
Maison >Périphériques technologiques >IA >Le rapport technique de Stable Diffusion 3 a fuité, l'architecture Sora a encore fait de grandes réalisations ! La communauté open source bat-elle violemment Midjourney et DALL·E 3 ?
Le rapport technique de Stable Diffusion 3 a fuité, l'architecture Sora a encore fait de grandes réalisations ! La communauté open source bat-elle violemment Midjourney et DALL·E 3 ?

- PHPzavant
- 2024-03-06 16:22:20694parcourir
Stability AI a publié aujourd'hui un rapport technique détaillé après la sortie de Stable Diffusion 3.
L'article fournit une analyse approfondie de la technologie de base de Stable Diffusion 3 - une version améliorée du modèle de diffusion et une nouvelle architecture de graphes vincentiens basée sur DiT !

Adresse de déclaration :
https://www.php.cn/link/e5fb88b398b042f6cccce46bf3fa53e8
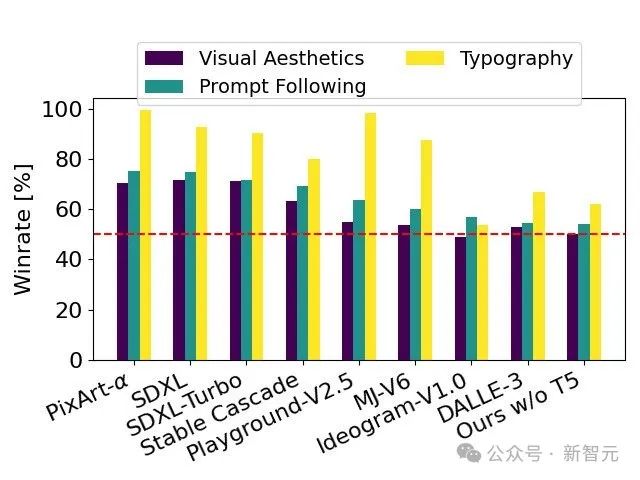
Test d'évaluation humaine réussi, Stable D iffusion 3. Dans la conception des polices et la réponse précise aux invites En termes de performances, il surpasse DALL·E 3, Midjourney v6 et Ideogram v1.
La nouvelle architecture de transformateur de diffusion multimodale (MMDiT) développée par Stability AI utilise des ensembles de poids indépendants spécifiquement pour la représentation d'images et de langage. Par rapport aux versions antérieures de SD 3, MMDiT a réalisé des améliorations significatives en matière de compréhension et d'orthographe du texte.

Évaluation des performances
Basé sur des commentaires humains, le rapport technique compare SD 3 à un grand nombre de modèles open source SDXL, SDXL Turbo, Stable Cascade, Playground v2.5 et Pixart-α, ainsi que ainsi que les modèles à source fermée DALL·E 3, Midjourney v6 et Ideogram v1 ont été évalués en détail.
Les évaluateurs sélectionnent le meilleur résultat pour chaque modèle en fonction de la cohérence des invites spécifiées, de la clarté du texte et de l'esthétique globale des images.

Les résultats du test montrent que Stable Diffusion 3 a atteint ou dépassé le plus haut niveau de technologie actuelle de génération de diagrammes vincentiens, que ce soit en termes de précision dans le suivi des invites, de présentation claire du texte ou de beauté visuelle des images.
Le modèle SD 3, totalement non optimisé pour le matériel, possède des paramètres 8B, est capable de fonctionner sur un GPU grand public RTX 4090 avec 24 Go de mémoire vidéo et produit une résolution de 1024 x 1024 en utilisant 50 étapes d'échantillonnage. L'image prend 34 secondes. .
De plus, Stable Diffusion 3 fournira plusieurs versions lors de sa sortie, avec des paramètres allant de 800 millions à 8 milliards, ce qui peut encore abaisser le seuil matériel d'utilisation.

Détails architecturaux exposés
Dans le processus de génération du diagramme de Vincent, le modèle doit traiter deux types d'informations différents, le texte et l'image, en même temps. L'auteur appelle donc ce nouveau framework MMDiT.
Dans le processus de génération de texte en image, le modèle doit traiter deux types d'informations différents, le texte et l'image, en même temps. C'est pourquoi les auteurs appellent cette nouvelle technologie MMDiT (abréviation de Multimodal Diffusion Transformer).
Comme les versions précédentes de Stable Diffusion, SD 3 utilise un modèle pré-entraîné pour extraire des expressions appropriées de texte et d'images.
Plus précisément, ils ont utilisé trois encodeurs de texte différents (deux modèles CLIP et un T5) pour traiter les informations textuelles, tout en utilisant un modèle d'encodage automatique plus avancé pour traiter les informations d'image.
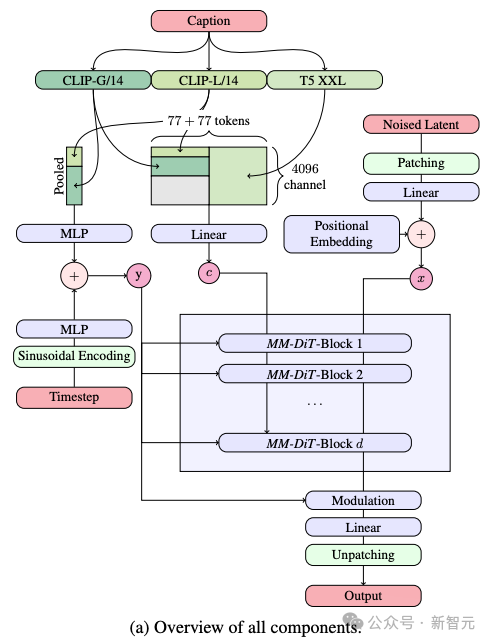
L'architecture du SD 3 est construite sur la base du Diffusion Transformer (DiT). En raison de la différence entre les informations textuelles et images, SD 3 définit des pondérations indépendantes pour chacun de ces deux types d'informations.
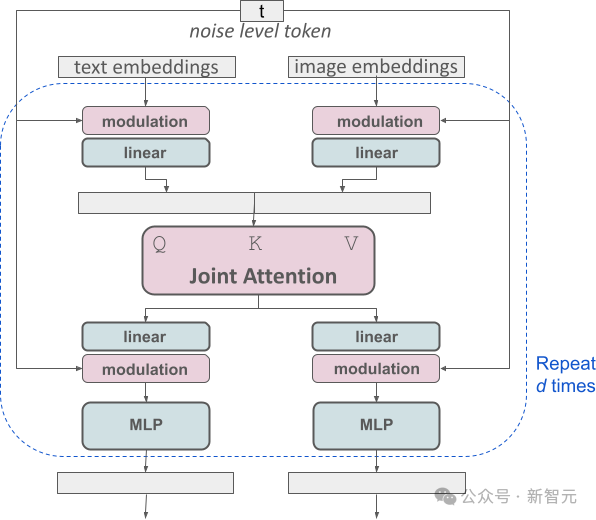
Cette conception équivaut à équiper deux transformateurs indépendants pour chaque type d'information, mais lors de l'exécution du mécanisme d'attention, les séquences de données des deux types d'informations seront fusionnées, afin qu'elles puissent fonctionner indépendamment dans leurs domaines respectifs et se maintenir. référence mutuelle et intégration.
Grâce à cette architecture unique, les informations d'image et de texte peuvent circuler et interagir les unes avec les autres, améliorant ainsi la compréhension globale du contenu et la représentation visuelle dans les résultats générés.
De plus, cette architecture pourra être facilement étendue à d'autres modalités, dont la vidéo dans le futur.

Grâce aux améliorations apportées par SD 3 aux invites suivantes, le modèle est capable de générer avec précision des images qui se concentrent sur une variété de thèmes et de fonctionnalités différents, tout en conservant un haut degré de flexibilité dans le style d'image.

Flux rectifié amélioré grâce à la méthode de repondération
En plus de la nouvelle architecture du transformateur de diffusion, SD 3 a également apporté des améliorations significatives au modèle de diffusion.
SD 3 adopte la stratégie Rectified Flow (RF) pour connecter les données d'entraînement et le bruit le long d'une trajectoire droite.
Cette méthode rend le chemin d'inférence du modèle plus direct, de sorte que la génération d'échantillons peut être effectuée en moins d'étapes.
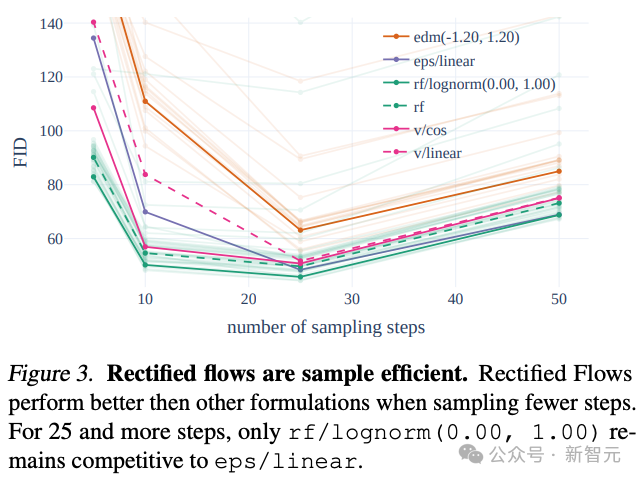
L'auteur a introduit un plan d'échantillonnage de trajectoire innovant dans le processus d'entraînement, en augmentant particulièrement le poids sur la partie médiane de la trajectoire, où la tâche de prédiction est plus difficile.
En comparant avec 60 autres trajectoires de diffusion (telles que LDM, EDM et ADM), les auteurs ont constaté que même si la méthode RF précédente fonctionnait mieux dans l'échantillonnage en quelques étapes, les performances diminuaient lentement à mesure que le nombre d'étapes d'échantillonnage augmentait. .
Afin d'éviter cette situation, la méthode RF pondérée proposée par l'auteur peut continuer à améliorer les performances du modèle.
Modèle de transformateur RF étendu
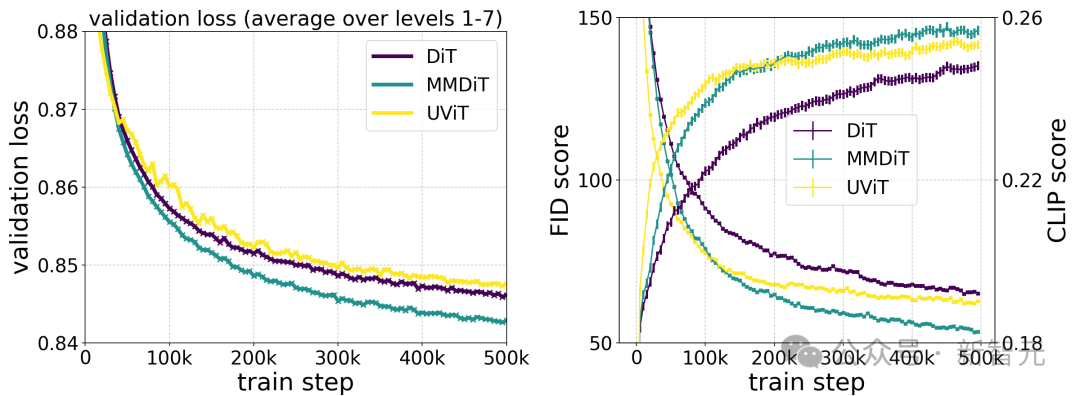
Stability AI a formé plusieurs modèles de différentes tailles, de 15 modules et 450 millions de paramètres à 38 modules et 8B paramètres, et a constaté que la taille du modèle et les étapes de formation peuvent réduire en douceur la perte de vérification.
Pour vérifier si cela signifiait une amélioration substantielle des résultats du modèle, ils ont également évalué les mesures d'alignement automatique des images et les scores de préférence humaine.
Les résultats montrent que ces indicateurs d'évaluation sont fortement corrélés à la perte de vérification, indiquant que la perte de vérification est un indicateur efficace pour mesurer la performance globale du modèle.
De plus, cette tendance à l'expansion n'a pas atteint un point de saturation, ce qui nous rend optimistes quant à la possibilité d'améliorer encore les performances du modèle à l'avenir.
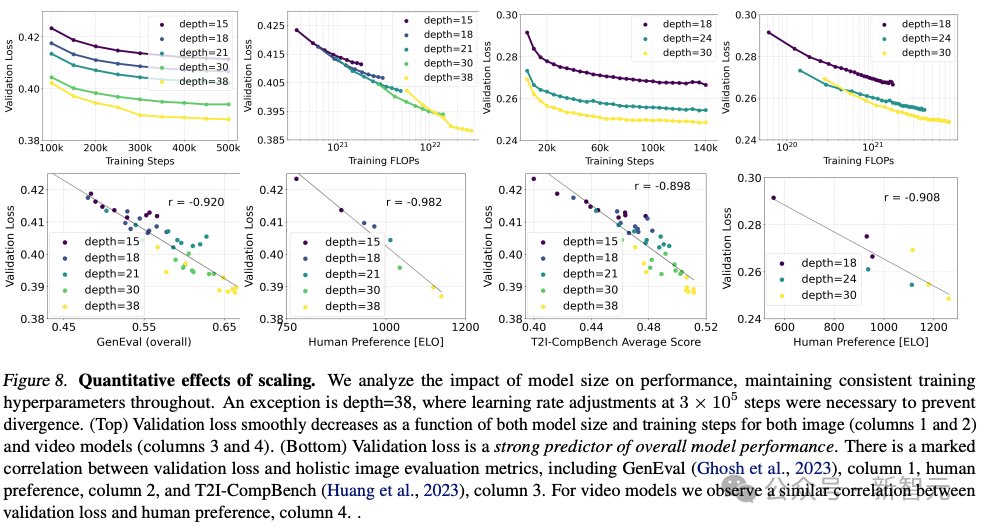
L'auteur a entraîné le modèle pour 500 000 étapes avec différents nombres de paramètres à une résolution de 256 * 256 pixels et une taille de lot de 4096.

La figure ci-dessus illustre l'impact de la formation d'un modèle plus grand pendant une longue période sur la qualité des échantillons.
Le tableau ci-dessus présente les résultats de GenEval. En utilisant la méthode de formation proposée par les auteurs et en augmentant la résolution des images de formation, le plus grand modèle a obtenu de bons résultats dans la plupart des catégories, dépassant DALL·E de 3 dans le score global.
Selon la comparaison des tests de l'auteur sur différents modèles d'architecture, MMDiT est très efficace, surpassant DiT, Cross DiT, UViT et MM-DiT.
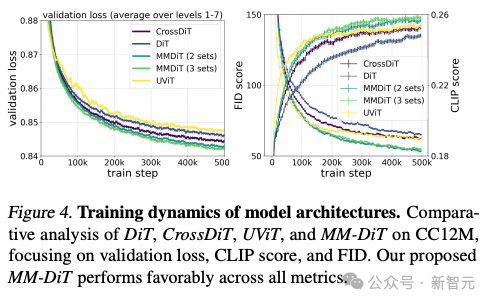
Encodeur de texte flexible
En supprimant l'encodeur de texte T5 à paramètre 4,7B gourmand en mémoire pendant la phase d'inférence, les besoins en mémoire du SD 3 sont considérablement réduits avec une perte de performances minimale.
La suppression de cet encodeur de texte n'affectera pas la beauté visuelle de l'image (taux de victoire de 50 % sans T5), mais ne réduira que légèrement la capacité du texte à suivre avec précision (taux de victoire de 46 %).
Cependant, afin de tirer pleinement parti de la capacité du SD 3 à générer du texte, l'auteur recommande toujours d'utiliser l'encodeur T5.
Parce que l'auteur a constaté que sans cela, les performances de composition du texte généré auraient une baisse plus importante (taux de victoire de 38%).

Discussion animée parmi les internautes
Les internautes sont un peu impatients face aux efforts continus de Stability AI pour taquiner les utilisateurs mais refusent de l'utiliser, et ils exhortent à le lancer le plus rapidement possible pour que tout le monde puisse l'utiliser .
Après avoir lu l'application technique, les internautes ont déclaré qu'il semble que le cercle de la photographie deviendra désormais la première piste où l'open source écrasera le fermé !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment construire un modèle mathématique en utilisant Python
- Fonctions du modèle TCP/IP à quatre couches
- Quelles sont les couches du modèle de référence TCP/IP ?
- Comment calculer la taille du modèle de boîte CSS
- Dans la technologie des bases de données, quels sont les quatre principaux modèles de données ?