidéo.
Effets réels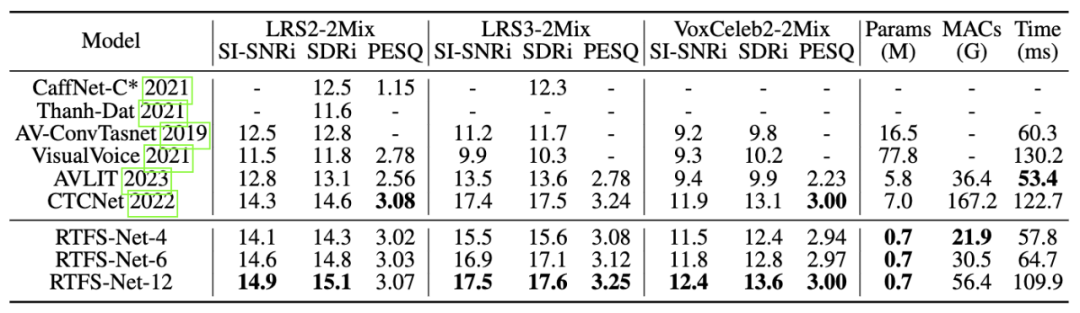
Vidéo mixte :
Audio du haut-parleur féminin : Audio du haut-parleur masculin :
Audio du haut-parleur masculin : 
 Résumé
Résumé
Avec l'avancement continu du développement technologique de grands modèles, de l'audiovisuel Le domaine de la séparation de la parole poursuit également des modèles à grande échelle pour améliorer la qualité de la séparation. Toutefois, cela n’est pas réalisable pour les appareils finaux. RTFS-Net permet d'améliorer considérablement les performances tout en maintenant une complexité de calcul et un nombre de paramètres considérablement réduits. Cela démontre que l’amélioration des performances AVSS ne nécessite pas nécessairement des modèles plus grands, mais plutôt des architectures innovantes et efficaces qui capturent mieux l’interaction complexe entre les modalités audio et visuelles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Spécialement conçu pour les arbres de décision, l'Université nationale de Singapour et l'Université Tsinghua proposent conjointement un nouveau système d'apprentissage fédéré rapide et sécurisé.
- Zhou Bowen de l'Université Tsinghua : La popularité de ChatGPT révèle la grande importance de la nouvelle génération de collaboration et d'intelligence interactive
- Application de la technologie informatique de confiance dans le domaine de la sécurité industrielle
- La conférence AICC sur le calcul de l'intelligence artificielle 2023 s'est tenue à Pékin et s'est concentrée sur les discussions brûlantes de l'industrie sur les modèles à grande échelle et la puissance de calcul intelligente.
- L'Université Tsinghua a remporté le cinquième concours d'applications d'IA de répartition de puissance avec des scores parfaits et le concours s'est terminé avec succès !