
Maison >Périphériques technologiques >IA >L'ère du GPT-4 est-elle révolue ? Les internautes du monde entier ont testé Claude 3 et ont été choqués
L'ère du GPT-4 est-elle révolue ? Les internautes du monde entier ont testé Claude 3 et ont été choqués

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2024-03-06 13:00:18580parcourir
Le sens du texte en clair du grand modèle a été roulé jusqu'au bout ?
Hier soir, Anthropic, le plus grand concurrent d'OpenAI, a lancé une nouvelle génération de séries de grands modèles d'IA - Claude 3.
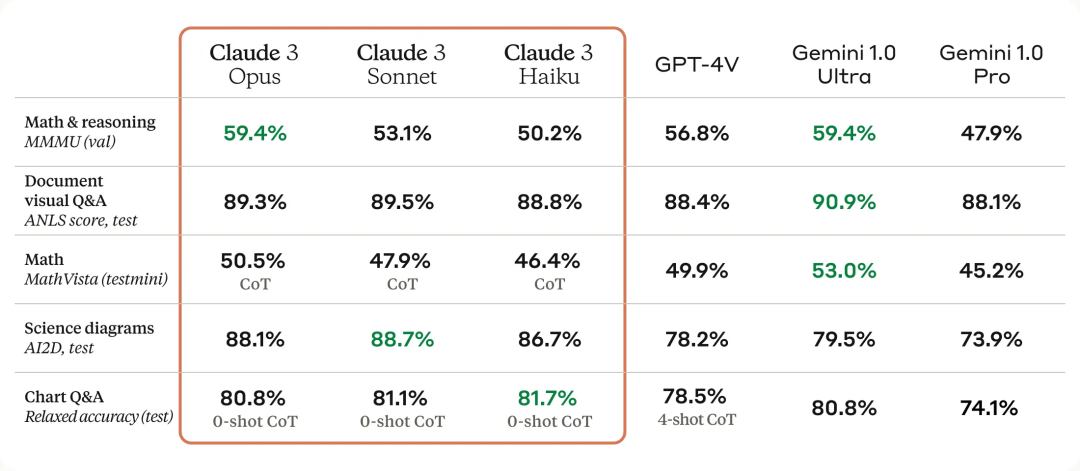
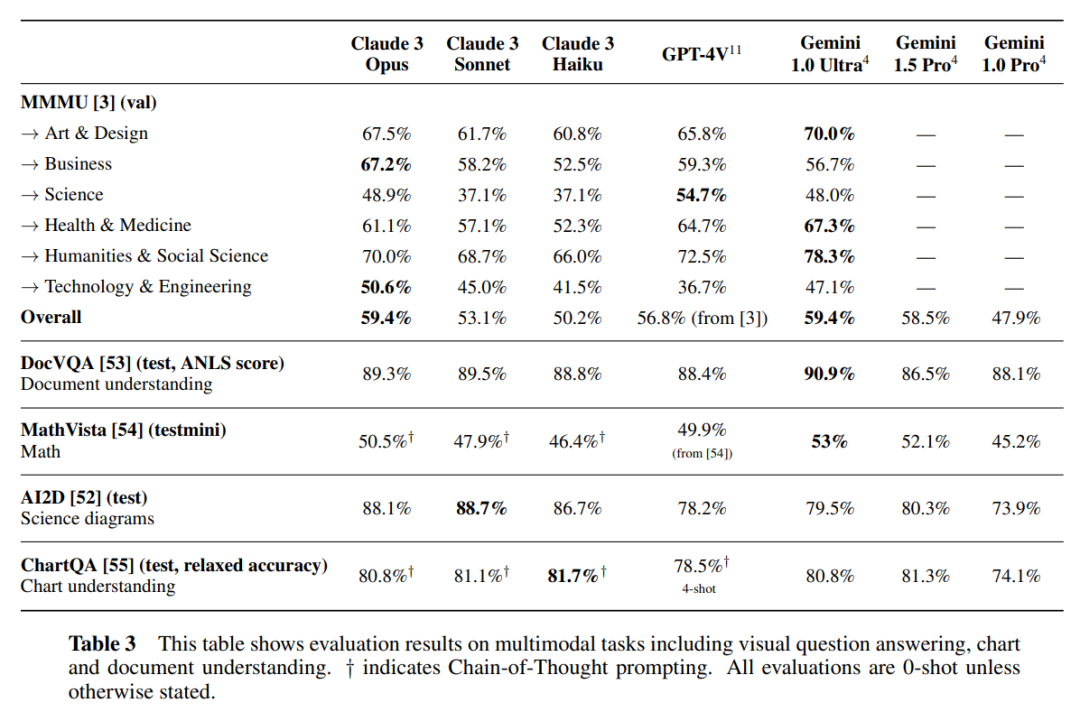
Cette série contient trois modèles, classés du plus faible au plus fort, à savoir Claude 3 Haiku, Claude 3 Sonnet et Claude 3 Opus. Parmi eux, Opus, le plus performant, a obtenu des scores supérieurs à GPT-4 et Gemini 1.0 Ultra dans plusieurs tests de référence, établissant de nouvelles références industrielles dans plusieurs dimensions telles que les mathématiques, la programmation, la compréhension multilingue et la vision.
Anthropic déclare que Claude 3 Opus possède des connaissances humaines de niveau premier cycle.
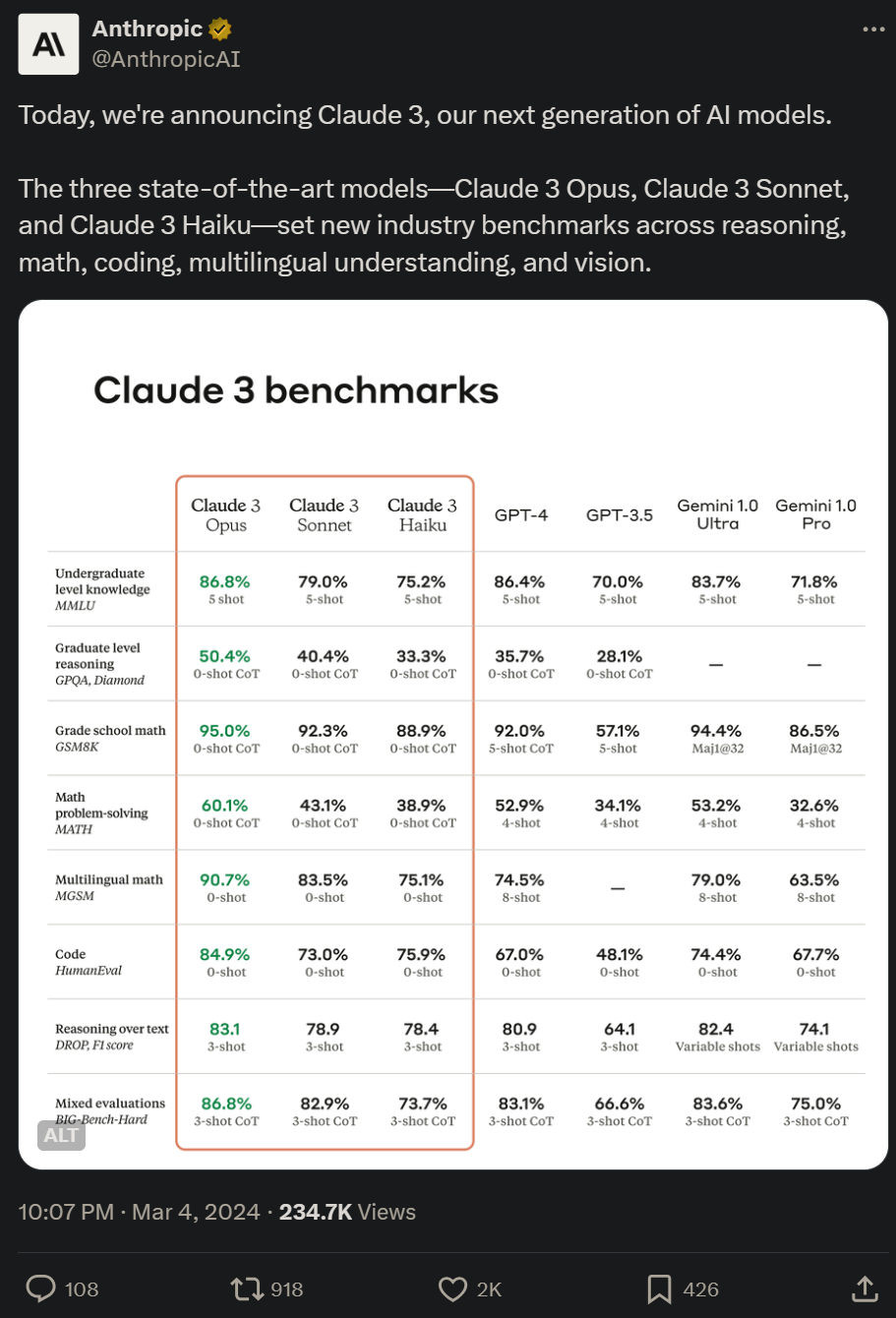
Après la sortie du nouveau modèle, Claude apporte pour la première fois la prise en charge des capacités multimodales (le score MMMU de la version Opus est de 59,4%, dépassant GPT-4V et à égalité avec Gemini 1.0 Ultra ). Les utilisateurs peuvent désormais télécharger des photos, des graphiques, des documents et d’autres types de données non structurées pour que l’IA puisse les analyser et y répondre.
De plus, ces trois modèles conservent également l'avantage constant des modèles de la série Claude, à savoir la longue fenêtre contextuelle. La phase initiale prend en charge une fenêtre contextuelle de 200 000 jetons, mais Anthropic a déclaré que les trois modèles prennent en charge une entrée contextuelle de 1 million de jetons (pour des clients spécifiques), ce qui équivaut à la version anglaise de "Moby Dick" ou "Harry Potter et le Reliques de la Mort" 》longueur.
Cependant, en termes de prix, le Claude 3 le plus puissant est également beaucoup plus cher que le GPT-4 Turbo : GPT-4 Turbo facture 10/30 USD par million d'entrée/sortie de jeton tandis que le Claude 3 Opus coûte 15 $/$ ; 75.
Les modèles Opus et Sonnet sont désormais disponibles dans claude.ai et Claude API, avec des modèles Haiku à venir. Amazon Cloud Technologies a annoncé que son nouveau modèle est désormais disponible sur Amazon Bedrock. Anthropic a annoncé la démo officielle, les détails sont les suivants :
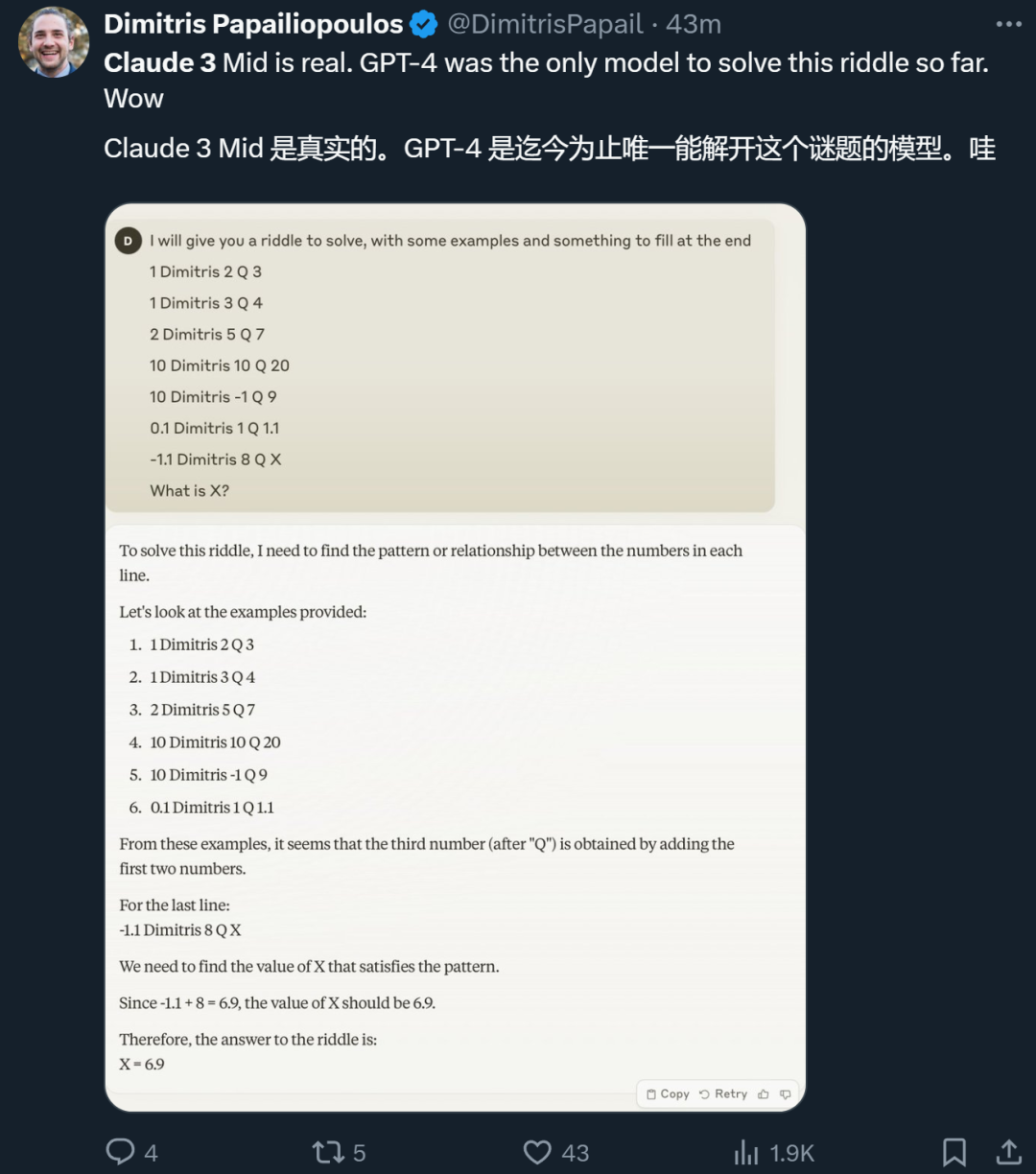
Après l'annonce officielle d'Anthropic, de nombreux chercheurs qui ont eu l'occasion de l'essayer ont également partagé leurs expériences. Certains disent que Claude 3 Sonnet a résolu une énigme que seul GPT-4 pouvait résoudre auparavant.
Cependant, certaines personnes ont dit qu'en termes d'expérience réelle, Claude 3 n'avait pas complètement vaincu GPT-4.
Test réel de première main de Claude 3
Adresse : https://claude.ai/
Claude 3 dépasse-t-il vraiment le GPT en termes de performances, comme le prétend officiellement -4 ? ? À l’heure actuelle, la plupart des gens pensent que cela a une certaine signification.
Voici quelques résultats de mesures réels :
Tout d’abord, faisons un casse-tête. Quel mois compte vingt-huit jours ? La vraie bonne réponse est chaque mois. Il semble que Claude 3 ne soit pas encore doué pour poser ce genre de questions.
Ensuite, nous avons testé les domaines dans lesquels Claude 3 est bon. Dès l'introduction officielle, nous pouvons voir que Claude est doué pour "comprendre et traiter des images", notamment extraire du texte à partir d'images, convertir l'interface utilisateur en front-. code final et compréhension d'équations complexes, transcription de notes manuscrites, etc.
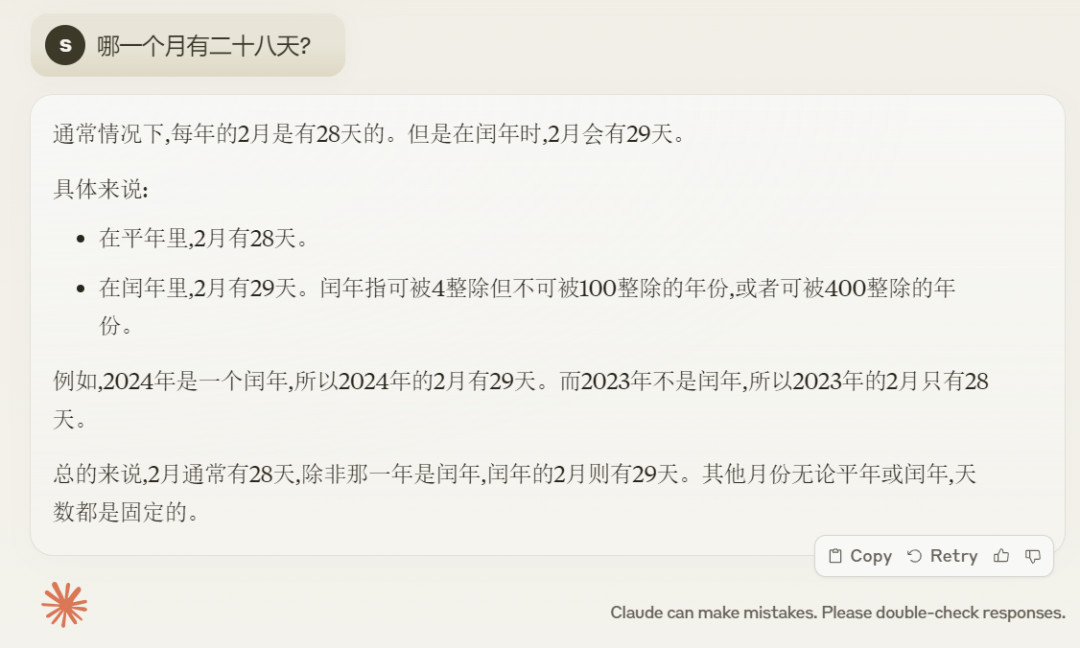
Pour les grands modèles, il est souvent difficile de faire la distinction entre un poulet frit et un nounours. Lorsque nous saisissons une image contenant un nounours et un poulet frit, Claude 3 a donné la réponse "Cette image est un ensemble d'un collage contenant un chien et un poulet. des nuggets ou des nuggets qui ressemblent de façon frappante au chien lui-même... » Cette question est adoptée.
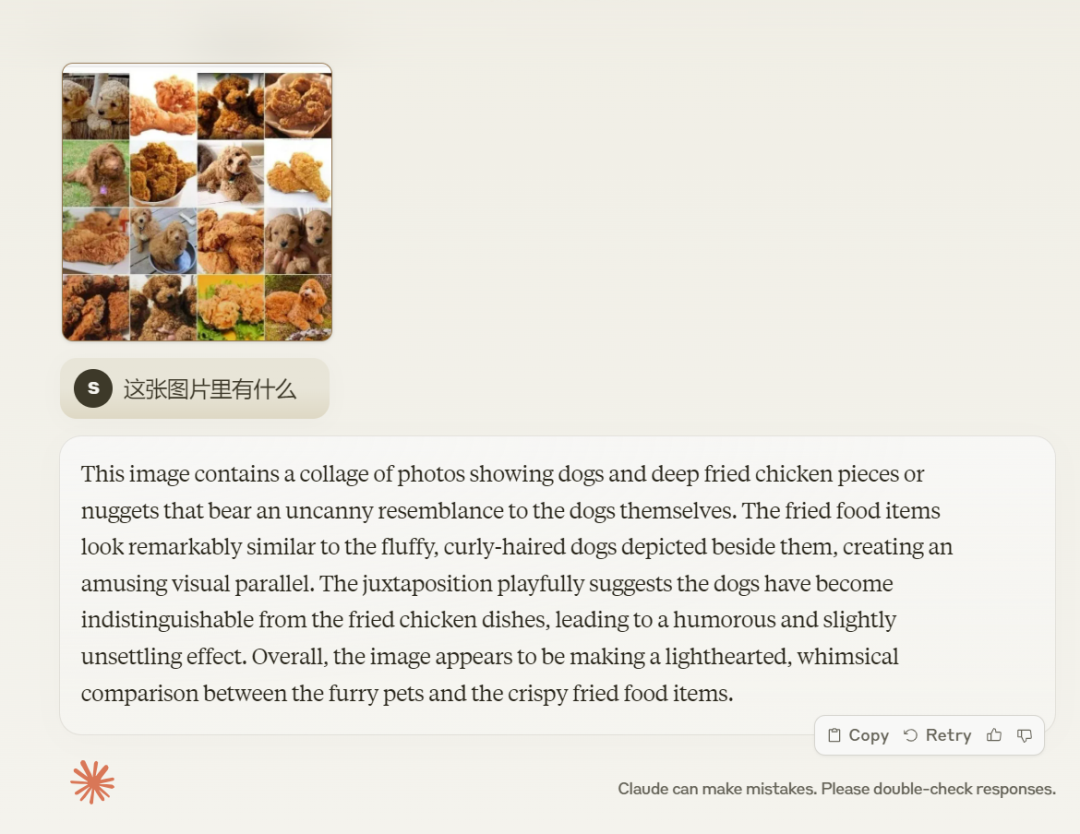
Lorsqu'on lui a demandé combien de personnes il y avait dedans, Claude 3 a également répondu correctement : "Cette animation représente sept petits personnages de dessins animés."
Claude 3 peut extraire du texte à partir de photos, même l'ordre vertical du chinois et du japonais peut être correctement reconnu :

Si j'utilise des mèmes sur Internet, comment va-t-il les gérer ? Concernant l'image de l'erreur visuelle, GPT-4 et Claude3 ont donné des suppositions opposées :
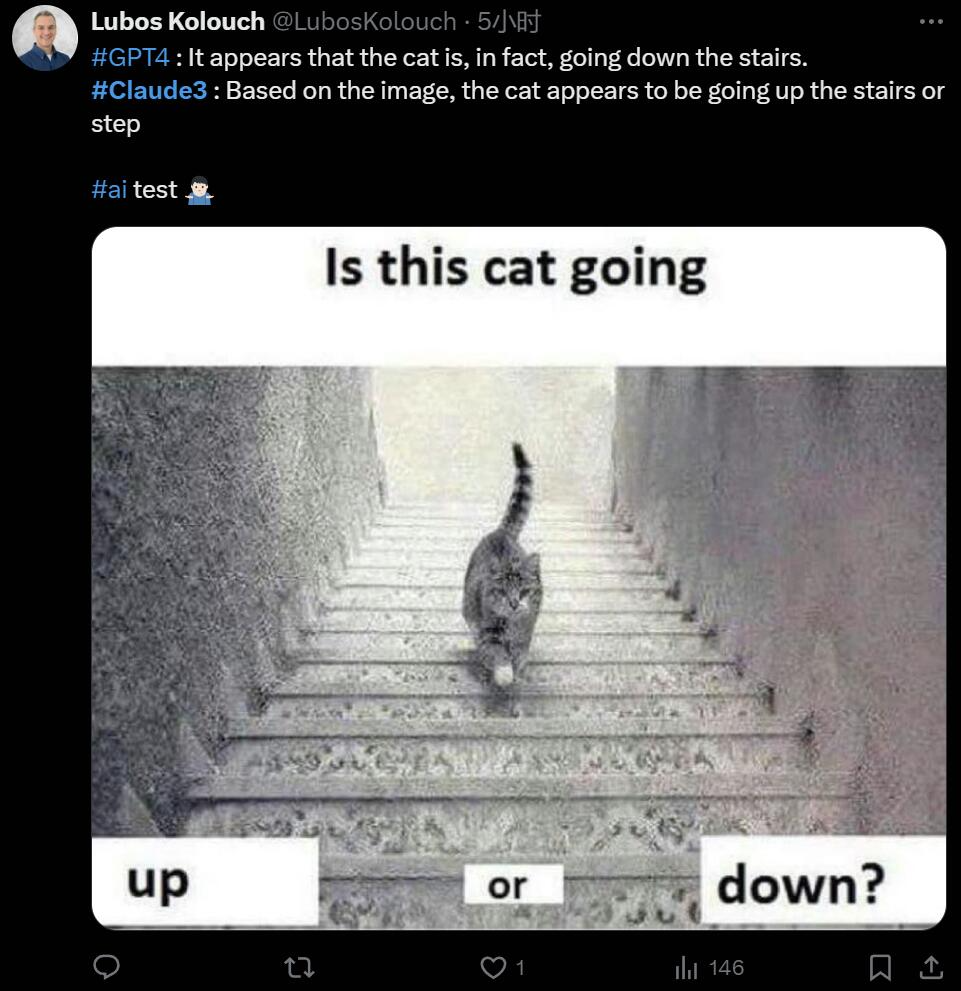
Laquelle a raison ?
En plus de comprendre les images, Claude est également capable de traiter des textes longs. La série complète de grands modèles publiée cette fois peut fournir 200 000 fenêtres contextuelles et accepter plus d'un million d'entrées de jetons.
Comment est l'effet ? Nous lui avons remis un article récent « The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits » publié par Microsoft et l'Université nationale des sciences et technologies, et lui avons demandé de résumer les principaux points de l'article sous la forme de 1, 2 et 3. Nous l'avons enregistré Temps, le temps pour afficher la réponse globale est d'environ 15 secondes.
Mais ce n'est que l'effet de sortie de Claude 3 Sonnet Si vous utilisez la version Claude Pro, ce sera plus rapide, mais cela coûtera 20 $ par mois.
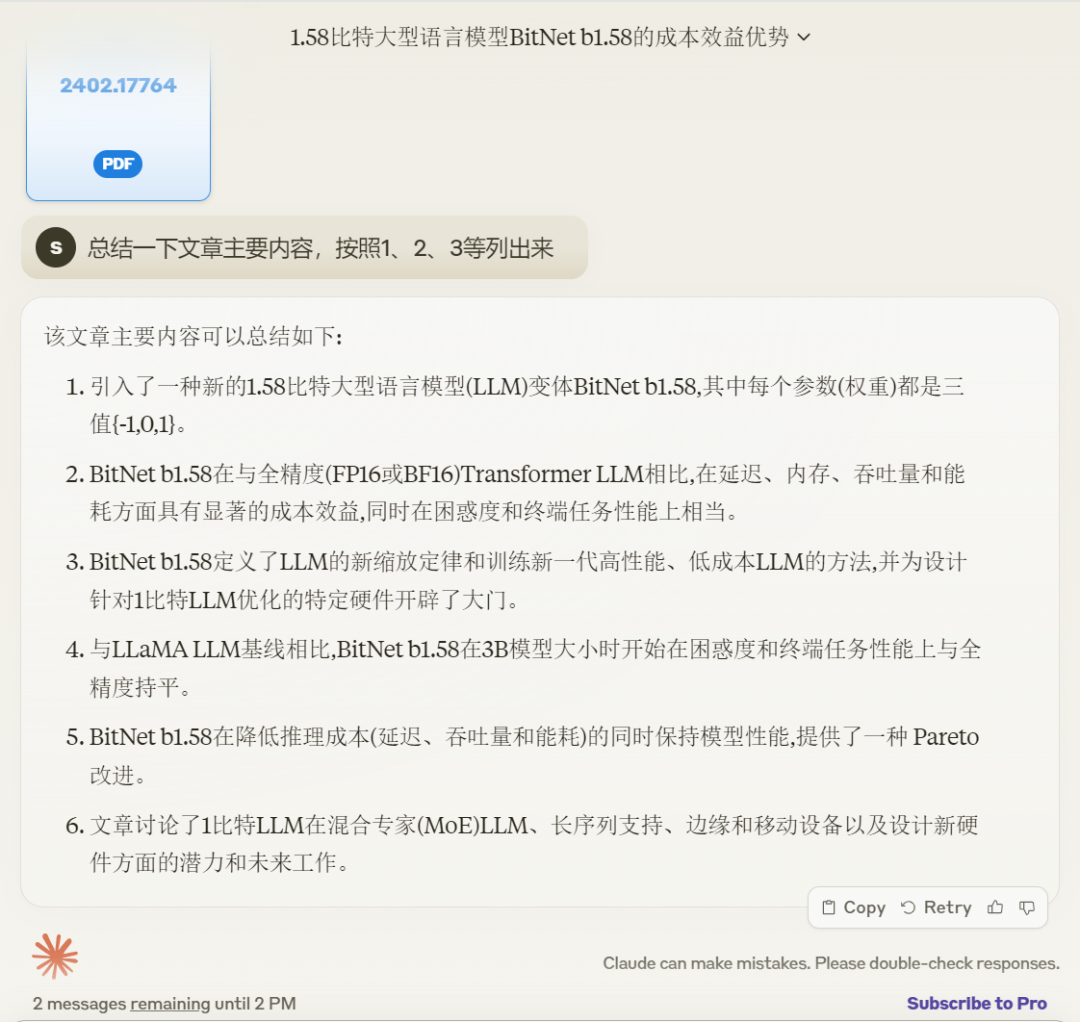
Il est à noter que Claude exige désormais que la taille de l'article téléchargé ne dépasse pas 10 Mo. Si elle dépasse, il y aura une invite :

Dans le blog de Claude 3, Anthropic. a proposé que les capacités de codage du nouveau modèle soient considérablement améliorées, quelqu'un a directement jeté le code ASCII de base à Claude et a constaté qu'il n'y avait aucune pression :
Nous devrions être en mesure de confirmer que Claude 3 a des capacités de codage plus fortes que GPT-4.
Il y a quelque temps, Karpathy, qui vient de démissionner d'OpenAI, a proposé un défi de "segmentateur de mots". Plus précisément, il a mis son didacticiel vidéo de 2 heures et 13 minutes dans LLM et l'a fait traduire sous la forme d'un chapitre de livre ou d'un article de blog sur les tokenizers.
Face à cette tâche, Claude 3 l'a relevée. Voici le résultat posté par Emmanuel Ameisen, ingénieur de recherche chez AnthropicAI :
 Peut-être que ce n'est plus d'actualité, Karpathy a donné une évaluation relativement complète et objective :
Peut-être que ce n'est plus d'actualité, Karpathy a donné une évaluation relativement complète et objective :
D'un point de vue style, c'est effectivement plutôt bien ! Si vous regardez attentivement, vous remarquerez des problèmes/illusions subtils. Quoi qu’il en soit, c’est impressionnant d’avoir un système qui fonctionne presque immédiatement. J'ai hâte de jouer davantage avec le Claude 3, ça a l'air d'être un modèle costaud. 
S'il y a quelque chose de pertinent à dire, c'est que les gens doivent être extrêmement prudents lorsqu'ils font des comparaisons d'évaluations, non seulement parce que les résultats d'évaluation eux-mêmes sont pires que vous ne le pensez, mais aussi parce que de nombreux résultats d'évaluation se terminent par Il est surajusté dans d'une manière indéfinie, notamment parce que les comparaisons effectuées peuvent être trompeuses. Le taux d'encodage (HumanEval) de GPT-4 n'est pas de 67 %. Chaque fois que je vois cette comparaison utilisée à la place des performances de codage, les coins de mes yeux commencent à se contracter.
Sur la base des différents résultats de tests délicats ci-dessus, certaines personnes ont déjà crié "Anthropic est tellement de retour".
Enfin, anthropopic a également lancé une bibliothèque d'invites contenant du contenu d'invite dans plusieurs directions. Si vous souhaitez en savoir plus sur les nouvelles fonctionnalités de Claude 3, essayez-le.
Lien : https://docs.anthropic.com/claude/prompt-library
Modèles Claude 3 Series
Les trois versions des modèles Claude 3 Series sont Claude 3 Opus, Claude 3 Sonnet et Claude 3 Haïku.
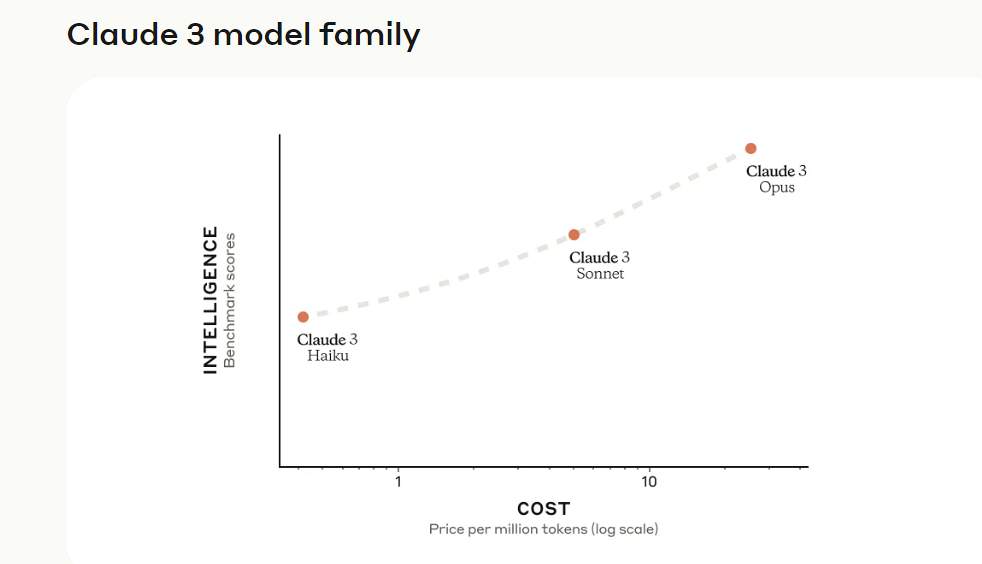
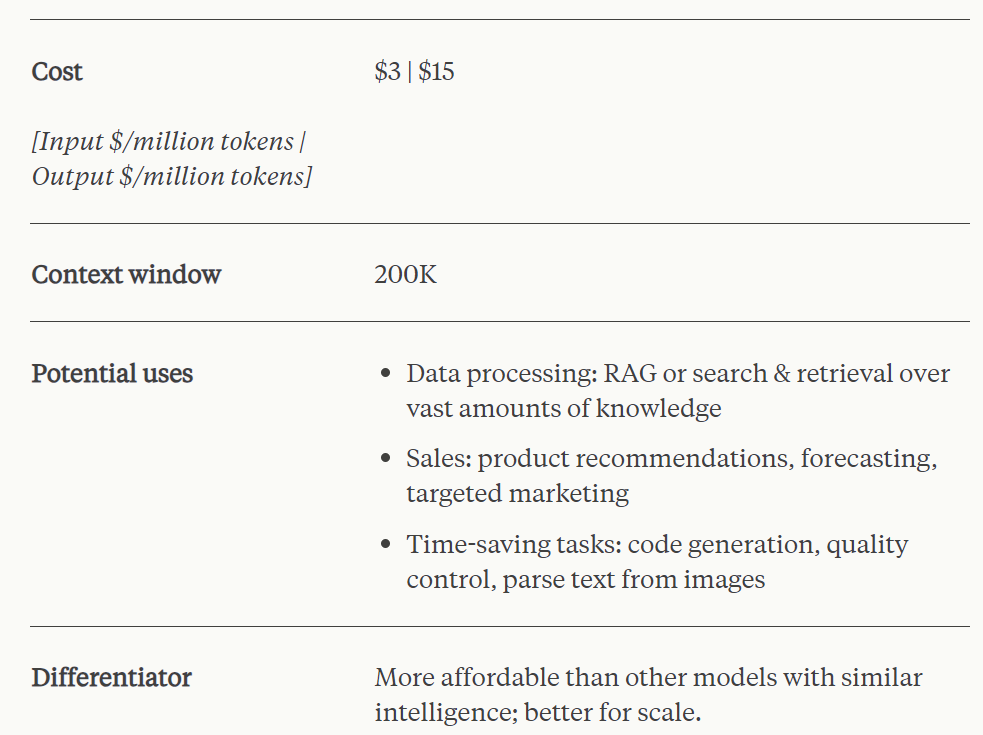
Parmi eux, Claude 3 Opus est le modèle le plus intelligent, prenant en charge une fenêtre contextuelle de 200 000 jetons et atteignant les performances SOTA actuelles sur des tâches très complexes. Le modèle gère les invites ouvertes et les scènes inédites avec une excellente maîtrise et une compréhension au niveau humain. Claude 3 Opus nous montre les limites du possible avec l'IA générative.

Claude 3 Sonnet offre l'équilibre idéal entre intelligence et rapidité, notamment pour les charges de travail des entreprises. Il offre des performances puissantes à un coût inférieur à celui des modèles similaires et est conçu pour une grande durabilité dans les déploiements d'IA à grande échelle. Claude 3 Sonnet prend en charge une fenêtre contextuelle de 200 000 jetons.
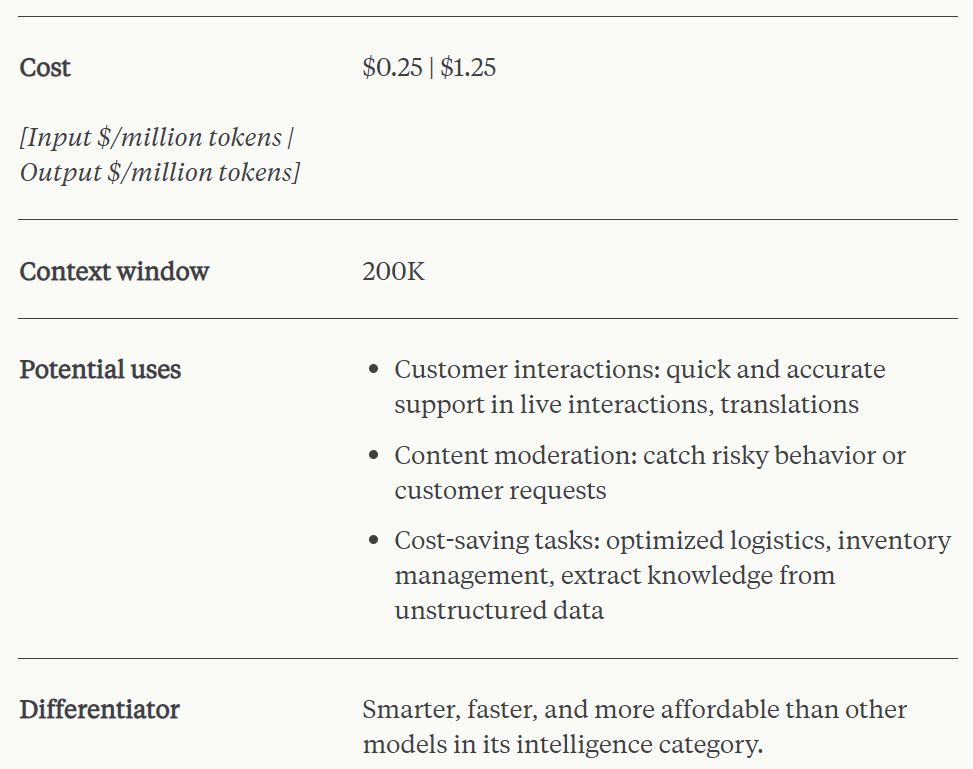
Claude 3 Haiku est le modèle le plus rapide et le plus compact avec une réactivité quasi en temps réel. Fait intéressant, la fenêtre contextuelle qu'il prend en charge est également de 200 Ko. Le modèle est capable de répondre à des requêtes et requêtes simples à une vitesse inégalée, permettant aux utilisateurs de créer des expériences d’IA transparentes qui imitent les interactions humaines.
Ensuite, examinons en détail les caractéristiques et les performances des modèles de la série Claude 3.
Surpassant largement GPT-4 et atteignant un nouveau niveau d'intelligence SOTA
En tant que modèle le plus intelligent de la série Claude 3, Opus surpasse les produits concurrents sur la plupart des critères d'évaluation des systèmes d'IA, y compris les experts de premier cycle. (MMLU), raisonnement expert de niveau supérieur (GPQA), mathématiques de base (GSM8K) et autres critères de référence. De plus, Opus démontre une compréhension et une maîtrise proches du niveau humain sur des tâches complexes, à la pointe de l’intelligence générale.
De plus, tous les modèles Claude Série 3, y compris Opus, disposent de capacités améliorées en matière d'analyse et de prédictions, de création de contenu granulaire, de génération de code et de conversation dans des langues autres que l'anglais telles que l'espagnol, le japonais et le français.
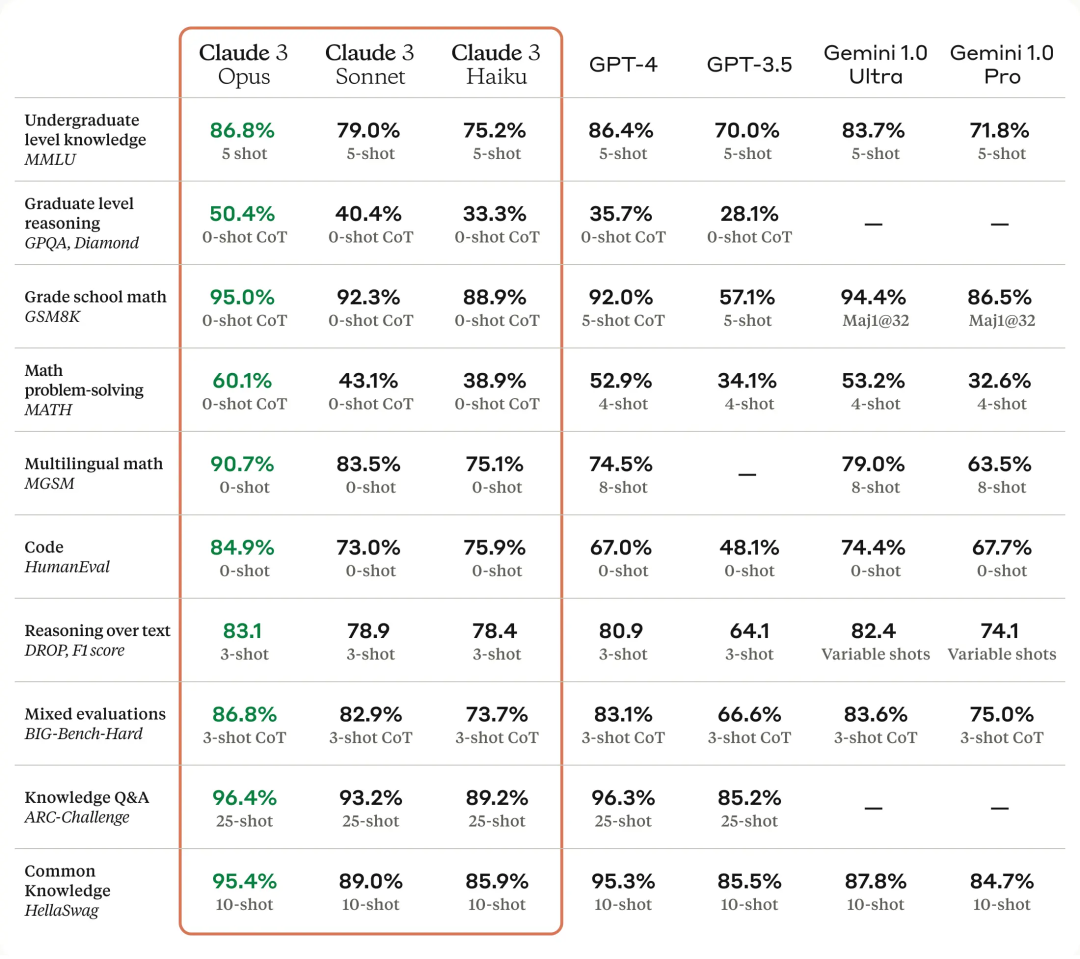
L'image ci-dessous montre la comparaison entre le modèle Claude 3 et les modèles concurrents sur plusieurs benchmarks de performances. On peut voir que l'Opus le plus puissant est meilleur que le GPT-4 d'OpenAI.
Réponse en temps quasi réel
Le modèle Claude 3 peut prendre en charge des tâches telles que le chat client en direct, le réapprovisionnement automatique et l'extraction de données où la réponse doit être immédiate et en temps réel.
Haiku est le modèle le plus rapide et le plus rentable du marché dans la catégorie intelligente. Il peut lire un document de la plateforme arXiv (~ 10 000 jetons) contenant des graphiques denses et des informations graphiques en moins de trois secondes.
Pour la grande majorité des travaux, Sonnet est 2x plus rapide et plus intelligent que Claude 2 et Claude 2.1. Il excelle dans les tâches qui nécessitent des réponses rapides, telles que la récupération de connaissances ou l'automatisation des ventes. L'Opus est similaire en vitesse aux Claude 2 et 2.1, mais avec un niveau d'intelligence plus élevé.
Capacités visuelles puissantes
Claude 3 possède des capacités visuelles sophistiquées comparables à celles d'autres modèles de tête. Ils peuvent traiter les données dans divers formats visuels, notamment des photos, des tableaux, des graphiques et des diagrammes techniques.
Anthropic affirme que certains de ses clients ont plus de 50 % de leurs bases de connaissances programmées dans divers formats de données, tels que des PDF, des organigrammes ou des diapositives de présentation. Les puissantes capacités visuelles du nouveau modèle sont donc très utiles.
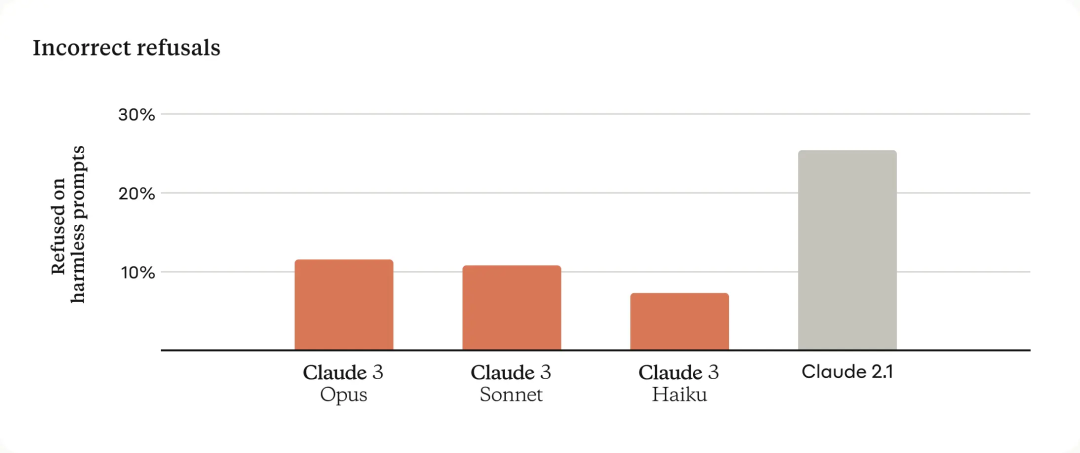
Moins de réponses de refus
Le modèle Claude précédent faisait souvent des rejets inutiles, indiquant un manque de compréhension contextuelle de la part du modèle. Anthropic a fait des progrès significatifs dans ce domaine : Opus, Sonnet et Haiku sont nettement moins susceptibles de rejeter une réponse que les générations précédentes de modèles, même lorsque les invites des utilisateurs sont proches du résultat net du système. Comme indiqué ci-dessous, le modèle Claude 3 présente une compréhension plus nuancée des demandes, est capable d'identifier les invites véritablement nuisibles et refuse beaucoup moins fréquemment de répondre aux invites inoffensives.
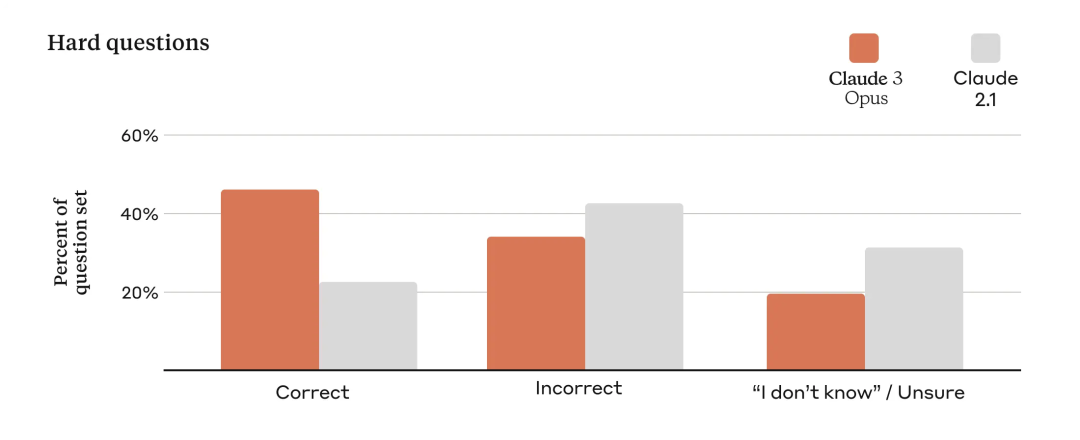
Précision améliorée
Pour évaluer la précision du modèle, Anthropic a utilisé un certain nombre de questions complexes basées sur des faits pour remédier aux faiblesses connues des modèles actuels. Anthropic classe les réponses en réponses correctes, réponses incorrectes (ou hallucinations) et réponses incertaines, où le modèle ne connaît pas la réponse, plutôt que de fournir des informations incorrectes. Par rapport à Claude 2.1, Opus a doublé la précision (ou les réponses correctes) de ces questions ouvertes difficiles tout en réduisant les réponses incorrectes.
En plus de produire des réponses plus fiables, Anthropic permettra les citations dans le modèle Claude 3 afin que le modèle puisse pointer vers des phrases précises dans le matériel de référence pour corroborer les réponses.
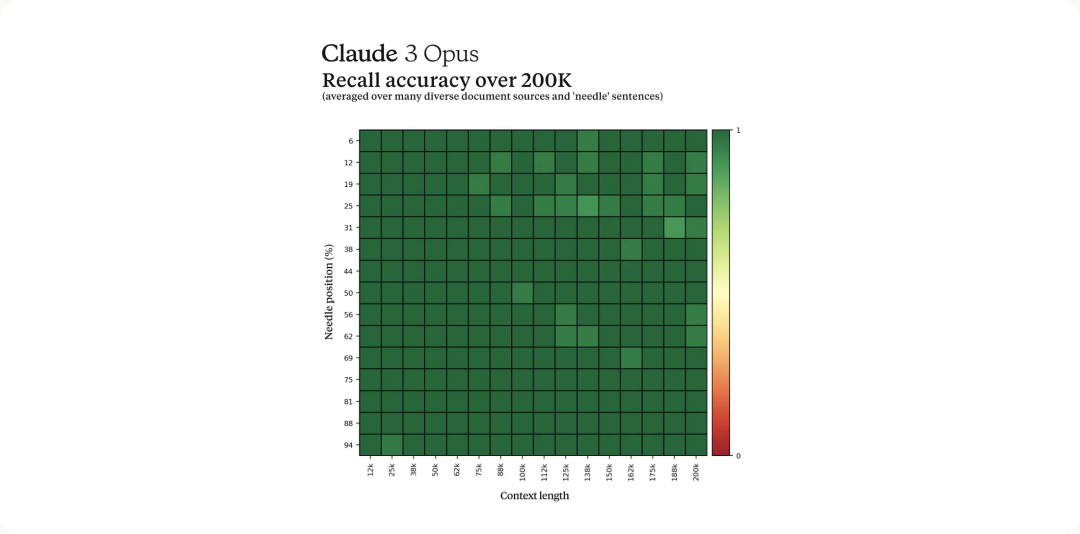
Contexte long et rappel quasi parfait
Les modèles de la série Claude 3 offriront dans un premier temps une fenêtre contextuelle de 200K au lancement. Cependant, les responsables déclarent que les trois modèles sont capables de recevoir des entrées de plus d'un million de jetons, et que cette capacité sera fournie à des utilisateurs spécifiques qui ont besoin de capacités de traitement améliorées.
Afin de gérer efficacement les longs signaux contextuels, le modèle a besoin de fortes capacités de rappel. L'évaluation Needle In A Haystack (NIAH) mesure la capacité d'un modèle à rappeler avec précision des informations à partir de grandes quantités de données. Anthropic a amélioré la robustesse de ce benchmark en le testant sur une base de documents collaborative différente en utilisant 30 paires aléatoires d'aiguilles/questions dans chaque invite. Claude 3 Opus atteint non seulement un rappel presque parfait, mais dépasse également 99 % de précision. Et dans certains cas, il a même identifié des limites dans l'évaluation elle-même, réalisant que les phrases « aiguilles » semblaient avoir été artificiellement insérées dans le texte original.
Sécurisé et facile à utiliser
Anthropic a déclaré avoir mis en place une équipe dédiée pour suivre et réduire les risques de sécurité. La société développe également des méthodes telles que Constitutional AI pour améliorer la sécurité et la transparence des modèles et atténuer les problèmes de confidentialité que les nouveaux modèles peuvent soulever.
Bien que la série de modèles Claude 3 ait apporté des améliorations aux indicateurs clés des connaissances biologiques, des connaissances liées au réseau et de l'autonomie par rapport aux modèles précédents, selon les recherches, le nouveau modèle est au niveau de sécurité AI 2 (ASL-2). .
En termes d'expérience utilisateur, Claude 3 est plus à même de suivre des instructions complexes en plusieurs étapes que les modèles précédents, et est mieux à même de respecter les directives de marque et de réponse, afin de mieux développer des applications dignes de confiance. De plus, Anthropic affirme que les modèles Claude 3 sont désormais plus efficaces pour produire des sorties structurées populaires dans des formats tels que JSON, ce qui facilite le guidage de Claude pour des cas d'utilisation tels que la classification du langage naturel et l'analyse des sentiments.
Ce qui est écrit dans le rapport technique
Actuellement, Anthropic a publié un rapport technique de 42 pages "La famille de modèles Claude 3 : Opus, Sonnet, Haiku".

Adresse du rapport : https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf
Données de formation, critères d'évaluation et plus encore résultats expérimentaux détaillés.
En termes de données d'entraînement, les modèles de la série Claude 3 sont entraînés sur un mélange propriétaire de données accessibles au public sur Internet à compter d'août 2023, ainsi que de données non publiques provenant de tiers, de données fournies par des services d'étiquetage de données et entrepreneurs rémunérés, données internes de Claude.
Les modèles de la série Claude 3 ont été évalués de manière approfondie sur plusieurs paramètres, notamment :
语Une capacité de raisonnement 言 Capacité multi-langue- Contexte long
- Fréquence de fiabilité/faits
- Capacité multi-mode
- Tout d'abord, en raisonnement, en programmation et en questions/réponses tâches À la suite de l'évaluation, les modèles de la série Claude 3 ont été comparés à des modèles concurrents sur une série de références standard de l'industrie pour le raisonnement, la compréhension en lecture, les mathématiques, les sciences et la programmation. Les résultats ont montré qu'ils surpassaient non seulement leurs modèles précédents, mais aussi. également atteint dans la plupart des cas Nouveau SOTA.
Anthropic a évalué les modèles Claude 3 Series au test d'admission à la faculté de droit (LSAT), au Multistate Bar Examination (MBE), au USA Mathematical Competition 2023 Math Competition et à l'examen général Graduate Record Examination (GRE), en particulier le les résultats sont présentés dans le tableau 2 ci-dessous.
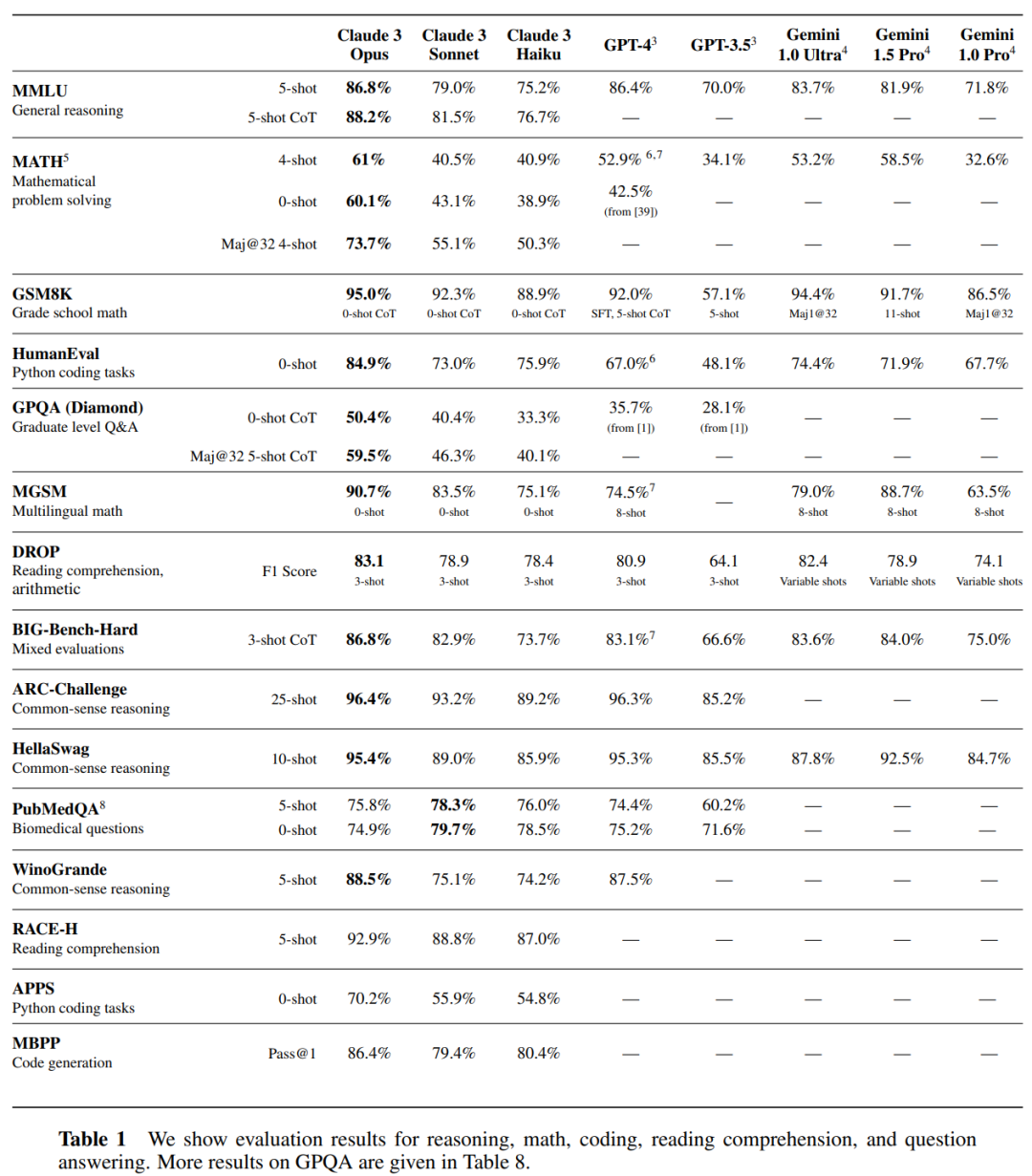
Les modèles de la série Claude 3 sont multimodaux (saisie d'images et d'images vidéo) et ont fait des progrès significatifs dans la résolution de défis de raisonnement multimodal complexes au-delà de la simple compréhension de texte.
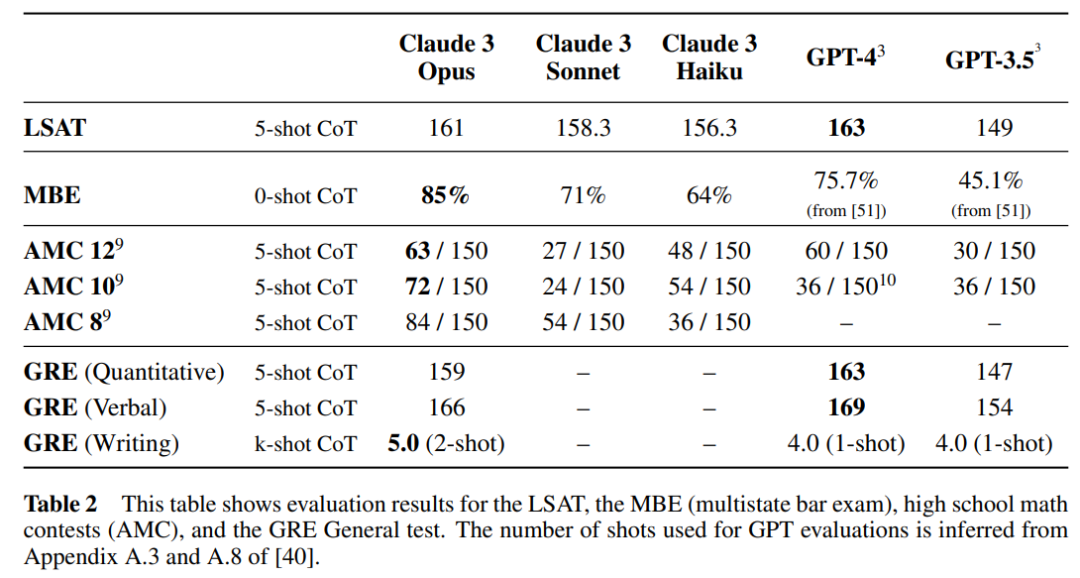 Un exemple typique est la performance du modèle Claude 3 sur le benchmark AI2D Scientific Charts, une évaluation visuelle de réponse aux questions qui implique l'analyse de graphiques et la réponse aux questions correspondantes dans un format à choix multiples.
Un exemple typique est la performance du modèle Claude 3 sur le benchmark AI2D Scientific Charts, une évaluation visuelle de réponse aux questions qui implique l'analyse de graphiques et la réponse aux questions correspondantes dans un format à choix multiples.
Claude 3 Sonnet a atteint le niveau SOTA dans le réglage 0-shot - 89,2%, suivi de Claude 3 Opus (88,3%) et Claude 3 Haiku (80,6%). Les résultats spécifiques sont présentés dans le tableau 3 ci-dessous.
Concernant ce rapport technique, Fu Yao, doctorant à l'Université d'Édimbourg, a immédiatement donné sa propre analyse.
 Tout d'abord, à son avis, les différents modèles évalués n'ont fondamentalement aucune distinction dans plusieurs indicateurs tels que MMLU / GSM8K / HumanEval. Ce dont il faut vraiment se préoccuper, c'est pourquoi le meilleur modèle a encore 5% d'erreur GSM8K. .
Tout d'abord, à son avis, les différents modèles évalués n'ont fondamentalement aucune distinction dans plusieurs indicateurs tels que MMLU / GSM8K / HumanEval. Ce dont il faut vraiment se préoccuper, c'est pourquoi le meilleur modèle a encore 5% d'erreur GSM8K. .
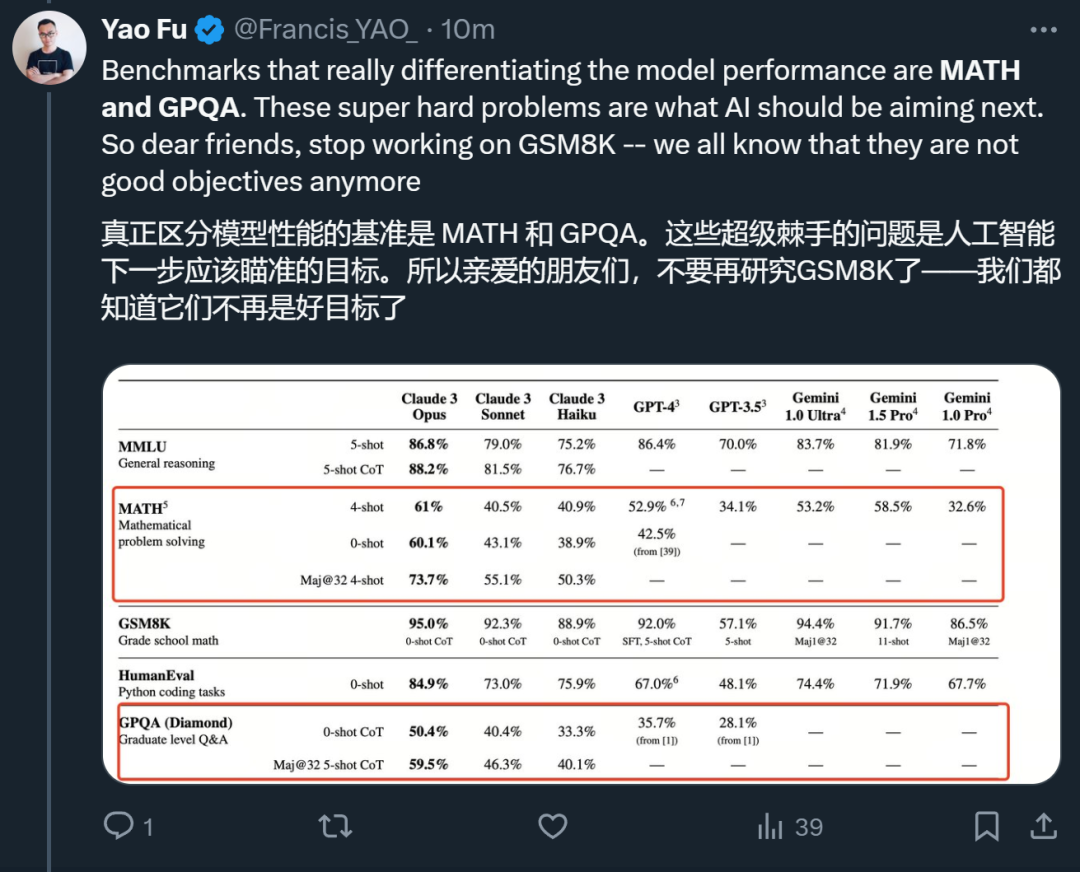
Ce qui peut vraiment distinguer les modèles, ce sont MATH et GPQA. Ces problèmes super épineux sont les objectifs que les modèles d'IA devraient viser ensuite.
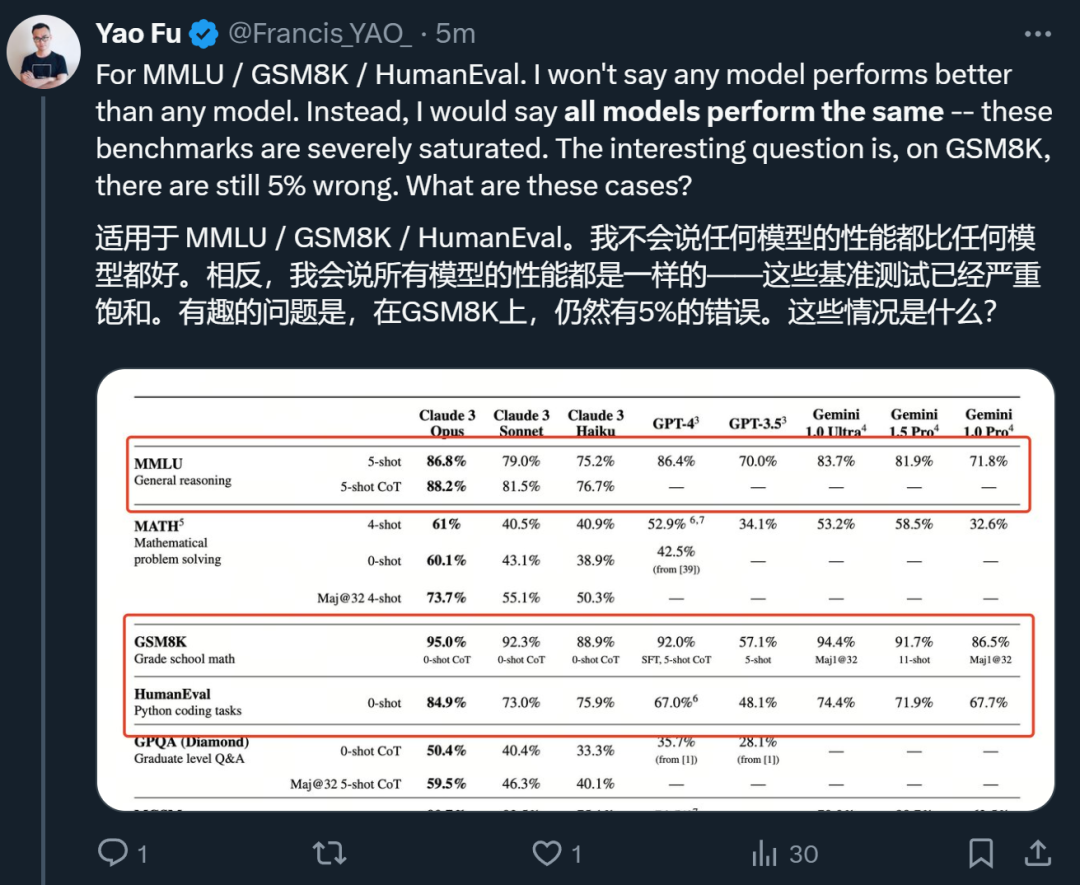
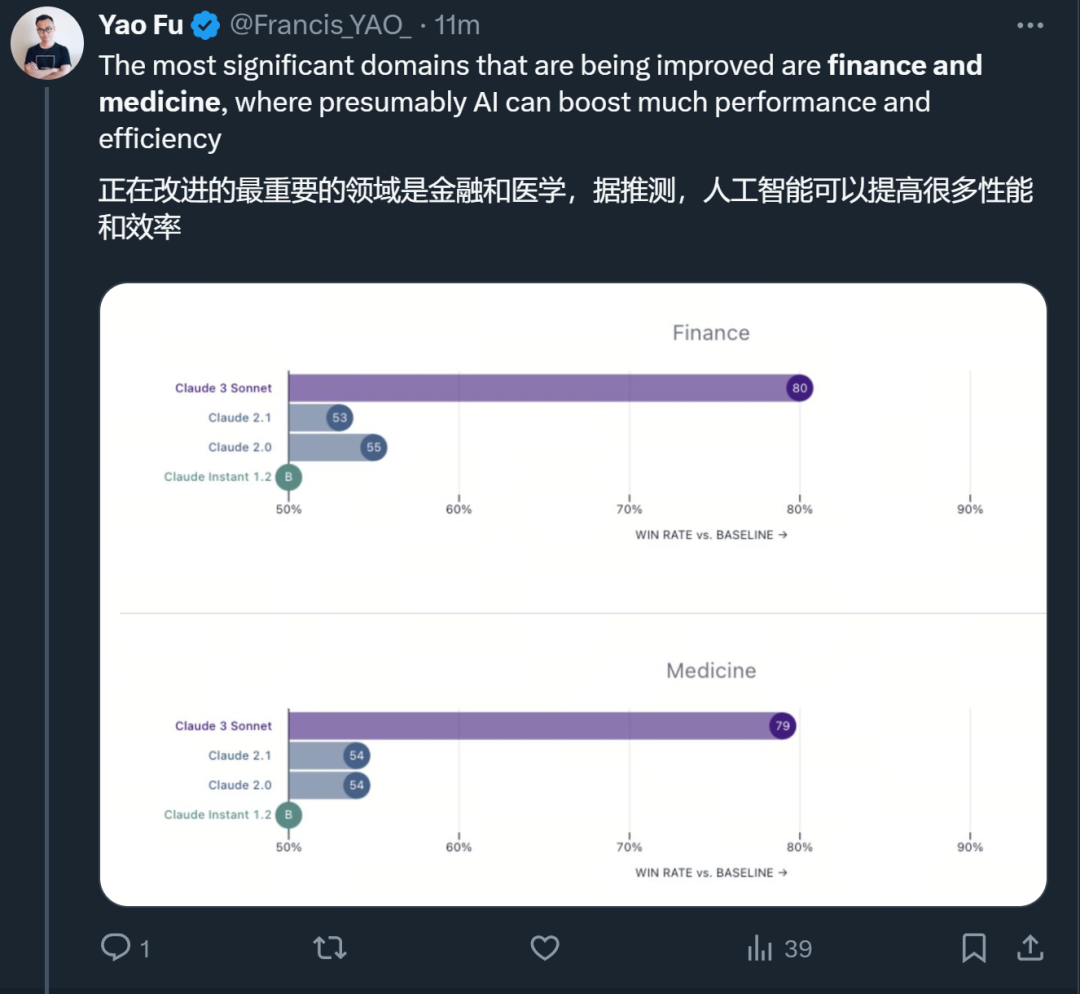
Par rapport au modèle précédent de Claude, les domaines de plus grande amélioration sont la finance et la médecine.
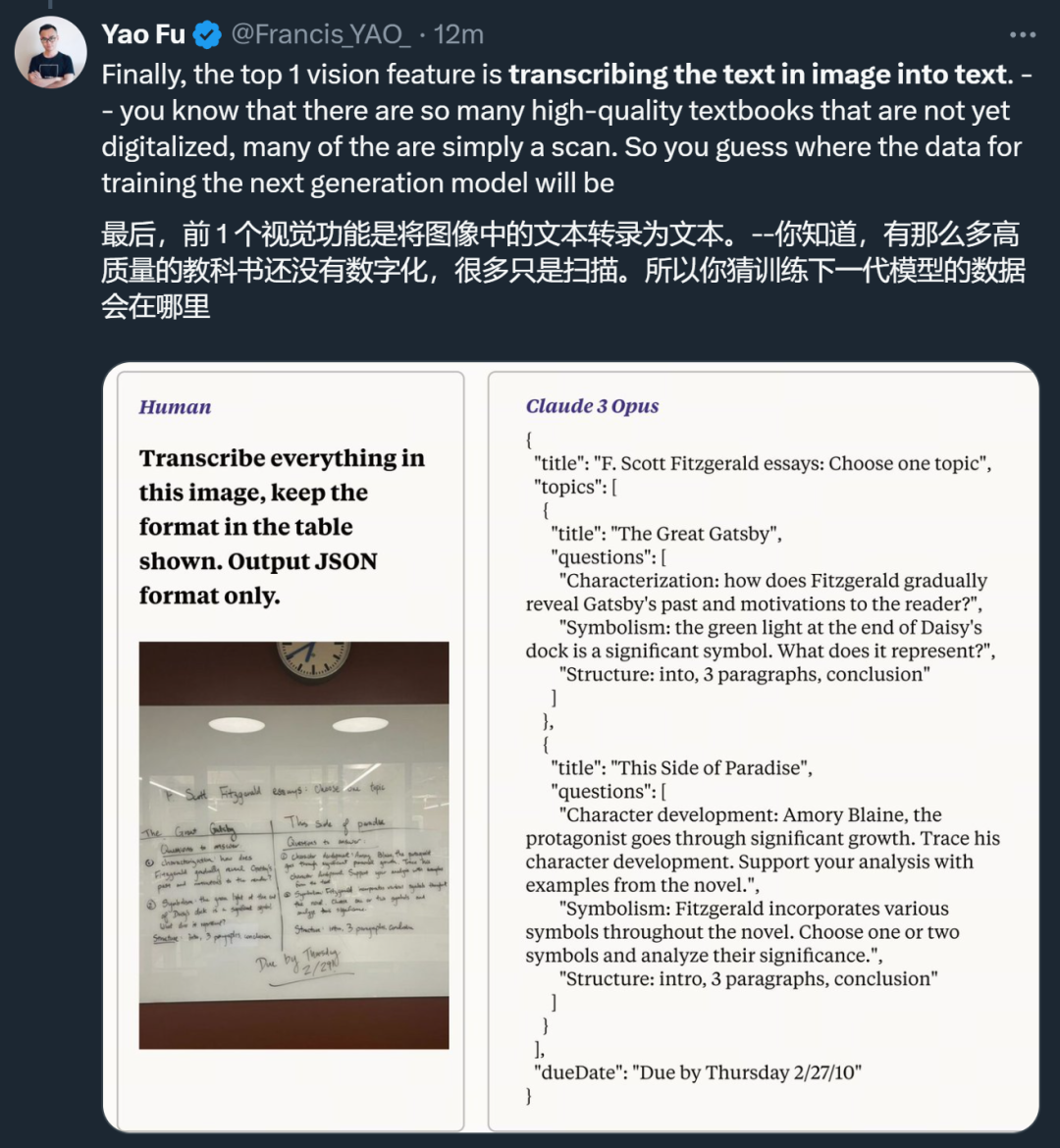
En termes de vision, les capacités visuelles d'OCR de Claude 3 font voir aux gens son énorme potentiel en matière de collecte de données.
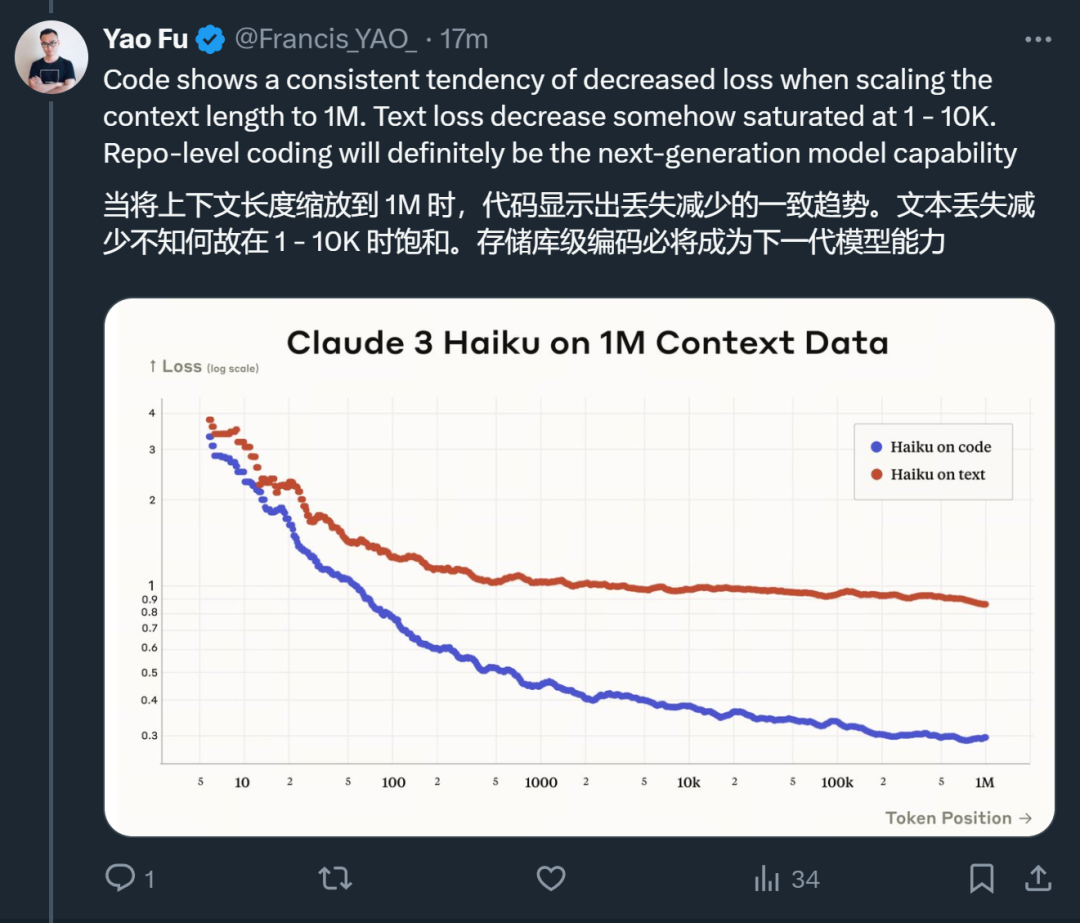
De plus, il a également découvert d'autres tendances :
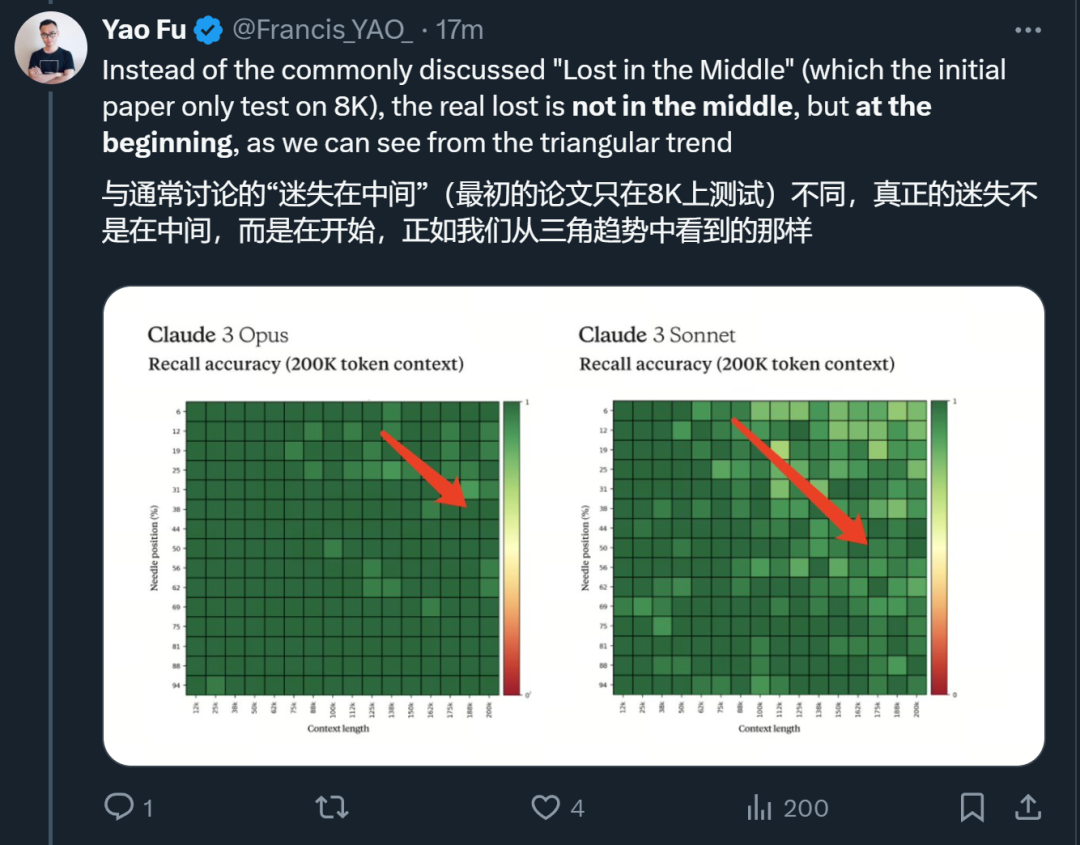 Adresse du blog : https://www.anthropic.com/news/claude-3-family
Adresse du blog : https://www.anthropic.com/news/claude-3-family
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!